
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
Python二手房推荐系统:Django+Scrapy+Echarts 协同过滤可视化毕业设计
1、项目介绍
技术栈:Python语言、Django框架、Scrapy爬虫框架、Echarts可视化、基于物品的协同过滤推荐、基于用户的协同过滤推荐、链家二手房数据、HTML
功能:用户登录注册、后台管理、房源推荐、数据对比、房源数据可视化分析
2、项目界面
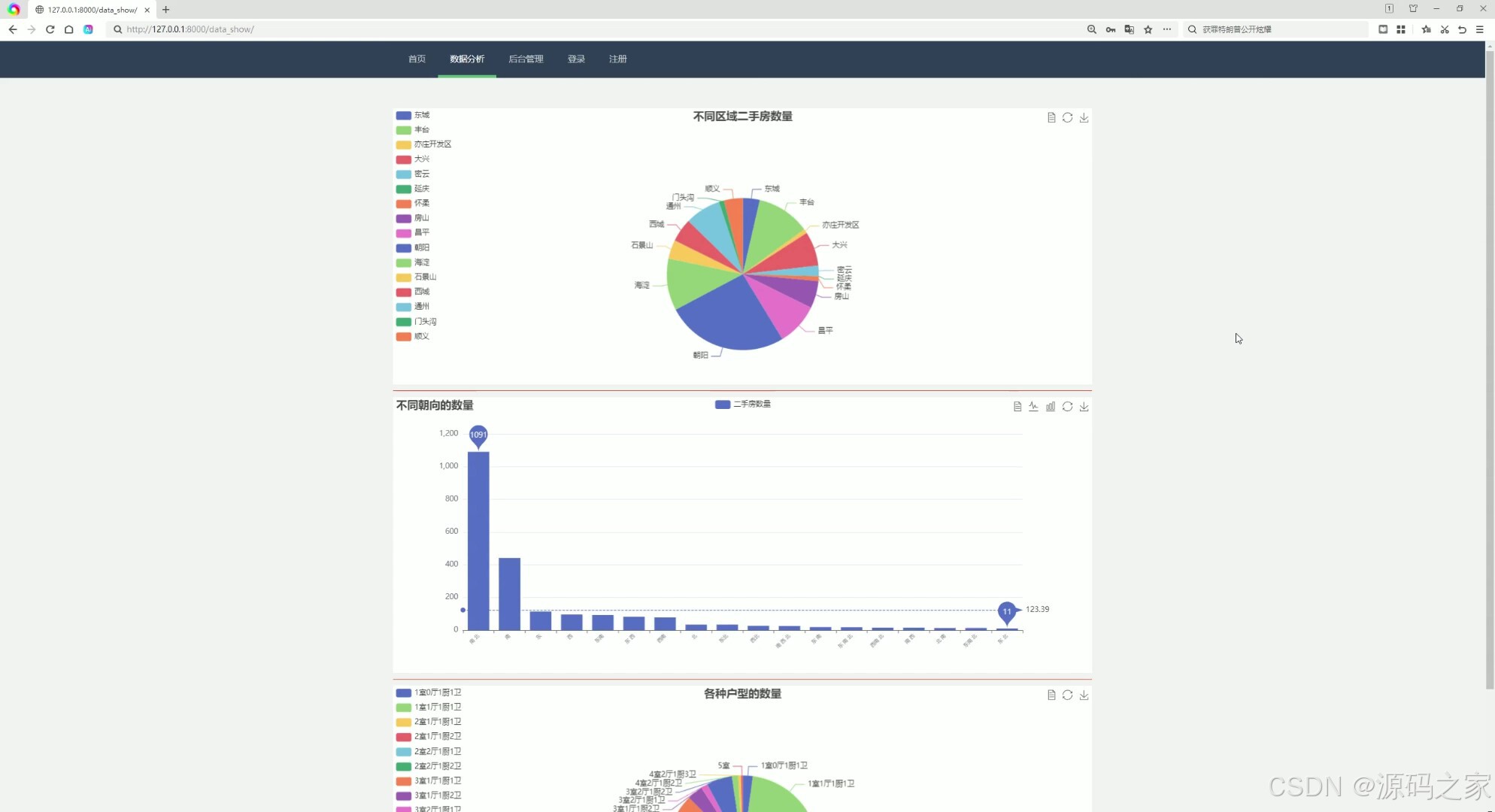
(1)二手房数量分析、不同朝向房源数据分析、各种户型数量分析
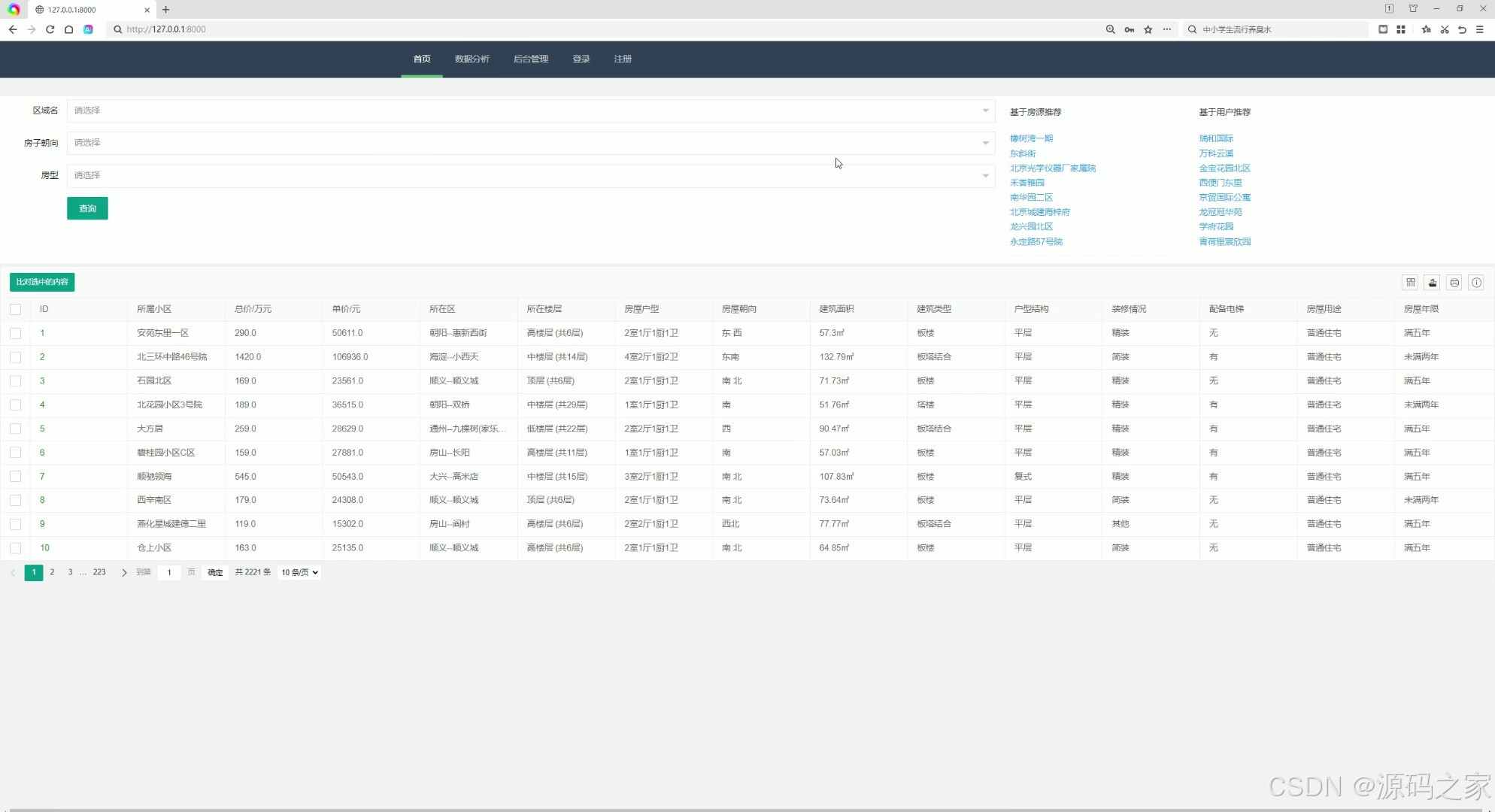
(2)房源数据、搜索查询、推荐模块
(3)注册登录
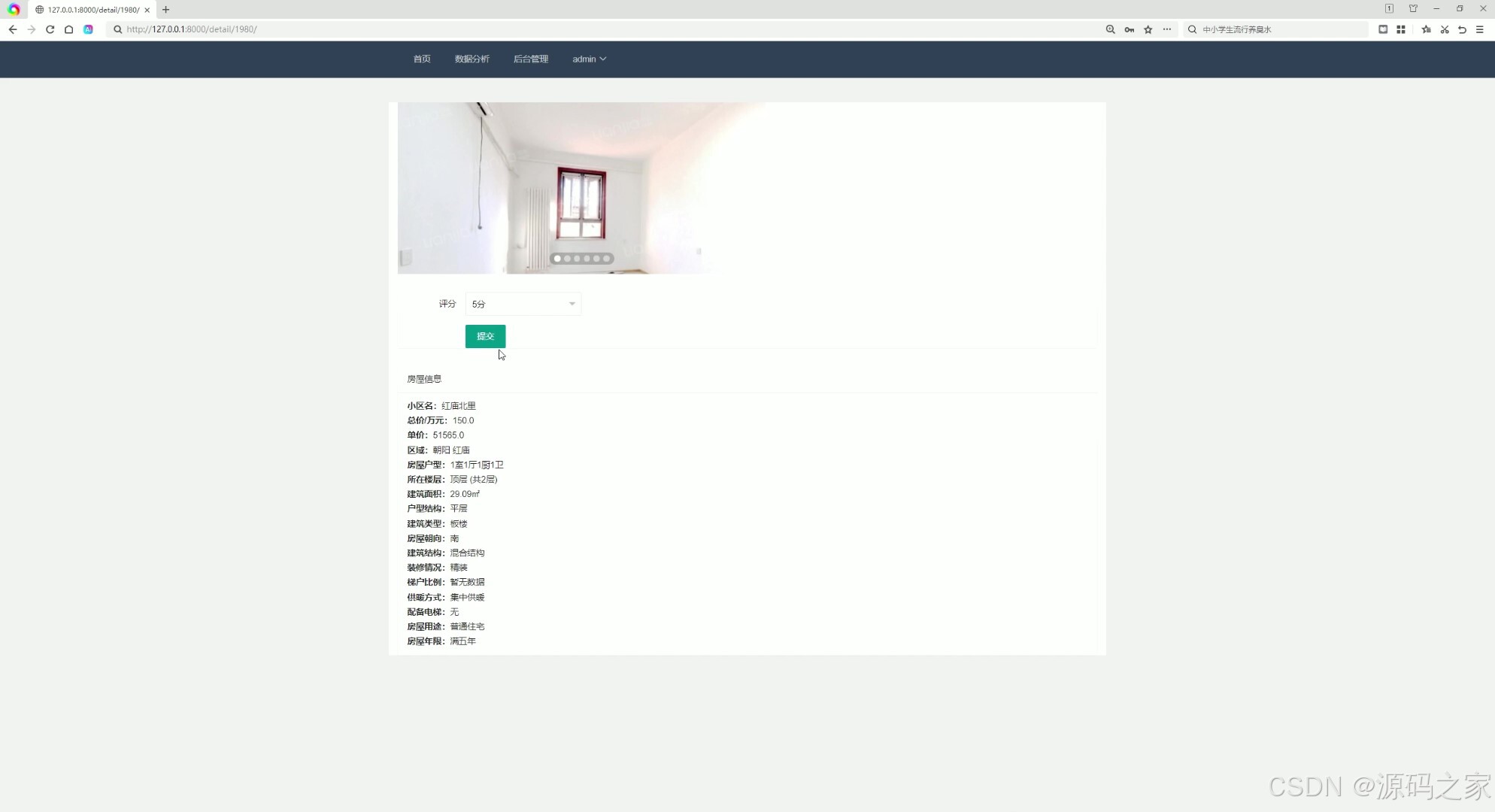
(4)房源详细页,房源评分
(5)后台数据管理
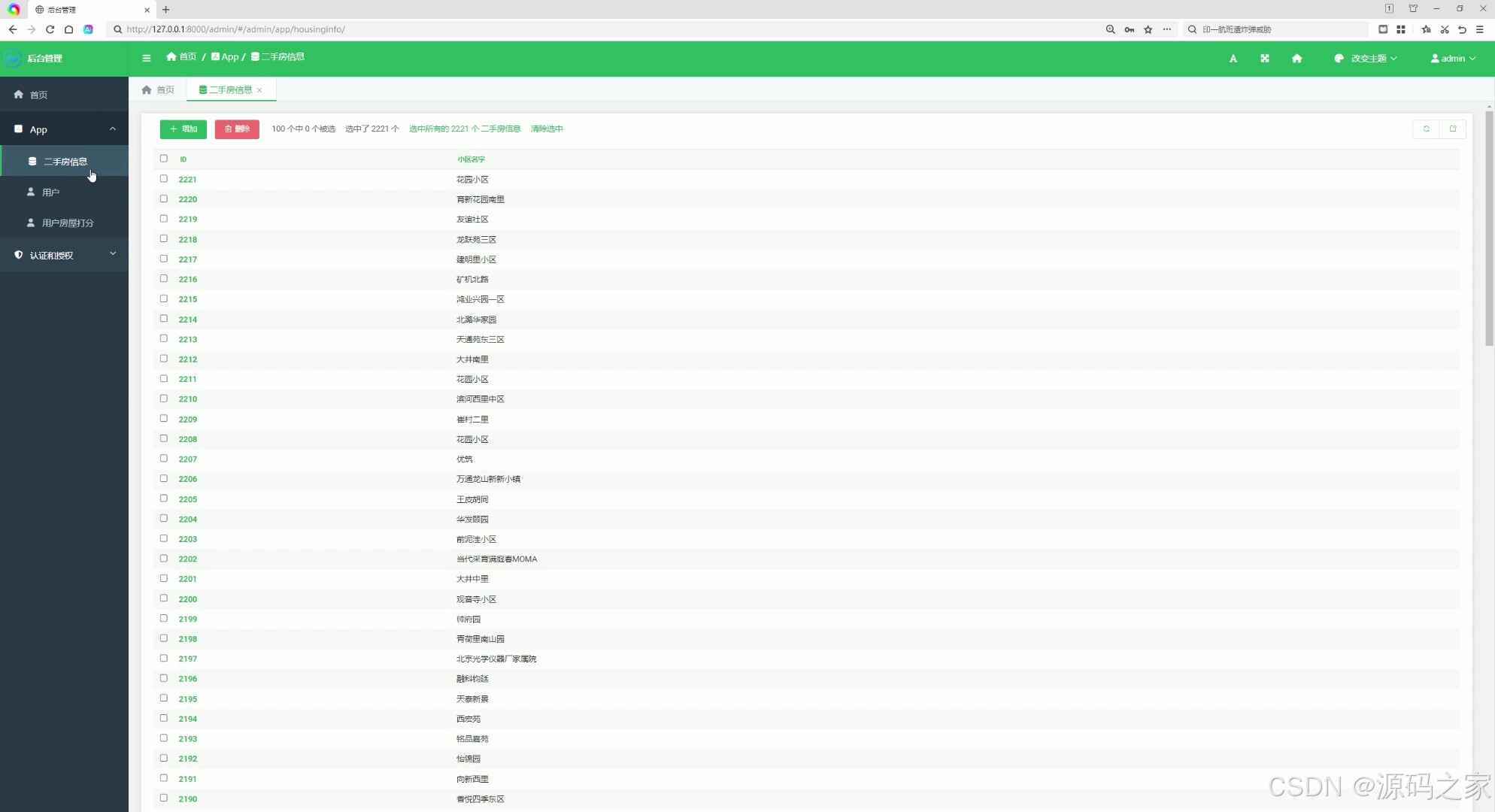
3、项目说明
项目功能模块介绍
1. 用户登录与注册
- 功能描述:用户可以通过注册账号并登录系统,享受个性化的房源推荐和数据查询服务。
- 特点:支持用户信息管理,确保用户数据的安全性和隐私性。
2. 房源数据分析与可视化
- 功能描述:
- 提供二手房数量分析,展示市场房源的整体规模。
- 对不同朝向的房源进行数据统计,帮助用户了解市场偏好。
- 分析各种户型的数量分布,为用户提供户型选择的参考。
- 技术实现:使用Echarts进行数据可视化,以直观的图表形式展示分析结果。
3. 房源数据查询与推荐
- 功能描述:
- 用户可以通过关键词或筛选条件搜索房源。
- 系统基于用户的浏览历史和偏好,提供个性化的房源推荐。
- 支持基于物品的协同过滤推荐和基于用户的协同过滤推荐算法。
- 特点:提供精准的推荐服务,帮助用户快速找到心仪的房源。
4. 房源详细页与评分
- 功能描述:
- 用户可以查看房源的详细信息,包括图片、描述、价格等。
- 提供房源评分功能,用户可以根据自己的体验对房源进行评价。
- 特点:增强用户与房源之间的互动性,为其他用户提供参考。
5. 后台数据管理
- 功能描述:
- 管理员可以通过后台管理系统对房源数据进行增删改查。
- 支持用户信息管理、数据统计和分析。
- 特点:提供高效的数据管理工具,确保数据的准确性和完整性。
6. 数据对比功能
- 功能描述:
- 用户可以对不同房源进行数据对比,包括价格、户型、朝向等关键信息。
- 特点:帮助用户快速比较房源优劣,做出更明智的决策。
4、核心代码(协同过滤推荐片段)
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 示例评分矩阵
ratings = np.array([
[5, 4, 0, 3], # 用户1 对房源的评分
[0, 0, 4, 5], # 用户2
[4, 5, 0, 0], # 用户3
[3, 0, 5, 4] # 用户4
])
# 计算相似度矩阵
cosim_matrix = cosine_similarity(ratings)
# 获取邻居函数
def get_neighbors(user_id, k=5):
sorted_indices = np.argsort(cosim_matrix[user_id])[::-1][:k]
return sorted_indices
# 预测评分函数
def predict_ratings(user_id, item_id, ratings, k=5):
neighbors = get_neighbors(user_id, k)
neighbor_ratings = ratings[neighbors, item_id]
return np.mean(neighbor_ratings[neighbor_ratings > 0])
4、核心代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : CFItem.py
import math
from app.models import UserHousing, UserInfo, HousingInfo
from collections import defaultdict
def user_based_recommendation(target_user, num_recommendations, K=5):
"""
计算用户相似度矩阵。可以使用余弦相似度或皮尔逊相关系数等方法计算用户之间的相似度。
对于目标用户,找到与其相似度最高的K个用户。
对于这K个用户,找到他们评分过的但目标用户没有评分过的物品,计算推荐分数。
根据推荐分数排序,推荐前N个物品。
"""
similarity_scores = defaultdict(int)
for user in UserInfo.objects.exclude(id=target_user.id):
# 计算用户相似度
common_housings = UserHousing.objects.filter(
user=target_user,
house__in=user.userhousing_set.values_list("house", flat=True),
)
if not common_housings:
continue
target_ratings = {uh.house_id: uh.score for uh in common_housings}
user_ratings = {uh.house_id: uh.score for uh in user.userhousing_set.all()}
similarity_scores[user.id] = cosine_similarity(target_ratings, user_ratings)
k_nearest_users = sorted(
similarity_scores.items(), key=lambda x: x[1], reverse=True
)[:K]
# 对于这K个用户,找到他们评分过的但目标用户没有评分过的物品,计算推荐分数
recommendation_scores = defaultdict(int)
for user_id, similarity_score in k_nearest_users:
user = UserInfo.objects.get(id=user_id)
for uh in user.userhousing_set.exclude(
house__in=target_user.userhousing_set.values_list("house", flat=True)
):
recommendation_scores[uh.house_id] += similarity_score * uh.score
# 根据推荐分数排序,推荐前N个物品
recommended_housings = sorted(
recommendation_scores.items(), key=lambda x: x[1], reverse=True
)[:num_recommendations]
res = [
HousingInfo.objects.get(id=house_id) for house_id, score in recommended_housings
]
if len(recommended_housings) < num_recommendations:
n = num_recommendations - len(recommended_housings)
rom_recommendations = HousingInfo.objects.exclude(
id__in=[i for i, _ in recommended_housings]
).order_by("?")[:n]
res.extend(list(rom_recommendations))
return res
def item_based_recommendation(target_user, num_recommendations, K=5):
"""
计算物品相似度矩阵。可以使用余弦相似度或皮尔逊相关系数等方法计算物品之间的相似度。
对于目标用户,找到他评分过的物品。
对于这些物品,找到与其相似度最高的K个物品。
对于这K个物品,计算推荐分数。
根据推荐分数排序,推荐前N个物品
"""
# 找到目标用户评分过的物品
target_ratings = {uh.house_id: uh.score for uh in target_user.userhousing_set.all()}
# 计算物品相似度矩阵
item_similarities = defaultdict(dict)
for uh in UserHousing.objects.all():
if uh.house_id not in item_similarities:
item_similarities[uh.house_id] = {}
for other_uh in UserHousing.objects.filter(house=uh.house).exclude(
user=target_user
):
item_similarities[uh.house_id][other_uh.house_id] = cosine_similarity(
{uh.user_id: uh.score}, {other_uh.user_id: other_uh.score}
)
# 对于目标用户评分过的物品,找到与其相似度最高的K个物品
k_nearest_items = defaultdict(list)
for house_id, rating in target_ratings.items():
for other_house_id, similarity in sorted(
item_similarities[house_id].items(), key=lambda x: x[1], reverse=True
)[:K]:
if other_house_id not in target_ratings:
k_nearest_items[other_house_id].append((house_id, rating, similarity))
# 对于这K个物品,计算推荐分数
recommendation_scores = defaultdict(float)
for house_id, similar_houses in k_nearest_items.items():
for target_house_id, target_rating, similarity in similar_houses:
recommendation_scores[house_id] += similarity * target_rating
# 根据推荐分数排序,推荐前N个物品
recommended_housings = sorted(
recommendation_scores.items(), key=lambda x: x[1], reverse=True
)[:num_recommendations]
res = [
HousingInfo.objects.get(id=house_id) for house_id, score in recommended_housings
]
if len(recommended_housings) < num_recommendations:
n = num_recommendations - len(recommended_housings)
rom_recommendations = HousingInfo.objects.exclude(
id__in=[i for i, _ in recommended_housings]
).order_by("?")[:n]
res.extend(list(rom_recommendations))
return res
def cosine_similarity(ratings1, ratings2):
dot_product = sum(
ratings1.get(house_id, 0) * ratings2.get(house_id, 0)
for house_id in set(ratings1) & set(ratings2)
)
magnitude1 = math.sqrt(sum(score ** 2 for score in ratings1.values()))
magnitude2 = math.sqrt(sum(score ** 2 for score in ratings2.values()))
return dot_product / (magnitude1 * magnitude2)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/q_3456621138/article/details/151876490

