
前言
2018年我写过一篇博客,叫:《一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD》,该文相当于梳理了2019年之前CV领域的典型视觉模型,比如
- 2014 R-CNN
- 2015 Fast R-CNN、Faster R-CNN
- 2016 YOLO、SSD
- 2017 Mask R-CNN、YOLOv2
- 2018 YOLOv3
随着2019 CenterNet的发布,特别是2020发布的DETR(End-to-End Object Detection with Transformers)之后,自此CV迎来了生成式下的多模态时代
- 2020年
5月 DETR
6月 DDPM(即众人口中常说的扩散模型diffusion model)
10月 DDIM、Vision Transformer - 2021年
1月 CLIP、DALL·E
3月 Swin Transformer
11月 MAE、Swin Transformer V2 - 2022年
1月 BLIP
4月 DALL·E 2
8月 Stable Diffusion、BEiT-3、Midjourney V3 - 2023年
1月 BLIP2
3月 Visual ChatGPT、GPT-4、Midjourney V5
4月 SAM(Segment Anything Model)
但看这些模型接二连三的横空出世,都不用说最后爆火的GPT4,便可知不少CV同学被卷的不行
说到GPT4,便不得不提ChatGPT,实在是太火了,改变了很多行业,使得国内外绝大部分公司的产品、服务都值得用LLM全部升级一遍(比如微软的365 Copilot、阿里所有产品、金山WPS等等)
而GPT4相比GPT3.5或GPT3最本质的改进就是增加了多模态的能力,使得ChatGPT很快就能支持图片的输入形式,从而达到图生文和文生图的效果,而AI绘画随着去年stable diffusion和Midjourney的推出,使得文生图火爆异常,各种游戏的角色设计、网上店铺的商品/页面设计都用上了AI绘画这样的工具,更有不少朋友利用AI绘画取得了不少的创收,省时省力还能赚钱,真香
但面对这么香的技术,其背后的一系列原理到底是什么呢,本文特从头开始,不只是简单的讲一下扩散模型的原理,而是在反复研读相关论文之后,准备把20年起相关的CV多模态模型全部梳理一遍,从VE、VAE、到ViT/Swin transformer、CLIP/BLIP,再到stable diffusion、GPT4,尽可能写透彻每一个模型的原理,就当2020年之后的CV视觉发展史了
过程中会尽可能写透彻每一个模型的原理,举个最简单的例子,网上介绍VAE的文章都太数学化(更怕那种表面正确其实关键的公式是错的误导人),如果更边推导边分析背后的理论意义(怎么来的 出发点是什么 为什么要这么做 这么做的意义是什么),则会更好理解,这就跟变介绍原理边coding实现 会更好理解、理解更深 一个道理
第一部分 编码器VE与变分自编码器VAE
1.1 AE:编码器(数据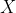 压缩为低维表示
压缩为低维表示 )-解码器(低维表示恢复为原始数据
)-解码器(低维表示恢复为原始数据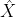 )架构
)架构
自编码器(Autoencoder,简称AE)是一种无监督学习的神经网络,用于学习输入数据的压缩表示。具体而言,可以将其分为两个部分:编码器和解码器

-
编码器:编码器是一个神经网络,负责将输入数据
-
解码器:解码器是另一个神经网络,负责将编码器生成的低维表示恢复为原始数据
从而最终完成这么一个过程:,而其训练目标即是最小化输入数据
与解码器重建数据
之间的差异,所以自编码器常用的一个损失函数为
这个自编码的意义在于
- 模型训练结束后,我们就可以认为编码
- 解码器只需要输入某些低维向量
来生成图片呢?
对于第二点,理论上可以这么做,但绝大多数随机生成的只会生成一些没有意义的噪声,之所以如此,原因在于没有显性的对
的分布
进行建模,我们并不知道哪些
能够生成有用的图片。而且我们用来训练
的数据是有限的,
可能只会对极有限的
有响应。而整个低维空间又是一个比较大的空间,如果只在这个空间上随机采样的话,我们自然不能指望总能恰好采样到能够生成有用的图片的
有问题自然便得探索对应的解决方案,而VAE(自变分编码器,Variational Autoencoders)则是在AE的基础上,显性的对的分布
进行建模(比如符合某种常见的概率分布),使得自编码器成为一个合格的生成模型
1.2 Variational AutoEncoder (VAE)
1.2.1 VAE:标数据的分布和目标分布尽量接近
VAE和GAN一样,都是从隐变量生成目标数据,具体而言,先用某种分布随机生成一组隐变量
(假设隐变量服从正态分布),然后这个
隐变量经过一个生成器生成一组数据
,具体如下图所示(本1.2节的部分图来自苏建林):

而VAE和GAN都希望这组生成数据的分布和目标分布
尽量接近,看似美好,但有两个问题
- 一方面,“尽量接近”并没有一个确定的关于
- 二方面,经过采样出来的每一个
,不一定对应着每一个原来的
,故最后没法直接最小化
实际是怎么做的呢,事实上,与自动编码器由编码器与解码器两部分构成相似,VAE利用两个神经网络建立两个概率密度分布模型:
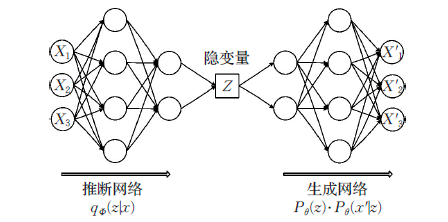
- 一个用于原始输入数据
的变分推断,生成隐变量
的变分概率分布
,称为推断网络
而VAE的核心就是,我们不仅假设是正态分布,而且假设每个
换言之,有个
,希望能够把从分布
而如何确定这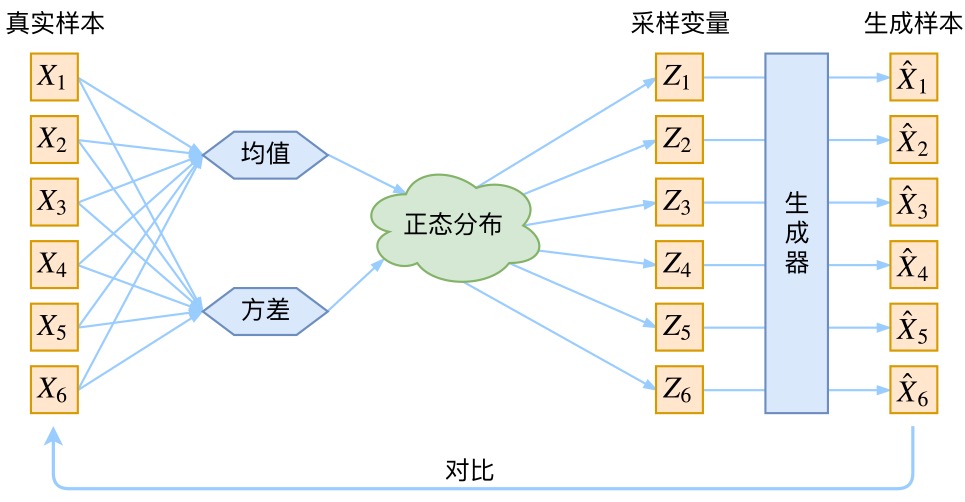
和方差
即可,故可通过已知的
具体可以构建两个神经网络,
去计算。值得一提的是,选择拟合
而不是直接拟合
,是因为
- 另一个根据生成的隐变量
,称为生成网络
因为已经学到了这,那接下来只需要最小化方差
就行
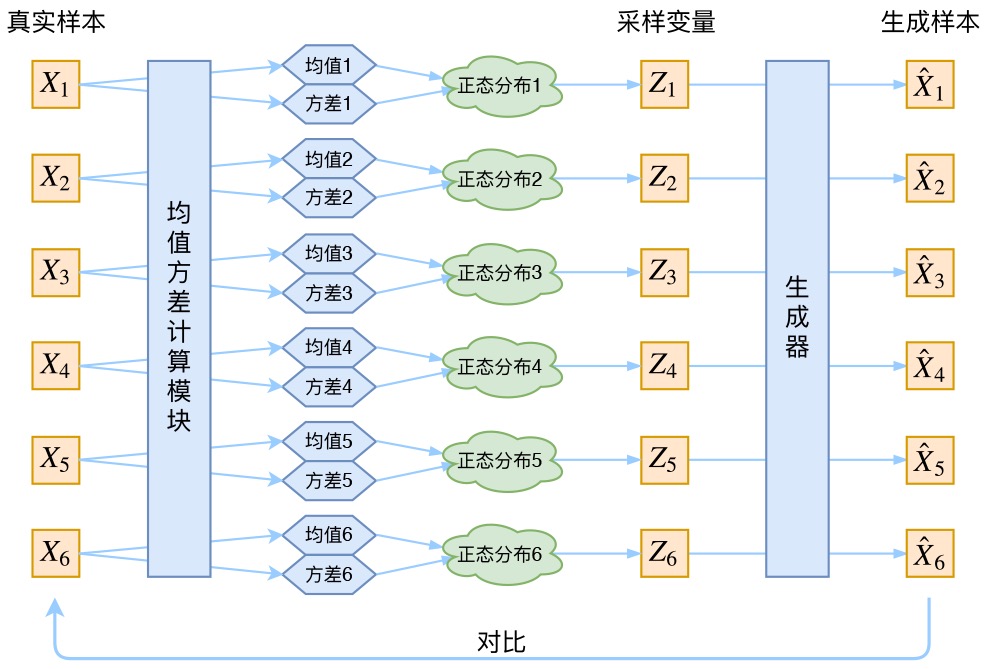
仔细理解的时候有没有发现一个问题?为什么在文章最开头,我们强调了没法直接比较 与
的分布,而在这里,我们认为可以直接比较这俩?注意,这里的
是专属于或针对于
的隐变量,那么和
本身就有对应关系,因此右边的蓝色方框内的“生成器”,是一一对应的生成。
另外,大家可以看到,均值和方差的计算本质上都是encoder。也就是说,VAE其实利用了两个encoder去分别学习均值和方差
1.2.2 VAE的Variational到底是个啥
这里还有一个非常重要的问题:由于我们通过最小化来训练右边的生成器,最终模型会逐渐使得
和
趋于一致。但是注意,因为
是重新随机采样过的,而不是直接通过均值和方差encoder学出来的,这个生成器的输入
是有噪声的
- 仔细思考一下,这个噪声的大小其实就用方差来度量。为了使得分布的学习尽量接近,我们希望噪声越小越好,所以我们会尽量使得方差趋于 0
- 但是方差不能为 0,因为我们还想要给模型一些训练难度。如果方差为 0,模型永远只需要学习高斯分布的均值,这样就丢失了随机性,VAE就变成AE了……这就是为什么VAE要在AE前面加一个Variational:我们希望方差能够持续存在,从而带来噪声!
- 那如何解决这个问题呢?其实保证有方差就行,但是VAE给出了一个优雅的答案:不仅需要保证有方差,还要让所有
趋于标准正态分布
,根据定义可知
这个式子的关键意义在于告诉我吗:如果所有
到此为止,我们可以把VAE进一步画成:
现在我们来回顾一下VAE到底做了啥。VAE在AE的基础上
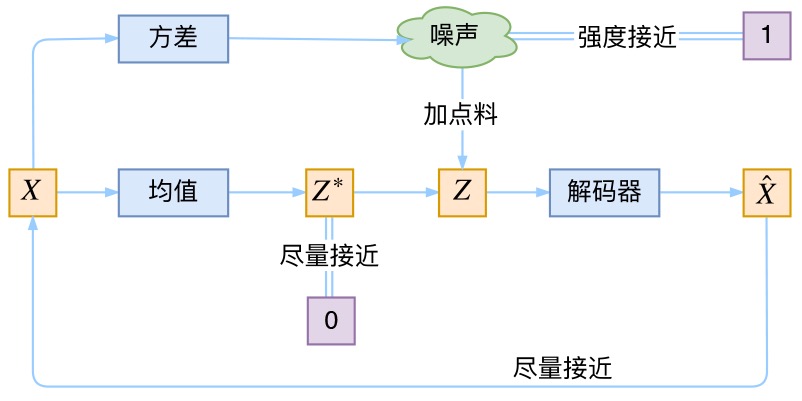
- 一方面,对均值的encoder添加高斯噪声(正态分布的随机采样),使得decoder(即生成器)有噪声鲁棒性
- 二方面,为了防止噪声消失,将所有
这样一来,当decoder训练的不好的时候,整个体系就可以降低噪声;当decoder逐渐拟合的时候,就会增加噪声
第二部分 扩散模型DDPM:Denoising Diffusion Probabilistic Models
2020年,UC Berkeley等人的Jonathan Ho等人通过论文《Denoising Diffusion Probabilistic Models》正式提出DDPM
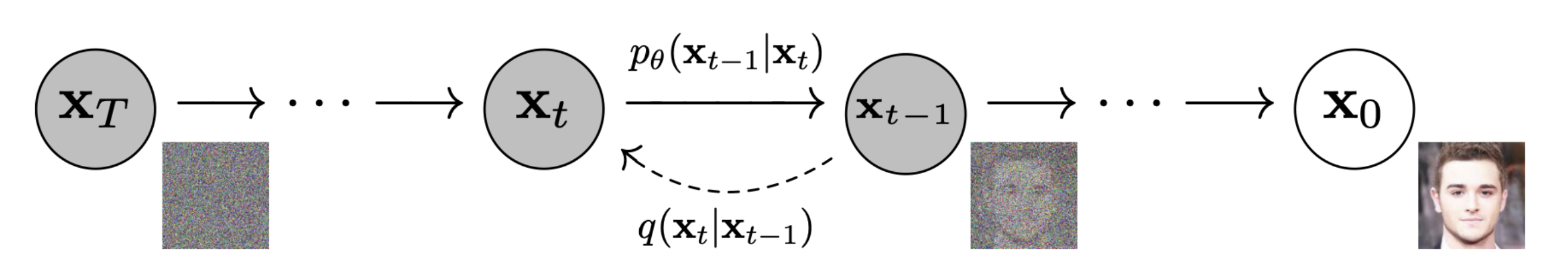
在写本文之前,我反复看了网上很多阐述DDPM的文章,实话说,一开始看到那种一上来就一堆公式的,起初确实看不下去,虽然后来 慢慢的都看得下去了,但如果对于一个初次接触DDPM的初学者来说,一上来一堆公式确实容易把人绕晕,但如果没有公式,则又没法透彻理解背后的算法步骤,两相权衡,本文将侧重算法每一步的剖析,而公式更多为解释算法原理而服务,说白了,侧重原理 其次公式,毕竟原理透彻了,公式也就自然而然的能写出来了
首先,明确DDPM的目标:作为一个生成式模型,其目标是从随机噪声直接生成图片,换言之,首先训练一个噪声估计模型,然后将输入随机噪声还原成图片),相当于就两个关键,一个是训练过程,一个是推理过程
- 训练过程:随机生成噪声
,经过
步将噪声扩散到输入原始图片
中,破坏后的图片
,学习破坏图片的预估噪声
,用L2 loss约束与
- 推理过程就输入噪声,经过预估噪声模型还原成图片
2.1 前向过程:通过高斯噪音随机加噪,相当于给图片打马赛克
前向过程(forward process)又称为扩散过程(diffusion process),简单理解就是对原始图片�0 通过逐步加高斯噪声变成 �� ,从而达到破坏图片的目的,如下图

DDPM的前向过程
用公式表示就是
(1)��=����−1+1−����−1
其中 {��}�=1� 是预先设定好的超参数,被称为Noise schedule,通常是一些列很小的值。 ��−1∼�(0,1) 是高斯噪声。由公式(1)迭代推导,可以直接得出 �0 到 �� 的公式(详细过程可见[2]),如下,
(2)��=��¯�0+1−��¯�
其中 ��¯=∏���� ,这是随Noise schedule设定好的超参数, �∼�(0,1) 也是一个高斯噪声。公式(1)或(2)就可以用来描述前向过程了,(1)用于将一张图片逐步破坏,(2)用于一步到位破坏。
2.2 反向过程(去噪)
反向过程就是通过估测噪声,多次迭代逐渐将被破坏的 �� 恢复成 �0 ,如下图

DDPM的反向过程
用公式表示就是
由于公式(2)中的真实噪声 � 在复原过程中不允许使用,因此DDPM的关键就是训练一个由 �� 和 � 估测噪声的模型 ��(��,�) ,其中 � 就是模型的训练参数, �� 也是一个高斯噪声 ��∼�(0,1) ,用于表示估测与实际的差距。在DDPM中,使用U-Net作为估测噪声的模型。
2.3 如何训练(获得噪声估计模型)
上文提到,DDPM的关键是训练 ��(��,�) 模型,使其预测的 �^ 与真实用于破坏的 � 相近,用L2距离刻画相近程度就好,因此我们的Loss就是如下公式。
训练过程如下图描述

DDPM训练过程
用原论文中的伪代码表示也很容易理解。

论文中的训练伪代码
这里有读者会有疑问,在训练过程中 ��(��,�) 表示的是从t到t-1时刻的噪声,而却用0到t的真实噪声 � 进行拟合,会不会有些不妥呢? 我的理解是0到t的真实噪声 � 只是指导方向,方向大概正确即可,后续用于生成时也不要求恢复出原图,只要能生成一个可看的图片即可,所以这样做是可以的。
2.4 如何使用(生成图片)
在得到噪声估测模型 ��(��,�) 后,想要生成模型就很简单了。从N(0,1)中随机生成一个噪声作为 �� ,然后再用该模型逐步从估测噪声,并用去噪公式逐渐恢复到 �0 即可,见如下伪代码。

论文中生成的伪代码
贴一些论文里生成的图片看一看,效果还是很惊艳的(论文实验的超参数T=1000, ��=1−0.02�� )。
//待更..怪我不一小心把本文发布出去了,本来一直在草稿里要修改个把星期的..
参考文献与推荐阅读
- 变分自编码器(一):原来是这么一回事
- ..
- 关于VAE的几篇文章:一文理解变分自编码器(VAE)、机器学习方法—优雅的模型(一):变分自编码器(VAE)、
- 苏剑林关于扩散模型的几篇文章:(一):DDPM = 拆楼 + 建楼、(二):DDPM = 自回归式VAE
- 知乎上关于扩散模型的几篇文章:全网最简单的扩散模型DDPM教程、
- 怎么理解今年 CV 比较火的扩散模型(DDPM)?
- 扩散模型是如何工作的:从0开始的数学原理
- What are Diffusion Models?
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/v_JULY_v/article/details/130361959

