
ML2023Spring - HW02 相关信息:
1.任务目标(回归)
Phoneme Classification 音素分类(识别)
训练/测试数据大小:3429/857(2116794/527364 frames)每个 frames 25ms,相邻 frames 间隔 10ms,1s 可以划分出 100 个frames,单个 frames 最后被处理为 39 维的 MFCC (Mel Frequency Cepstral Coefficients)
Label:41,对应 phoneme
2.性能指标(Metric)
分类精度
3.数据解析
train_split.txt: 其中每一行对应一个训练数据,其所对应的文件在feat/train/中
train_labels.txt: 由训练数据和labels组成,格式为: filename labels。其中,label 为 frame 对应的 phoneme
test_split.txt: 其中每一行对应一个训练数据,其所对应的文件在feat/test/中
feat/train/{id}.pt 和 feat/test/{id}.pt: 音频对应的 MFCC w/ CMVN,维度为39,这些文件可以通过torch.load()直接导入,导入后的shape为(T, 39)。
4. Baselines
根据作业 PDF 中的提示:
Simple Baseline (0.49798)
运行所给的 sample code。
Medium Baseline (0.66440)
连接 n 个frames。
具体选择多少个 frames 呢?HW02 PDF 中给出的样例是 11 个,查询相关专业知识后有下表
注意到英文中 phoneme 的持续时间都小于 11 个frames(11*25=275ms)。你可以根据专业知识自行选择,比如说你想再联系前后两个 phoneme 的信息来做预测,那设置成 15 也可以,这些由你自己去确定,从实验中获得更好的选择。
增加网络的隐藏层。
下图是我一开始记录的一些实验结果,仅简单的增加了层数和神经元个数便达到了 Medium Baseline(最终记录的是 Kaggle 上的分数),你可以根据自己的情况更进一步的优化它。
Strong Baseline (0.74944)
在 BasicBlock() 中增加 batchnorm 和 dropout 层。
增大 concat_nframes。
5.个人完整代码分享
https://github.com/holyeyes8/HUNG-YI_LEE_Machine-Learning_Homework/blob/master/HW02.ipynb
可以在colab上面正常运行
5.1 数据准备
# !pip install --upgrade gdown
# # Main link
# # 如果你已经从其他地方下载了数据集,则不需要执行该代码块
# !gdown --id '1qzCRnywKh30mTbWUEjXuNT2isOCAPdO1' --output libriphone.zip
# !unzip -q libriphone.zip
# !ls libriphone
import os
!git clone https://oauth2:[email protected]/datasets/Datawhale/HW2-DNN-libriphone.git
os.chdir('./HW2-DNN-libriphone')
!unzip -q ml2023spring-hw2.zip
将libriphone目录移动到相应位置
5.2 运行结果
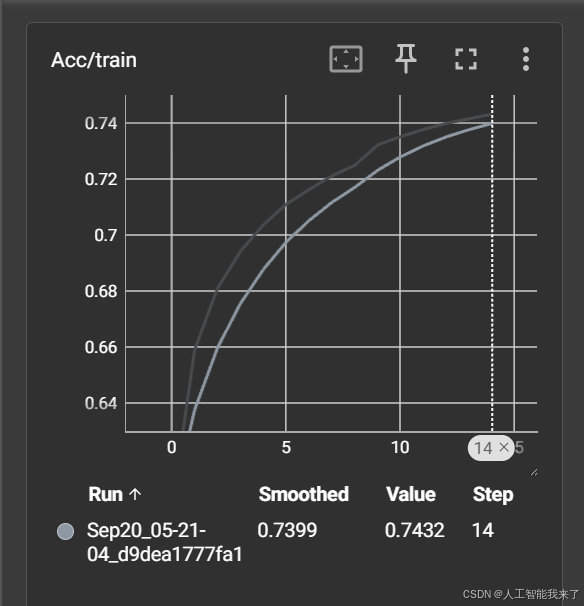
5.2.1 acc/train
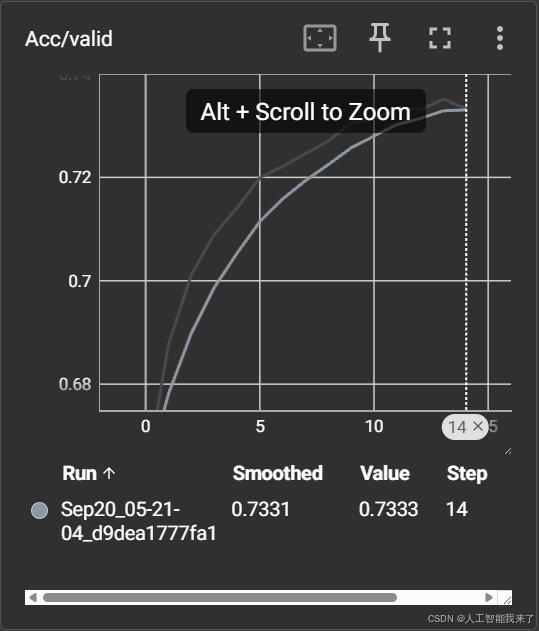
5.2.2 acc/valid
5.3.3 lr
参考:
https://blog.csdn.net/weixin_42426841/article/details/129764858
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/weixin_44626085/article/details/151896970

