

🔥个人主页:爱和冰阔乐
📚专栏传送门:《数据结构与算法》 、C++
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

文章目录
- 前言:认识 STL——C++ 标准库的基石
- 一、先搞懂:为什么要抛弃 C 字符串用 string?
- 1.C字符串的三大痛点
- 2.现实需求
- 二、C++11 小助手:auto 与范围 for,用 string 更顺手
- 1. auto:让编译器帮你推类型
- 2.范围 for:遍历 string / 数组
- 三、string 类核心接口全解析(必学!)
- 1. string 对象的构造(3 种常用)
- 2.容量操作
- 3.访问与遍历
- 4.修改操作
- 5. 非成员函数(4 个常用)
- 四、揭秘底层:vs 和 g++ 的 string 实现居然不一样!
- 1.vs 的 “小字符串优化”(SSO):兼顾效率与空间
- 2.g++ 的 “写时拷贝”(COW):共享内存省空间
- 五、避坑指南:浅拷贝的 “致命陷阱” 与深拷贝实现
- 1.浅拷贝:为什么会崩溃?——共用资源的灾难
- 2.深拷贝:正确的实现方式(三种写法)
- 六、模拟实现string
- 总结
前言:认识 STL——C++ 标准库的基石
在深入探讨string之前,我们有必要先了解它所属的 “大家庭”——STL(Standard Template Library,标准模板库)。STL 是 C++ 标准库的核心组成部分,由 Alexander Stepanov 于 1994 年提出,它以泛型编程为思想,将数据结构(容器)与算法分离,通过迭代器连接,为开发者提供了一套高效、可复用的组件。
STL主要包含六大组件:
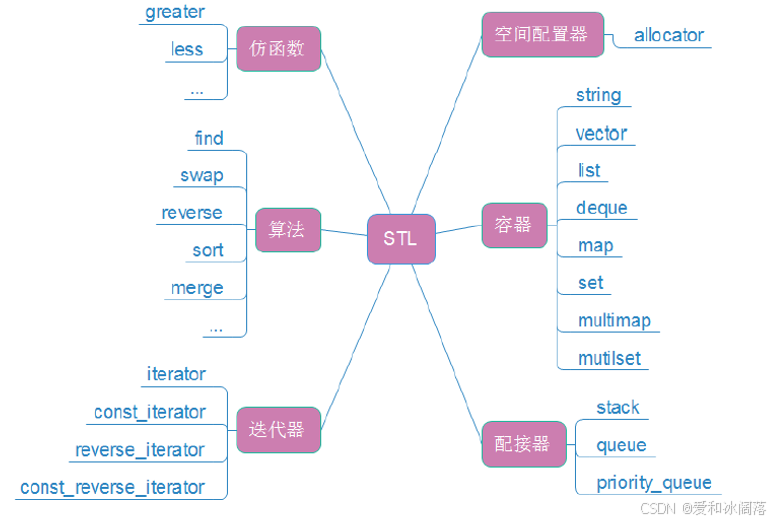
容器(Containers): 封装数据结构的类模板(如vector、list、map、string等),用于存储和管理数据
算法(Algorithms): 实现常用操作的函数模板(如sort、find、copy等),可作用于容器中的元素
迭代器(Iterators): 连接容器与算法的 “桥梁”,提供类似指针的接口,使算法能统一访问不同容器
仿函数(Functors): 重载operator()的类 / 结构体,可作为算法的策略参数(如自定义排序规则)
适配器(Adapters): 修改容器、迭代器或仿函数的接口(如stack、queue是deque的适配器)
分配器(Allocators): 负责容器的内存管理,隐藏底层内存分配细节
STL 的优势在于高复用性(一套代码适配多种数据类型)、高性能(底层经严格优化)和标准化(跨平台一致行为)。而string作为 STL 中专门处理字符串的容器,完美体现了 STL 的设计思想 —— 它封装了字符序列的存储与操作,支持迭代器访问,可与 STL 算法(如reverse、find)无缝配合,是我们学习 STL 的绝佳起点。
在正常笔试中STL也会经常被考到,如:把二叉树打印成多行 ,用两个栈实现队列。
网上有句话说:“不懂STL,不要说你会C++”。STL是C++中的优秀作品,有了它的陪伴,许多底层的数据结构以及算法都不需要自己重新造轮子,站在前人的肩膀上,健步如飞的快速开发。
因此我们便可以看出STL的重要性了!!!
一、先搞懂:为什么要抛弃 C 字符串用 string?
在学string之前,我们得先明白:C 语言的字符串到底 “烂” 在哪里?
1.C字符串的三大痛点
C 语言里,字符串是’\0’结尾的字符数组,搭配str系列库函数(strcpy、strcat、strlen)使用,但问题一大堆:
数据与操作分离: 字符串是数组,库函数是独立的,比如strcpy(s1, s2)需要传两个参数,不符合 “对象 = 数据 + 方法” 的 OOP 思想
内存全靠手动管: 要自己malloc分配空间、free释放,忘了free就内存泄漏,分配小了就越界
越界风险极高: 比如strcat(s, “hello”),如果s的缓冲区不够大,直接触发未定义行为(程序崩溃是轻的)
举个真实的踩坑案例:
// C语言字符串的坑
char buf[5];
strcpy(buf, "hello"); // 缓冲区只有5字节,"hello"占6字节(含'\0'),越界!
这种问题在string里根本不会出现 —— 它会自动扩容,不用你操心内存!
C++ 的string类完美解决了这些问题:它封装了字符串的存储与操作,自动管理内存,提供了丰富的成员函数,且在 OJ 和实际开发中几乎完全替代了 C 语言字符串。
2.现实需求
1.OJ 刷题: LeetCode、牛客网的字符串题,99% 都是以string类给出的
2.实际开发: 没人会放着string不用去折腾 C 字符串,string的接口更简洁(比如拼接直接用+=,求长度用size()),能大幅减少 bug。
二、C++11 小助手:auto 与范围 for,用 string 更顺手
在正式学string接口前,先掌握两个 C++11 语法糖 ——auto和范围 for,它们是使用string的 “神器”,是提升编码效率的利器
1 前置知识:C++11 的 auto 与范围 for
string的遍历和操作常依赖这两个特性,先快速上手:
1. auto:让编译器帮你推类型
在这里补充2个C++11的小语法,方便我们后面的学习
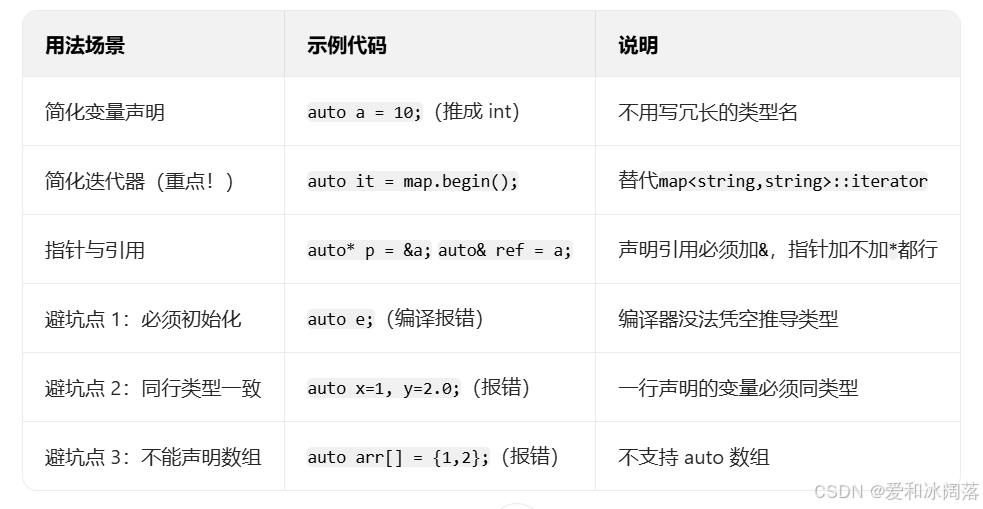
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,后来这个不重要了。C++11中,标准委员会变废为宝赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得
用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
auto不能作为函数的参数,可以做返回值,但是建议谨慎使用auto不能直接用来声明数组
auto:auto在 C++11 里的新含义是类型推导:声明变量时不用写具体类型,编译器会根据初始化值自动判断,尤其适合复杂类型(如map迭代器、string迭代器)
代码举例1:
#include<iostream>
using namespace std;
int func1()
{
return 10;
}
// 不能做参数
void func2(auto a)
{
}
// 可以做返回值,但是建议谨慎使用
auto func3()
{
return 3;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = func1();
// 编译报错:rror C3531: “e”: 类型包含“auto”的符号必须具有初始值设定项
auto e;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
int x = 10;
auto y = &x;
auto* z = &x;
auto& m = x;
cout << typeid(x).name() << endl;
cout << typeid(y).name() << endl;
cout << typeid(z).name() << endl;
auto aa = 1, bb = 2;
// 编译报错:error C3538: 在声明符列表中,“auto”必须始终推导为同一类型
auto cc = 3, dd = 4.0;
// 编译报错:error C3318: “auto []”: 数组不能具有其中包含“auto”的元素类型
auto array[] = { 4, 5, 6 };
return 0;
}
代码举例2:
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main() {
// 1. 基础类型推导
string s = "hello";
auto len = s.size(); // 推导为size_t
auto ch = s[0]; // 推导为char
// 2. 指针/引用推导:指针用auto/*均可,引用必须加&
int a = 10;
auto* p = &a; // 指针类型
auto& ref = a; // 引用类型(必须加&)
// 3. 实战场景:简化迭代器
map<string, string> dict = {{"apple", "苹果"}, {"orange", "橙子"}};
// 无需写:map<string, string>::iterator it = dict.begin()
auto it = dict.begin();
while (it != dict.end()) {
cout << it->first << ":" << it->second << endl;
++it;
}
return 0;
}
避坑点:
同一行声明多个变量时,类型必须一致(auto a=1, b=2.0报错)
不能作为函数参数(void func(auto a)报错)
不能直接声明数组(auto arr[] = {1,2,3}报错)
实战场景:遍历 map(没 auto 会疯!)
没有 auto 时,迭代器声明长到离谱;有了 auto,一行搞定:
#include <map>
#include <string>
using namespace std;
int main() {
map<string, string> dict = {{"apple", "苹果"}, {"orange", "橙子"}};
// 没有auto:冗长!
map<string, string>::iterator it1 = dict.begin();
// 有auto:简洁!
auto it2 = dict.begin();
while (it2 != dict.end()) {
cout << it2->first << ":" << it2->second << endl;
++it2;
}
return 0;
}
核心用法与注意事项的总结:
2.范围 for:遍历 string / 数组
C++11 的范围 for专门解决 “遍历集合” 的重复工作 —— 不用写循环条件、不用算索引,自动遍历每个元素。
对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围,自动迭代,自动取数据,自动判断结束。范围for可以作用到数组和容器对象上进行遍历范围for的底层很简单,容器遍历实际就是替换为迭代器,这个从汇编层也可以看到。
语法与用法:
// 语法:for(迭代变量 : 被遍历的范围)
for (auto 变量 : 数组/string/容器) {
// 操作变量
}
对比 C++98 和 C++11 的遍历方式,差距一目了然:
#include <string>
#include <iostream>
using namespace std;
int main() {
string str = "hello string";
// 1. C++98遍历:算长度、写索引,麻烦!
for (int i = 0; i < str.size(); ++i) {
cout << str[i] << " ";
}
cout << endl;
// 2. C++11范围for:简洁!
for (auto ch : str) { // auto自动推成char
cout << ch << " ";
}
cout << endl;
// 3. 要修改元素?加&(引用)
for (auto& ch : str) {
ch = toupper(ch); // 转大写
}
cout << str; // 输出HELLO STRING
return 0;
}
范围 for 底层是迭代器实现的(编译时会被替换为begin()/end()的循环)所以支持所有 STL 容器(vector、map等)和数组、string。
三、string 类核心接口全解析(必学!)
string类的接口很多,但实际开发中常用的就那么几个。我们按 “构造→容量→访问→修改” 的顺序梳理,附代码示例和避坑点。如若想了解更多接口,小手点我可以查看哦
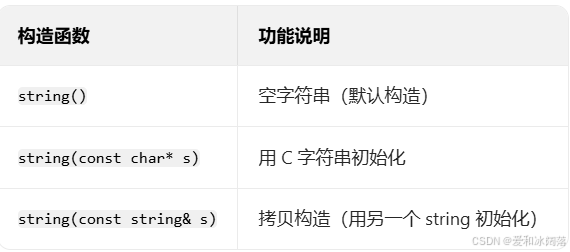
1. string 对象的构造(3 种常用)
构造string就像 “创建字符串”,最常用的 3 种方式如下表,直接看代码更直观:
#include <string>
using namespace std;
void TestString() {
string s1; // 空串,s1.size()=0
string s2("hello"); // 用C字符串"hello"初始化
string s3(s2); // 拷贝构造,s3和s2都是"hello"
}
2.容量操作
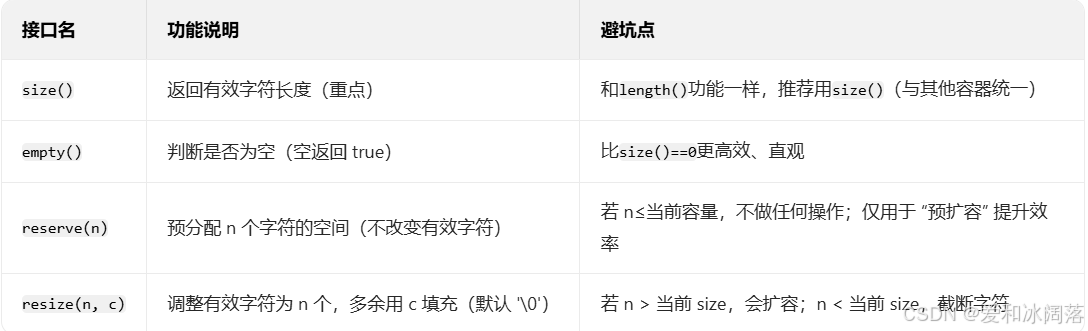
“容量” 指 string 管理的内存空间,这几个接口是避免内存频繁扩容的关键,必须吃透!
注意:
- size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接
口保持一致,一般情况下基本都是用size() - clear()只是将string中有效字符清空,不改变底层空间大小
- resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
- reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参
数小于string的底层空间总大小时,reserver不会改变容量大小。
实战示例:reserve 提升效率
如果要往 string 里插入 1000 个字符,不预分配空间会频繁扩容(每次扩容复制数据,耗时);用reserve预分配后效率翻倍:
#include <string>
#include <chrono> // 计时
using namespace std;
int main() {
string s1, s2;
s2.reserve(1000); // 预分配1000个空间
// 统计插入1000个字符的时间
auto start1 = chrono::high_resolution_clock::now();
for (int i = 0; i < 1000; ++i) s1 += 'a';
auto end1 = chrono::high_resolution_clock::now();
auto start2 = chrono::high_resolution_clock::now();
for (int i = 0; i < 1000; ++i) s2 += 'a';
auto end2 = chrono::high_resolution_clock::now();
// s2比s1快很多(扩容次数少)
cout << "s1耗时:" << chrono::duration_cast<chrono::nanoseconds>(end1-start1).count() << "ns\n";
cout << "s2耗时:" << chrono::duration_cast<chrono::nanoseconds>(end2-start2).count() << "ns\n";
return 0;
}
结果如下:

实战示例:容量操作的正确姿势
void TestCapacity() {
string s;
// 1. 预留空间:避免频繁扩容(比如已知要存100个字符)
s.reserve(100);
cout << "reserve后capacity: " << s.capacity() << endl; // 至少100
// 2. 调整有效长度
s.resize(10, 'a'); // 有效字符变为10个'a',size=10
cout << "resize后size: " << s.size() << endl;
// 3. 清空内容
s.clear();
cout << "clear后size: " << s.size() << endl; // 0
cout << "clear后capacity: " << s.capacity() << endl; // 仍为100(未释放)
}
避坑点:
1.reserve(n):若 n≤当前capacity,则不做任何操作
2.resize(n):若未指定填充字符,默认用\0填充(而非空格)
3.访问与遍历
访问 string 的单个字符,首选operator[](像数组一样方便),配合范围 for 或迭代器遍历更灵活。
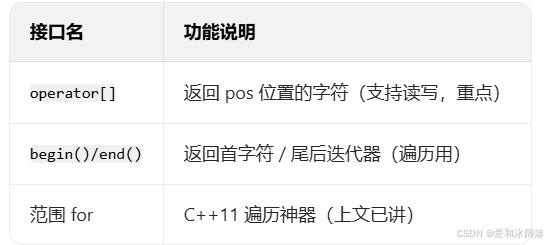
#include <string>
#include <iostream>
using namespace std;
int main() {
string s = "hello";
// 1. operator[]访问(像数组一样)
cout << s[0] << endl; // 输出'h'
s[1] = 'E'; // 修改为'hEllo'
// 2. 迭代器遍历
auto it = s.begin();
while (it != s.end()) {
cout << *it << " "; // 输出h E l l o
++it;
}
return 0;
}
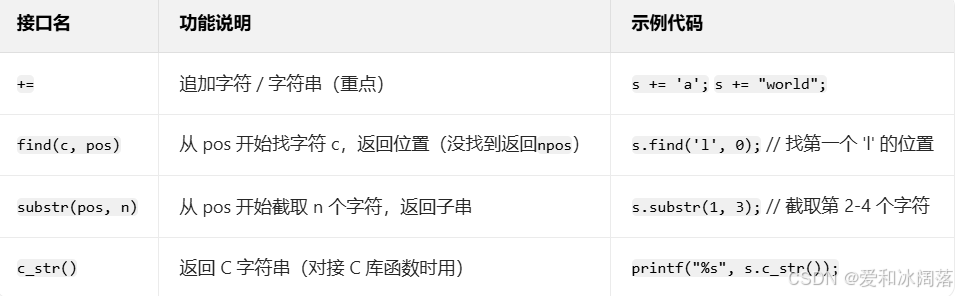
4.修改操作
string 的修改接口很多,但 +=、find、substr 是实际开发中用得最多的,比如拼接字符串、查找子串、截取子串
实战场景:截取文件后缀名
代码实现:
#include <string>
#include <iostream>
using namespace std;
int main() {
string filename = "test.txt";
size_t pos = filename.find('.'); // 找'.'的位置(返回4)
if (pos != string::npos) {
// 确保找到
string suffix = filename.substr(pos); // 从pos截取到末尾,得到".txt"
cout << suffix << endl;
}
return 0;
}
小贴士:string::npos是 string 的静态常量,表示 “未找到”(值为-1,但类型是size_t,所以不要用int接收返回值)
实战示例:字符串截取与查找
void TestModify() {
string s = "hello world";
// 1. 查找并截取
size_t pos = s.find(' '); // 找到空格位置(5)
string s1 = s.substr(0, pos); // 截取"hello"
string s2 = s.substr(pos+1); // 截取"world"(n省略则取到末尾)
// 2. 追加
s1 += " C++"; // s1变为"hello C++"
s1.push_back('!'); // s1变为"hello C++!"
// 3. 转为C字符串
const char* cs = s1.c_str();
cout << cs << endl; // 输出:hello C++!
}
效率提示:追加字符时,+=比push_back更灵活(支持字符串),比append更简洁,优先使用+=
5. 非成员函数(4 个常用)
string的非成员函数主要用于输入输出和比较:
operator<>:输出 / 输入字符串(>>遇空格终止)
getline(cin, s):读取一行字符串(包含空格,解决>>的缺陷)
关系运算符(==、!=、<等):直接比较字符串内容(按 ASCII 码排序)
四、揭秘底层:vs 和 g++ 的 string 实现居然不一样!
很多人只会用string,但不知道它底层怎么存的 —— 不同编译器的实现差异很大,这也是面试常考点!我们以32 位平台为例,看看 vs 和 g++ 的区别。
1.vs 的 “小字符串优化”(SSO):兼顾效率与空间
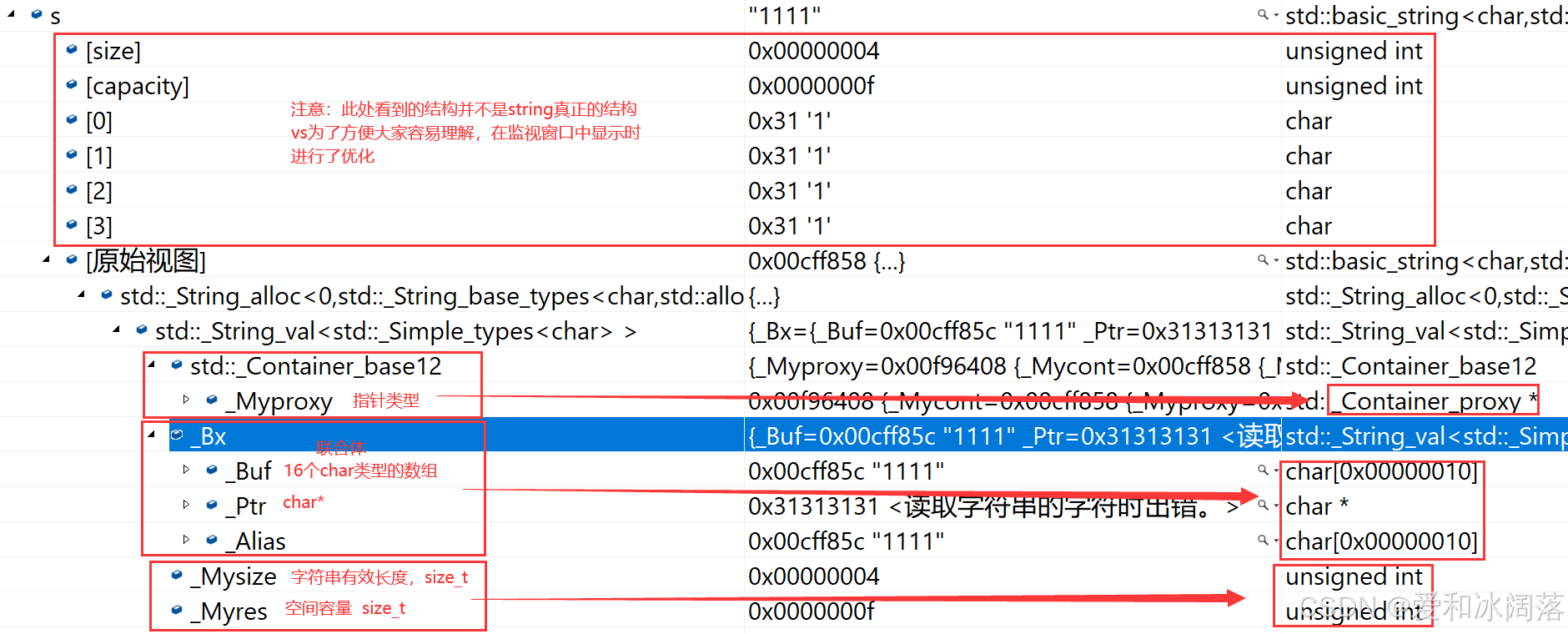
vs 下的string占28 字节,核心设计是 “小字符串用栈,大字符串用堆”:
1.当字符串长度 <16 时:用内部固定的 16 字节数组(栈空间)存放,不用分配堆内存,效率极高
2.当字符串长度≥16时:从堆上分配空间,数组存堆地址
内部结构拆解(28 字节):
联合体(16 字节):存小字符串数组或堆指针
size_t(4 字节):有效字符长度
size_t(4 字节):堆空间总容量
指针(4 字节):其他辅助功能
为什么这么设计? 因为大多数场景下的字符串都很短(比如文件名、用户名),用栈空间避免了堆分配的开销,效率翻倍
2.g++ 的 “写时拷贝”(COW):共享内存省空间
g++ 下的string更精简,只占4 字节—— 内部就是一个指针,指向堆上的一块 “控制块”,控制块包含 3 个信息:
- 字符串有效长度
- 堆空间总容量
- 引用计数(记录有多少个 string 共享这块内存)。
“写时拷贝” 的逻辑:
当用string s2(s1)拷贝时,不复制内存,只给引用计数 + 1(s1 和 s2 共享同一块内存);
当修改 s2 时(比如s2[0] = ‘a’),才会真正复制内存(此时引用计数 - 1,s2 单独拥有新内存)。
优缺点:读取时高效(共享内存),但写入时需要拷贝,且多线程下有线程安全问题(现在 g++ 的新版本已逐渐弃用 COW)
五、避坑指南:浅拷贝的 “致命陷阱” 与深拷贝实现
面试中,面试官最爱问:“自己实现一个 string 类,要注意什么?”—— 核心就是避开浅拷贝的坑!
1.浅拷贝:为什么会崩溃?——共用资源的灾难
如果我们天真地实现一个 “极简 string”,不写自己的拷贝构造和赋值运算符,编译器会生成默认浅拷贝——仅拷贝指针值(而非指针指向的内容),导致多个对象共用同一块堆空间::
// 错误示范:极简string(浅拷贝问题)
class String {
public:
// 构造
String(const char* str = "") {
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
// 析构
~String() {
delete[] _str;
_str = nullptr;
}
// 未写拷贝构造和赋值运算符(编译器生成默认的)
private:
char* _str;
};
// 测试:崩溃!
void Test() {
String s1("hello");
String s2(s1); // 浅拷贝:s1._str和s2._str指向同一块内存
} // 函数结束时:先析构s2(释放内存),再析构s1(释放已释放的内存→崩溃)
问题根源:浅拷贝只复制指针值,导致多个对象共享同一块内存,销毁时 “二次释放”。
这里我们来说下浅拷贝的两个大问题:
1.会导致同一块空间析构两次
2.修改一个便会导致另外一个被修改
形象比喻:浅拷贝像「两个孩子共用一个玩具」,一个弄坏了另一个没法玩
2.深拷贝:正确的实现方式(三种写法)
深拷贝的核心是:每个对象独立分配内存,不共享资源,需显式实现拷贝构造函数和赋值运算符重载,有「传统版」和「现代版」两种写法
写法 1:传统版(先分配,再拷贝,最后释放旧内存)
class String {
public:
// 构造
String(const char* str = "") {
if (str == nullptr) str = "";
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
// 拷贝构造(深拷贝)
String(const String& s) {
_str = new char[strlen(s._str) + 1]; // 独立分配内存
strcpy(_str, s._str); // 拷贝内容
}
// 赋值运算符(深拷贝:避免自赋值,先拷贝再释放)
String& operator=(const String& s) {
if (this != &s) { // 避免自赋值(s = s)
char* tmp = new char[strlen(s._str) + 1];
strcpy(tmp, s._str);
delete[] _str; // 释放旧内存
_str = tmp;
}
return *this;
}
// 析构
~String() {
delete[] _str;
_str = nullptr;
}
private:
char* _str;
};
写法 2:现代版(利用临时对象,更简洁安全)
现代版借助 “临时对象的析构” 来简化代码,不用手动管理旧内存:
class String {
public:
// 构造(同上)
String(const char* str = "") {
if (str == nullptr) str = "";
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
// 拷贝构造(现代版:用临时对象swap)
String(const String& s) : _str(nullptr) {
String tmp(s._str); // 用s的内容构造临时对象tmp
swap(_str, tmp._str); // 交换tmp和当前对象的_str
} // 临时对象tmp析构时,释放原来的_nullptr(无害)
// 赋值运算符(现代版:参数传值,自动生成临时对象)
String& operator=(String s) { // s是实参的拷贝(临时对象)
swap(_str, s._str); // 交换当前对象和s的_str
return *this;
} // s析构时,释放原来的旧内存
// 析构(同上)
~String() {
delete[] _str;
_str = nullptr;
}
private:
char* _str;
};
简单来说,现代版就是资本家不需要手动去实现,而是雇佣了牛马去帮他实现,最后成功被资本家窃取
总结:现代版更简洁,避免了 “先释放旧内存再分配新内存” 的中间状态,从根源上防止内存泄漏
写实拷贝

写时拷贝就是一种拖延症,是在浅拷贝的基础之上增加了引用计数的方式来实现的
引用计数:用来记录资源使用者的个数。在构造时,将资源的计数给成1,每增加一个对象使用该
资源,就给计数增加1,当某个对象被销毁时,先给该计数减1,然后再检查是否需要释放资源,
如果计数为1,说明该对象时资源的最后一个使用者,将该资源释放;否则就不能释放,因为还有
其他对象在使用该资源。
六、模拟实现string
模拟实现string的常见接口,点击它即可进入string的模拟实现代码仓库
总结
string看似简单,实则是 C++ 内存管理、OOP 思想、STL 设计的浓缩体现。掌握它的关键在于:
-
基础优先:熟练使用auto、范围 for,牢记构造、容量、修改的核心接口
-
深入底层:理解 VS 的 SSO 和 G++ 的 COW 差异,搞懂浅拷贝的危害与深拷贝的实现
-
多练实战:通过 OJ 题巩固接口使用,模拟实现加深对资源管理的理解
-
面试聚焦:重点准备「深拷贝的两种写法」「SSO 原理」「string 与 C 字符串的转换」
最后如果觉得这篇文章有用,欢迎点赞收藏~ 有任何问题,评论区一起讨论!
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2402_87731470/article/details/151250343

