
一、注册kaggle(需要科学上网)
https://www.kaggle.com/account/login?phase=startRegisterTab
二、登录kaggle
准备一个数据集
找到:“Account”->”Settings”,找到“API”下载
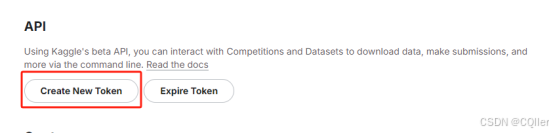
点击:“Create New API Token”
得到:“kaggle.json”得到“api_keys”
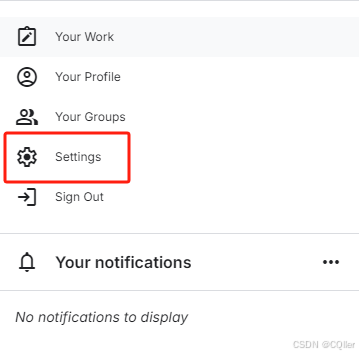
在Settings中找到token文件点击后下载
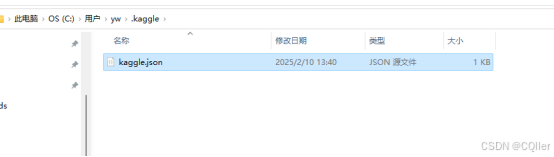
三、将kaggle.json放入指定目录
将下载的kaggle.json文件放入c盘.kaggle文件中
四、安装python依赖
python需要引入一些库才能进行模型的训练工作,
可参考《本地部署model scope魔搭大模型流程》有比较全的安装所需依赖步骤。
需要新引入以下库:
pip install kaggle
安装获取下载进度tqdm 库:pip install tqdm
音频依赖:pip install librosa
兼容更多视频和音频类型依赖:
pip install torch torchvision moviepy librosa numpy opencv-python
视频编辑库:
尝试更新pip和setuptools到最新版本,然后再次安装moviepy
pip install --upgrade pip setuptools
pip install moviepy
五、创建数据集目录
以训练视频安全审核模型为例,可修改数据集保存位置 base_dir 参数;
执行python脚本initializeDirectory.py创建数据集目录:
import os
# 基础目录
base_dir = 'E:\\dataset\\VideoReviewDataset'
def create_directories(base_dir, categories):
"""
根据给定的基础目录和类别列表创建相应的子目录结构。
:param base_dir: 基础目录路径
:param categories: 类别名称列表
"""
# 创建Normal下的子类别及其json和videos文件夹
normal_path = os.path.join(base_dir, "Normal")
if not os.path.exists(normal_path):
os.makedirs(normal_path)
for category in categories:
category_path = os.path.join(normal_path, category)
if not os.path.exists(category_path):
os.makedirs(category_path)
# 创建子目录 json 和 videos
for sub_dir in ['json', 'videos']:
full_path = os.path.join(category_path, sub_dir)
if not os.path.exists(full_path):
os.makedirs(full_path)
print(f"已创建目录: {full_path}")
else:
print(f"目录已存在: {full_path}")
# 在base_dir下也创建同样的7个子类别及其json和videos文件夹
for category in categories:
category_path = os.path.join(base_dir, category)
if not os.path.exists(category_path):
os.makedirs(category_path)
# 创建子目录 json 和 videos
for sub_dir in ['json', 'videos']:
full_path = os.path.join(category_path, sub_dir)
if not os.path.exists(full_path):
os.makedirs(full_path)
print(f"已创建目录: {full_path}")
else:
print(f"目录已存在: {full_path}")
# 在base_dir下创建model和log文件夹
for folder in ['model', 'log']:
folder_path = os.path.join(base_dir, folder)
if not os.path.exists(folder_path):
os.makedirs(folder_path)
print(f"已创建目录: {folder_path}")
else:
print(f"目录已存在: {folder_path}")
# Normal下要创建的子类别列表
sub_categories = ["Violent", "Pornographic", "RacialDiscrimination",
"HateSpeech", "PoliticalSensitive", "IllegalContent",
"CopyrightInfringement"]
# 调用函数创建目录结构
create_directories(base_dir, sub_categories)
print("所有目录创建完成!")脚本生成的目录结构如下:
E:\dataset\VideoReviewDataset\
├── Normal\
│ ├── Violent\
│ │ ├── videos\
│ │ └── json\
│ ├── Pornographic\
│ │ ├── videos\
│ │ └── json\
│ ├── RacialDiscrimination\
│ │ ├── videos\
│ │ └── json\
│ ├── HateSpeech\
│ │ ├── videos\
│ │ └── json\
│ ├── PoliticalSensitive\
│ │ ├── videos\
│ │ └── json\
│ ├── IllegalContent\
│ │ ├── videos\
│ │ └── json\
│ └── CopyrightInfringement\
│ ├── videos\
│ └── json\
├── Violent\
│ ├── videos\
│ └── json\
├── Pornographic\
│ ├── videos\
│ └── json\
├── RacialDiscrimination\
│ ├── videos\
│ └── json\
├── HateSpeech\
│ ├── videos\
│ └── json\
├── PoliticalSensitive\
│ ├── videos\
│ └── json\
├── IllegalContent\
│ ├── videos\
│ └── json\
├── CopyrightInfringement\
│ ├── videos\
│ └── json\
├── log\
└── model\六、下载数据集
可“调整常量定义参数”,指定数据集下载位置。
下载完成后需要将“正常视频”与json文件放入Normal文件夹的指定目录。
以及“违规视频”与json,放到他们对应的类别目录下。
可以先设置下python的缓存位置环境变量,默认为C盘(需要重启)
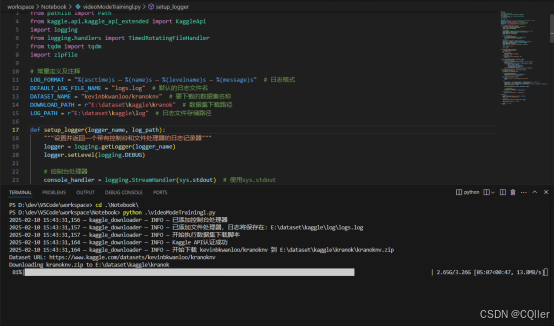
执行python脚本modelDatasetDown.py下载数据集:
import os
import sys
from pathlib import Path
from kaggle.api.kaggle_api_extended import KaggleApi
import logging
from logging.handlers import TimedRotatingFileHandler
from tqdm import tqdm
import zipfile
# 常量定义及注释
LOG_FORMAT = "%(asctime)s — %(name)s — %(levelname)s — %(message)s" # 日志格式
DEFAULT_LOG_FILE_NAME = "logs.log" # 默认的日志文件名
DATASET_NAME = "kevinbkwanloo/kranoknv" # 要下载的数据集名称
DOWNLOAD_PATH = r"E:\dataset\kaggle\data" # 数据集下载路径
LOG_PATH = r"E:\dataset\kaggle\log" # 日志文件存储路径
def setup_logger(logger_name, log_path):
"""设置并返回一个带有控制台和文件处理器的日志记录器"""
logger = logging.getLogger(logger_name)
logger.setLevel(logging.DEBUG)
# 控制台处理器
console_handler = logging.StreamHandler(sys.stdout) # 使用sys.stdout
console_handler.setFormatter(logging.Formatter(LOG_FORMAT))
logger.addHandler(console_handler)
logger.info("已添加控制台处理器")
# 检查并创建日志目录
if not Path(log_path).exists():
Path(log_path).mkdir(parents=True, exist_ok=True)
logger.info(f"创建日志目录: {log_path}")
# 文件处理器
log_file = Path(log_path) / DEFAULT_LOG_FILE_NAME
file_handler = TimedRotatingFileHandler(log_file, when='midnight')
file_handler.setFormatter(logging.Formatter(LOG_FORMAT))
logger.addHandler(file_handler)
logger.info(f"已添加文件处理器,日志将保存在: {log_file}")
logger.propagate = False
return logger
def authenticate_kaggle_api(logger):
"""认证Kaggle API并返回API实例"""
api = KaggleApi()
try:
api.authenticate()
logger.info("Kaggle API认证成功")
return api
except Exception as e:
logger.error(f"Kaggle API认证失败: {e}")
return None
def unzip_with_progress(zip_path, extract_to, logger):
"""使用tqdm显示解压进度"""
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
total_size = sum([zinfo.file_size for zinfo in zip_ref.filelist])
extracted_size = 0
with tqdm(total=total_size, unit='iB', unit_scale=True) as pbar:
for zinfo in zip_ref.filelist:
extracted_size += zinfo.file_size
zip_ref.extract(zinfo, extract_to)
pbar.update(zinfo.file_size)
logger.info(f"解压完成,总共解压了 {extracted_size} 字节的数据.")
def download_dataset(dataset_name, download_path, logger):
"""从Kaggle下载指定数据集"""
download_path = Path(download_path)
if not download_path.exists():
download_path.mkdir(parents=True, exist_ok=True)
logger.info(f"创建目录: {download_path}")
api = authenticate_kaggle_api(logger)
if not api:
logger.error("无法继续下载,因为Kaggle API未通过认证")
return
try:
temp_zip_path = str(Path(download_path) / f"{dataset_name.split('/')[-1]}.zip")
logger.info(f"开始下载 {dataset_name} 到 {temp_zip_path}")
api.dataset_download_files(dataset_name, path=download_path, force=True, quiet=False, unzip=False)
logger.info("下载完成,开始解压")
unzip_with_progress(temp_zip_path, download_path, logger)
# 删除临时ZIP文件
os.remove(temp_zip_path)
logger.info(f"删除临时ZIP文件: {temp_zip_path}")
except Exception as e:
logger.error(f"下载或解压过程中出现错误:{e}")
def main():
"""主函数"""
logger = setup_logger("kaggle_downloader", LOG_PATH)
logger.info("开始执行数据集下载脚本")
# 下载数据集
download_dataset(DATASET_NAME, DOWNLOAD_PATH, logger)
logger.info("数据集下载脚本执行完毕")
if __name__ == "__main__":
main()以下为脚本下载数据集时的执行过程展示:
七、训练模型
以下为脚本完成训练模型任务的执行结果展示:
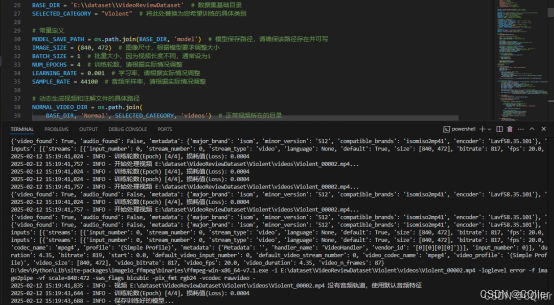
训练前需设置训练目标的基础参数:
# 训练模式开关:
# 0训练单个类别的模型保存为{SELECTED_CATEGORY}_Video_Model.pth;
# 1训练合并所有类别的模型并保存为Video_Model.pth
TRAIN_COMBINED_MODEL = 1
# 训练类别:
SELECTED_CATEGORY = "Violent" # 将此处替换为您希望训练的具体类别
该脚本会根据TRAIN_COMBINED_MODEL训练模式参数判断:
1:训练合并所有类别的模型并保存为Video_Model.pth,
0:训练单个类别的模型保存为{SELECTED_CATEGORY}_Video_Model.pth,
SELECTED_CATEGORY为指定需要训练的类型。
使用步骤5创建的文件夹中的数据集对模型进行训练,每一种违规类型,会轮询执行该类型下的正常视频与违规视频进行模型训练。在定义常量中,可设置调整类型、训练轮数、视频帧大小、模型model保存位置等参数。以满足不同的训练需求。
TRAIN_COMBINED_MODEL = 0 每一种类型会在model文件夹中生成一个.pth文件。同名的.pth文件下次训练时,会加载原来模型的权重,进行增量训练覆盖源文件。
最终生成7个.pth文件针对不同违规类型的模型,可使用多个模型实现对一个视频的审核、标注等工作。
TRAIN_COMBINED_MODEL = 1生成统一的.pth文件。同名的.pth文件下次训练时,会加载原来模型的权重,进行增量训练覆盖源文件。最终生成1个.pth文件,通过调用此文件完成违规判断。
数据集下载完成后,执行traininglModel.py脚本
示例:训练暴恐内容类型模型:
import os
import json
import cv2
import torch
import librosa
import logging
import numpy as np
from pathlib import Path
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
from moviepy import VideoFileClip
# 定义类别映射,每个键值对表示一个视频分类及其对应的标签编号
CLASS_LABELS = {
"Normal": 0, # 正常内容
"Violent": 1, # 暴恐内容
"Pornographic": 2, # 涉黄内容
"RacialDiscrimination": 3, # 种族歧视
"HateSpeech": 4, # 仇恨言论
"PoliticalSensitive": 5, # 政治敏感词汇
"IllegalContent": 6, # 法律禁止的内容
"CopyrightInfringement": 7 # 版权侵犯和盗版
}
# 训练模式开关:
# 0训练单个类别的模型保存为{SELECTED_CATEGORY}_Video_Model.pth;
# 1训练合并所有类别的模型并保存为Video_Model.pth
TRAIN_COMBINED_MODEL = 0
# 训练类别:
SELECTED_CATEGORY = "Violent" # 将此处替换为您希望训练的具体类别
BASE_DIR = 'E:\\dataset\\VideoReviewDataset' # 数据集基础目录
MODEL_SAVE_PATH = os.path.join(BASE_DIR, 'model') # 模型保存路径,请确保该路径存在并可写
IMAGE_SIZE = (840, 472) # 图像尺寸,根据模型要求调整大小
BATCH_SIZE = 1 # 批量大小,因为视频长度不同,通常设为1
NUM_EPOCHS = 1 # 训练轮数,请根据实际情况调整
LEARNING_RATE = 0.001 # 学习率,请根据实际情况调整
SAMPLE_RATE = 44100 # 音频采样率,请根据实际情况调整
def setup_logging(log_path='E:\\dataset\\VideoReviewDataset\\log'):
"""
配置日志记录器以同时输出到控制台和文件。
"""
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_formatter = logging.Formatter(
"%(asctime)s - %(levelname)s - %(message)s")
console_handler.setFormatter(console_formatter)
log_file_path = Path(log_path) / "log.log"
file_handler = logging.handlers.TimedRotatingFileHandler(
log_file_path, when='midnight', backupCount=7)
file_handler.setLevel(logging.INFO)
file_formatter = logging.Formatter(
"%(asctime)s - %(levelname)s - %(message)s")
file_handler.setFormatter(file_formatter)
if not Path(log_path).exists():
Path(log_path).mkdir(parents=True, exist_ok=True)
if logger.hasHandlers():
logger.handlers.clear()
logger.addHandler(console_handler)
logger.addHandler(file_handler)
setup_logging()
class VideoReviewDataset(Dataset):
def __init__(self, base_dir, category, transform=None):
self.base_dir = base_dir
self.category = category
self.transform = transform
self.supported_video_extensions = ['.mp4', '.avi', '.mkv']
self.videos, self.labels = [], []
if TRAIN_COMBINED_MODEL:
for cat in CLASS_LABELS.keys():
video_dir = os.path.join(base_dir, cat, 'videos')
annotation_dir = os.path.join(base_dir, cat, 'json')
if os.path.exists(video_dir): # 确保路径存在
videos = [os.path.join(video_dir, v) for v in os.listdir(video_dir)
if os.path.splitext(v)[1].lower() in self.supported_video_extensions]
annotations = [os.path.join(
annotation_dir, f"{os.path.basename(video).split('.')[0]}.json") for video in videos]
label = CLASS_LABELS[cat] # 使用顶级类别的标签
self.videos.extend(videos)
self.labels.extend([label]*len(videos))
else:
video_dirs = [
os.path.join(self.base_dir, "Normal", self.category, 'videos'),
os.path.join(self.base_dir, self.category, 'videos')
]
for video_dir in video_dirs:
if os.path.exists(video_dir):
videos = [os.path.join(video_dir, v) for v in os.listdir(video_dir)
if os.path.splitext(v)[1].lower() in self.supported_video_extensions]
self.videos.extend(videos)
self.labels.extend(
[CLASS_LABELS[self.category]] * len(videos))
def extract_audio_features(self, video_path):
try:
with VideoFileClip(video_path) as video:
if video.audio is None:
return None
audio = video.audio.to_soundarray()
mfccs = librosa.feature.mfcc(
y=audio.mean(axis=1), sr=SAMPLE_RATE, n_mfcc=13)
return np.mean(mfccs.T, axis=0).astype(np.float32)
except Exception as e:
logging.error(f"Error processing {video_path}: {e}")
return None
def __len__(self):
return len(self.videos)
def __getitem__(self, idx):
video_path = self.videos[idx]
video_label = self.labels[idx]
frames = []
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
if self.transform:
frame = self.transform(frame)
frames.append(frame)
cap.release()
audio_features = self.extract_audio_features(video_path)
# 调整标签以适应二分类情况
if not TRAIN_COMBINED_MODEL:
video_label = 1 if video_label == CLASS_LABELS[self.category] else 0
return torch.stack(frames), torch.tensor(audio_features, dtype=torch.float32) if audio_features is not None else torch.zeros(13, dtype=torch.float32), torch.tensor([video_label], dtype=torch.long)
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor(),
])
def custom_collate(batch):
frames_batch, audio_features_batch, labels_batch = [], [], []
for frames, audio_features, label in batch:
frames_batch.append(frames)
audio_features_batch.append(
audio_features if audio_features is not None else torch.zeros(13, dtype=torch.float32))
labels_batch.append(label)
return torch.stack(frames_batch), torch.stack(audio_features_batch), torch.tensor(labels_batch)
if TRAIN_COMBINED_MODEL:
dataset = VideoReviewDataset(
BASE_DIR, SELECTED_CATEGORY, transform=transform)
MODEL_NAME = 'Video_Model.pth'
else:
dataset = VideoReviewDataset(
BASE_DIR, SELECTED_CATEGORY, transform=transform)
MODEL_NAME = f'{SELECTED_CATEGORY}_Video_Model.pth'
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=custom_collate)
# 根据是否是组合模型来决定输出层的类别数量
num_classes = 2 if not TRAIN_COMBINED_MODEL else len(CLASS_LABELS)
model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
model.fc = torch.nn.Identity()
final_fc = torch.nn.Linear(2048 + 13, num_classes)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
list(model.parameters()) + list(final_fc.parameters()), lr=LEARNING_RATE)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if os.path.exists(os.path.join(MODEL_SAVE_PATH, MODEL_NAME)):
logging.info("正在加载已有模型...")
checkpoint = torch.load(os.path.join(
MODEL_SAVE_PATH, MODEL_NAME), map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
if TRAIN_COMBINED_MODEL:
final_fc.load_state_dict(checkpoint['final_fc_state_dict'])
model.to(device)
final_fc.to(device)
for epoch in range(NUM_EPOCHS):
logging.info(f"开始第 {epoch+1}/{NUM_EPOCHS} 轮训练...")
for inputs, audio_features, labels in dataloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
video_outputs = model(inputs.squeeze(0).mean(dim=0).unsqueeze(0))
video_outputs = video_outputs.view(1, -1)
if audio_features is not None:
audio_features = audio_features.to(device)
audio_features = audio_features.squeeze(0)
combined_features = torch.cat(
[video_outputs, audio_features.unsqueeze(0)], dim=-1)
else:
combined_features = video_outputs
labels = labels.view(-1)
outputs = final_fc(combined_features)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
logging.info(
f'训练轮数(Epoch) [{epoch+1}/{NUM_EPOCHS}], 损耗值(Loss): {loss.item():.4f}')
logging.info("保存训练好的模型...")
torch.save({
'model_state_dict': model.state_dict(),
'final_fc_state_dict': final_fc.state_dict(),
}, os.path.join(MODEL_SAVE_PATH, MODEL_NAME))PS:目前只开发了“暴恐类型”的训练示例demo,想法是将解析视频、音频部分的代码封装起来。以应对数据集格式不同需要解析的方法不同等问题,每增加其它的格式数据集时,开发新的解析脚本,实现插拔式的解析训练。
7钟不同类型最终训练为一个Model的.pth文件,这样可以虽然审核视频的精确性会有所下降,但会节省大量审核视频的计算时间。
如果采用7个.pth文件的方式,可针对不同应用场景组合使用模型,并且对模型的训练可以有一定的针对性。但是会增加结果计算的复杂度,对部署和启动环境的硬件需求也会增加。具体需要根据场景,采用不同的解决方案。
八、使用.pth文件的审核方法封装
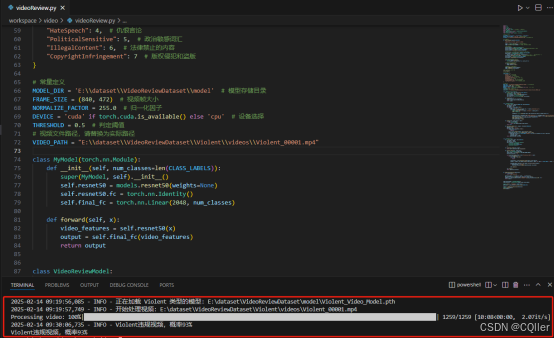
加载训练好的.pth模型对视频逐一帧解析,返回推理结果:
import os
import cv2
import torch
import numpy as np
from tqdm import tqdm # 导入tqdm用于进度条展示
import logging
from logging.handlers import TimedRotatingFileHandler
from pathlib import Path
from torchvision import models, transforms
# 日志格式定义
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s"
DEFAULT_LOG_FILE_NAME = "log.log" # 默认日志文件名
LOG_PATH = "E:\\dataset\\VideoReviewDataset\\log" # 日志存储路径
# 初始化日志
def setup_logging(log_path=LOG_PATH):
"""
配置日志记录器以同时输出到控制台和文件。
"""
logger = logging.getLogger() # 获取根日志记录器
logger.setLevel(logging.DEBUG) # 设置最低日志级别为DEBUG
# 控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO) # 控制台处理器的日志级别设为INFO
console_formatter = logging.Formatter(LOG_FORMAT)
console_handler.setFormatter(console_formatter)
# 文件处理器,使用TimedRotatingFileHandler实现按时间轮转
log_file_path = Path(log_path) / DEFAULT_LOG_FILE_NAME
file_handler = TimedRotatingFileHandler(
log_file_path, when='midnight', backupCount=7) # 每天轮转一次,并保留7个备份
file_handler.setLevel(logging.INFO) # 文件处理器的日志级别设为INFO
file_formatter = logging.Formatter(LOG_FORMAT)
file_handler.setFormatter(file_formatter)
# 如果日志目录不存在,则创建
if not Path(log_path).exists():
Path(log_path).mkdir(parents=True, exist_ok=True)
# 清除可能存在的默认处理器
if logger.hasHandlers():
logger.handlers.clear()
# 将处理器添加到日志记录器
logger.addHandler(console_handler)
logger.addHandler(file_handler)
# 调用上述函数进行日志配置
setup_logging()
# 定义类别映射
CLASS_LABELS = {
"Normal": 0, # 正常内容
"Violent": 1, # 暴恐内容
"Pornographic": 2, # 涉黄内容
"RacialDiscrimination": 3, # 种族歧视
"HateSpeech": 4, # 仇恨言论
"PoliticalSensitive": 5, # 政治敏感词汇
"IllegalContent": 6, # 法律禁止的内容
"CopyrightInfringement": 7 # 版权侵犯和盗版
}
# 常量定义
MODEL_DIR = 'E:\\dataset\\VideoReviewDataset\\model' # 模型存储目录
FRAME_SIZE = (840, 472) # 视频帧大小
NORMALIZE_FACTOR = 255.0 # 归一化因子
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu' # 设备选择
THRESHOLD = 0.5 # 判定阈值
# 视频文件路径,请替换为实际路径
VIDEO_PATH = "E:\\dataset\\VideoReviewDataset\\Violent\\videos\\Violent_00001.mp4"
class MyModel(torch.nn.Module):
def __init__(self, num_classes=len(CLASS_LABELS)):
super(MyModel, self).__init__()
self.resnet50 = models.resnet50(weights=None)
self.resnet50.fc = torch.nn.Identity()
self.final_fc = torch.nn.Linear(2048, num_classes)
def forward(self, x):
video_features = self.resnet50(x)
output = self.final_fc(video_features)
return output
class VideoReviewModel:
def __init__(self, model_dir=MODEL_DIR, device=DEVICE):
self.device = device
self.models = {}
for label in CLASS_LABELS.keys():
if label != 'Normal':
model_path = os.path.join(model_dir, f'{label}_Video_Model.pth')
if os.path.exists(model_path):
logging.info(f"正在加载 {label} 类型的模型: {model_path}")
model = MyModel()
checkpoint = torch.load(model_path, map_location=self.device, weights_only=True)
model_state_dict = checkpoint.get('model_state_dict') or checkpoint.get('final_fc_state_dict', checkpoint)
filtered_state_dict = {k: v for k, v in model_state_dict.items() if k in model.state_dict()}
model.load_state_dict(filtered_state_dict, strict=False)
model.to(device).eval()
self.models[label] = model
def predict(self, input_tensor, label):
if label in self.models:
with torch.no_grad():
return self.models[label](input_tensor)
return None
def interpret_outputs(self, outputs, threshold=THRESHOLD):
max_prob = 0.0
detected_label = "Normal"
for label, output in outputs.items():
if output is None:
continue
prob = torch.softmax(output, dim=1)[0].max().item()
predicted_class_idx = torch.argmax(output, dim=1).item()
if predicted_class_idx != CLASS_LABELS["Normal"] and prob >= threshold and prob > max_prob:
max_prob = prob
detected_label = label
return detected_label, max_prob
class VideoProcessor:
def __init__(self, model, device=DEVICE):
self.model = model
self.device = device
self.transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(FRAME_SIZE),
transforms.ToTensor(),
])
def preprocess_frame(self, frame):
return self.transform(frame).unsqueeze(0)
def process_video(self, video_path):
cap = cv2.VideoCapture(video_path)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
detected_violations = []
with tqdm(total=total_frames, desc="Processing video") as pbar:
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame_tensor = self.preprocess_frame(frame).to(self.device)
outputs = {label: self.model.predict(frame_tensor, label) for label in CLASS_LABELS if label != 'Normal'}
detected_label, max_prob = self.model.interpret_outputs(outputs)
if detected_label != "Normal":
detected_violations.append((detected_label, max_prob))
pbar.update(1)
cap.release()
return detected_violations
def summarize_predictions(detections):
if not detections:
return "视频为正常内容"
detected_labels = set([label for label, _ in detections])
max_prob_detection = max(detections, key=lambda item: item[1])
summary = f"{max_prob_detection[0]}违规视频,概率{max_prob_detection[1]*100:.0f}%"
return summary
video_review_model = VideoReviewModel()
video_processor = VideoProcessor(model=video_review_model)
logging.info(f"开始处理视频: {VIDEO_PATH}")
detections = video_processor.process_video(VIDEO_PATH)
summary = summarize_predictions(detections)
logging.info(summary)
print(summary)九、调用接口进行视频审核
封装一个接口测试下,有具体业务再进行调整。GPU性能越好,推理速度也可以增加。
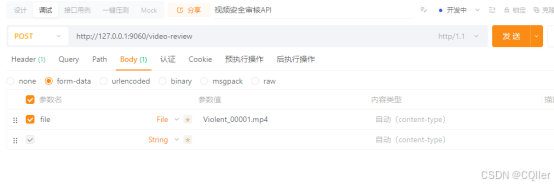
from flask import Flask, request, jsonify, send_from_directory
import os
import cv2
import torch
import numpy as np
from tqdm import tqdm # 导入tqdm用于进度条展示
import logging
from logging.handlers import TimedRotatingFileHandler
from pathlib import Path
from torchvision import models, transforms
# 日志格式定义
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s"
DEFAULT_LOG_FILE_NAME = "log.log" # 默认日志文件名
LOG_PATH = "E:\\dataset\\VideoReviewDataset\\log" # 日志存储路径
# 初始化日志
def setup_logging(log_path=LOG_PATH):
"""
配置日志记录器以同时输出到控制台和文件。
"""
logger = logging.getLogger() # 获取根日志记录器
logger.setLevel(logging.DEBUG) # 设置最低日志级别为DEBUG
# 控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO) # 控制台处理器的日志级别设为INFO
console_formatter = logging.Formatter(LOG_FORMAT)
console_handler.setFormatter(console_formatter)
# 文件处理器,使用TimedRotatingFileHandler实现按时间轮转
log_file_path = Path(log_path) / DEFAULT_LOG_FILE_NAME
file_handler = TimedRotatingFileHandler(
log_file_path, when='midnight', backupCount=7) # 每天轮转一次,并保留7个备份
file_handler.setLevel(logging.INFO) # 文件处理器的日志级别设为INFO
file_formatter = logging.Formatter(LOG_FORMAT)
file_handler.setFormatter(file_formatter)
# 如果日志目录不存在,则创建
if not Path(log_path).exists():
Path(log_path).mkdir(parents=True, exist_ok=True)
# 清除可能存在的默认处理器
if logger.hasHandlers():
logger.handlers.clear()
# 将处理器添加到日志记录器
logger.addHandler(console_handler)
logger.addHandler(file_handler)
setup_logging()
# 定义类别映射
CLASS_LABELS = {
"Normal": 0, # 正常内容
"Violent": 1, # 暴恐内容
"Pornographic": 2, # 涉黄内容
"RacialDiscrimination": 3, # 种族歧视
"HateSpeech": 4, # 仇恨言论
"PoliticalSensitive": 5, # 政治敏感词汇
"IllegalContent": 6, # 法律禁止的内容
"CopyrightInfringement": 7 # 版权侵犯和盗版
}
# 常量定义
MODEL_DIR = 'E:\\dataset\\VideoReviewDataset\\model' # 模型存储目录
FRAME_SIZE = (840, 472) # 视频帧大小
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu' # 设备选择
THRESHOLD = 0.5 # 判定阈值
class MyModel(torch.nn.Module):
def __init__(self, num_classes=len(CLASS_LABELS)):
super(MyModel, self).__init__()
self.resnet50 = models.resnet50(weights=None) # 使用ResNet-50架构,不预加载权重
self.resnet50.fc = torch.nn.Identity() # 替换最后的全连接层为Identity,以便自定义
self.final_fc = torch.nn.Linear(2048, num_classes) # 自定义的全连接层
def forward(self, x):
video_features = self.resnet50(x)
output = self.final_fc(video_features)
return output
class VideoReviewModel:
def __init__(self, model_dir=MODEL_DIR, device=DEVICE):
self.device = device
self.models = {}
for label in CLASS_LABELS.keys():
if label != 'Normal':
model_path = os.path.join(model_dir, f'{label}_Video_Model.pth')
if os.path.exists(model_path):
logging.info(f"正在加载 {label} 类型的模型: {model_path}")
model = MyModel()
# 为了解决潜在的警告或错误,确保map_location和权重加载正确
checkpoint = torch.load(model_path, map_location=self.device, weights_only=True)
# 确保只加载与模型状态字典匹配的部分
model_state_dict = checkpoint.get('model_state_dict') or checkpoint
filtered_state_dict = {k: v for k, v in model_state_dict.items() if k in model.state_dict()}
model.load_state_dict(filtered_state_dict, strict=False)
model.to(self.device).eval() # 明确使用self.device
self.models[label] = model
def predict(self, input_tensor, label):
if label in self.models:
with torch.no_grad():
return self.models[label](input_tensor)
return None
def interpret_outputs(self, outputs, threshold=THRESHOLD):
max_prob = 0.0
detected_label = "Normal"
for label, output in outputs.items():
if output is None:
continue
prob = torch.softmax(output, dim=1)[0].max().item()
predicted_class_idx = torch.argmax(output, dim=1).item()
if predicted_class_idx != CLASS_LABELS["Normal"] and prob >= threshold and prob > max_prob:
max_prob = prob
detected_label = label
return detected_label, max_prob
class VideoProcessor:
def __init__(self, model, device=DEVICE):
self.model = model
self.device = device
self.transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(FRAME_SIZE),
transforms.ToTensor(),
])
def preprocess_frame(self, frame):
return self.transform(frame).unsqueeze(0)
def process_video(self, video_path):
cap = cv2.VideoCapture(video_path)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
detected_violations = []
with tqdm(total=total_frames, desc="Processing frames", unit="frame") as pbar:
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame_tensor = self.preprocess_frame(frame).to(self.device)
outputs = {label: self.model.predict(frame_tensor, label) for label in CLASS_LABELS if label != 'Normal'}
detected_label, max_prob = self.model.interpret_outputs(outputs)
if detected_label != "Normal":
detected_violations.append((detected_label, max_prob))
pbar.update(1) # 更新进度条
cap.release()
return detected_violations
def summarize_predictions(detections):
if not detections:
return "正常内容"
detected_labels = set([label for label, _ in detections])
max_prob_detection = max(detections, key=lambda item: item[1])
summary = f"{max_prob_detection[0]}违规,概率{max_prob_detection[1]*100:.0f}%"
return summary
app = Flask(__name__)
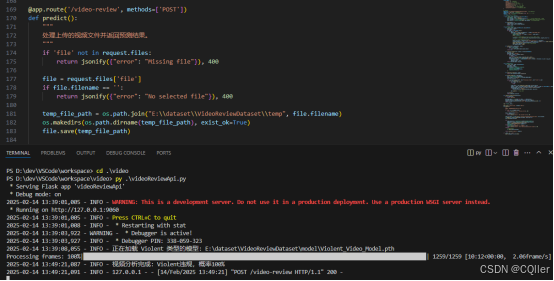
@app.route('/video-review', methods=['POST'])
def predict():
"""
处理上传的视频文件并返回预测结果。
"""
if 'file' not in request.files:
return jsonify({"error": "Missing file"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "No selected file"}), 400
temp_file_path = os.path.join("E:\\dataset\\VideoReviewDataset\\temp", file.filename)
os.makedirs(os.path.dirname(temp_file_path), exist_ok=True)
file.save(temp_file_path)
try:
video_processor = VideoProcessor(model=VideoReviewModel())
detections = video_processor.process_video(temp_file_path)
summary = summarize_predictions(detections)
logging.info(f"视频分析完成: {summary}")
except Exception as e:
logging.error(f"视频处理过程中发生错误: {e}")
return jsonify({"error": "Error during processing the video"}), 500
finally:
# 清理临时文件
os.remove(temp_file_path)
return jsonify({"summary": summary})
if __name__ == '__main__':
app.run(debug=True, port=9060)转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。

