
提到文件,我相信大部分同学应该都很讨厌这个东西,我们的老师们在讲C语言课的时候都会给我们讲解一些关于C语言的接口函数,而我们在听了之后压根就不知道这是一些什么东西,为什么打开文件要用那个FILE*结构体指针呢?这个结构体中又有什么东西呢?反正老师讲的时候就是告诉我是这么用的,至于为什么我不知道,就比如为什么以"w"方式使用这个接口,文件就被创建出来了等等一系列问题,给了我们一种模模糊糊的感觉,好像指导了,又好像不知道,感觉讲的有点耍流氓了,但是都是老师的问题么,站在圣人的角度,其实也不是,因为文件与我们的操作系统息息相关,在语言层面只能那么理解,只有在操作系统中,我们才能对文件有一个很好的理解。
文件共识
在操作系统中文件管理也是一个很重要的内容,与我们操作系统中的许多内容都息息相关,现在,我们来慢慢开始理解文件,首先,我们先建立一个基本的共识。
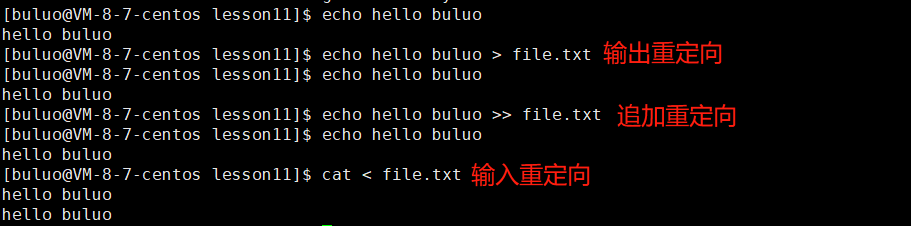
- 文件 = 内容 + 属性。(没错,我们的文件不仅仅只有我们看到的内容,还有属性,只不过我们平时不关心而已,就比如说文件名,文件创建时间,文件类型等等都是文件的属性,所以我们不能一提到文件,脑子里只有它的内容,还有它的属性信息)。
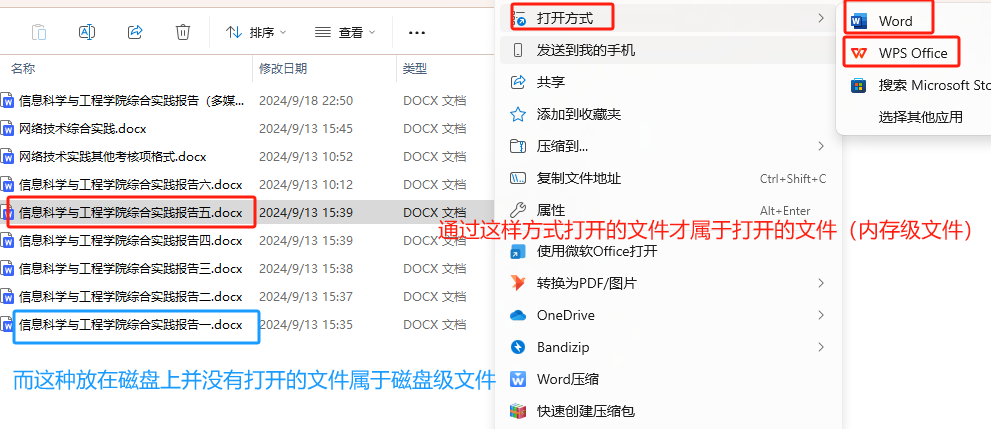
- 文件分为打开的文件和没打开的文件。(就是内存中的文件和磁盘中的文件,这是什么东西呢?我们可以这么理解,我们在学校写论文或者实验报告的时候,我们经常需要通过WPS或者office打开,就是这种通过WPS或者office打开的文件才是属于打开的文件(内存中的文件),那么这么多文件我们都打开了吗?当然没有了,只有当我们进行访问的时候,它才属于打开的文件(内存中的文件),而我们那些看到而没有通过WPS或者office打开的文件都是放在磁盘上的(磁盘级文件))。
- 那么打开的文件是谁打开的?大家可能会说我打开的,说的没毛病,但是本质上,是我们的进程打开的。也就是我们打开文件时需要通过WPS或者offic一样,当我们打开WPS或者offic这些可执行程序后,操作系统会为其创建进程控制块(PCB),然后通过该进程打开文件。
- 没打开的文件在磁盘中放着,那么我们对于这些放在磁盘上的文件,我们会关心什么呢?这个时候,我们就可以类比一个生活中的事情,相信大家都买过快递吧,如果没有买过,建议大家买一下,我们去取快递的时候,那些快递(文件)都是在菜鸟驿站(磁盘)哪里随便摆放的吗?当然不是,我们在取快递的时候都是会收到一个码(12-3-3300),这就表示我们的快递是在12号柜台第3层编号为3300的位置,然后通过这样的方式我们就可以快速拿到我们的快递,不然,如果没有这种整齐的摆放形式,当你去菜鸟驿站找快递的时候,找个快递浪费了一个小时,你可能直接就暴走了,开始亲切的问候了,所以,我们的文件也是如此,为了能够让操作系统可以在我们需要的时候可以快速找到并打开我们的文件,我们就需要对这些并没有打开的文件进行管理。
我们先来讨论打开的文件(内存中的文件),相信大家都学过计算机组成原理,我们CPU会与内存进行交互,而不会与磁盘进行交互,因为CPU运行速度太快了,而磁盘相对比较缓慢,所以两者是无法直接交互的,只能通过内存才能交互数据,所以我们要打开文件,就必须将文件从磁盘加载到内存;而之前我们也说过我们必须通过进程才能打开文件,那么进程:打开的文件是=?(1:1)?,会是1:1吗?当然不会,我们使用WPS的时候就算打开好几个文件,WPS也是允许的,所以么进程:打开的文件是=1:n,我们的进程是可以打开多个文件的。而我们的操作系统中存在大量的进程,也就会有大量的文件被打开,这么多文件被打开,操作系统需不需要管理这些被打开的文件呢?当然需要,那么如何管理呢?当然是先描述再组织,再一个内核中,一个被打开的文件都必须要有自己的文件打开对象,里面包含文件的很多属性。
C语言的接口使用(细节展示)
现在我们先来简单使用一下C语言给我们提供的文件接口,让大家先有个回忆。
#include<stdio.h>
int main()
{
FILE* fd = fopen("text.txt","w");
if(fd == NULL)
{
perror("fopen");
return 1;
}
fclose(fd);
return 0;
}
首先,我们可以看到,当我们通过w方式进行打开文件时,操作系统会为我们创建一个文件,而我们老师也经常对我们说,fopen中的第一个参数只带文件名的话,会在当前路劲给我们创建该文件,而当我们指明路径的时候,他就会在我们的指定路径下给我们创建文件,那么这个当前路径到底是什么?其实当前路径就是我们的可执行文件的路径,当我们将代码写好,对其进行编译链接之后,这个程序就成为了一个可执行文件,运行之后就会成为一个进程,所以当前路径就是我们进程的当前路径,我们让进程在执行结束的时候进行sleep,在这期间我们来看看进程的相关信息。
int main()
{
printf("pid:%d\n",getpid());
FILE* fd = fopen("text.txt","w");
if(fd == NULL)
{
perror("fopen");
return 1;
}
fclose(fd);
sleep(10000);
return 0;
}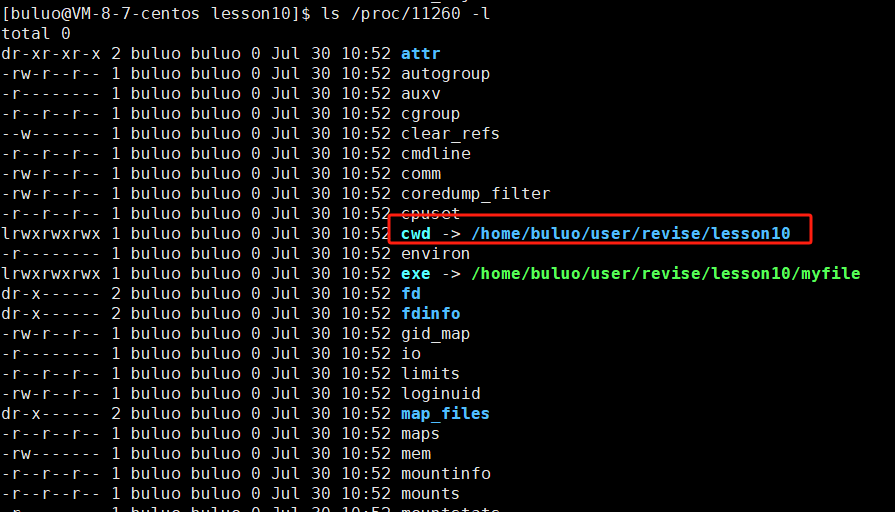
这个cwd就是我们进程的当前工作路径,所以我们没有带文件路径的时候,操作系统就默认给你将进程的当前工作路径给你加上了,所以就会创建在当前路径下。
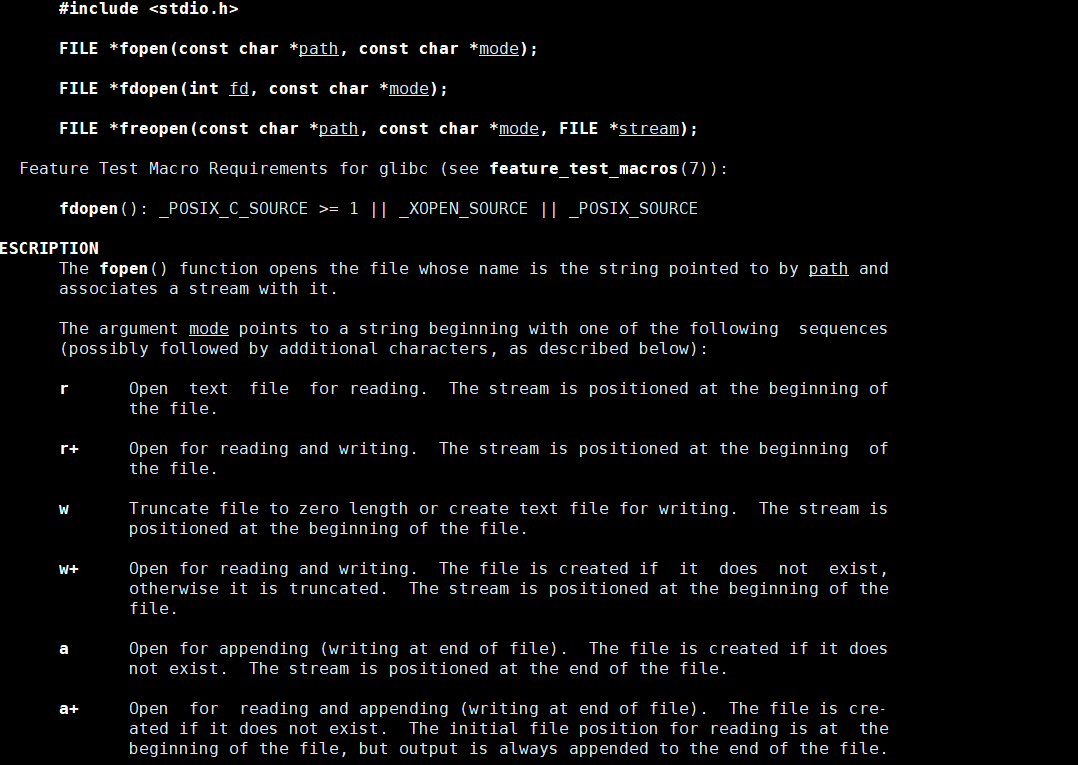
![]() 通过手册我们可以了解到以w打开时,它的意思就是如果有数据将文件的长度清零,没有该文件就会创建该文件,并且,使用该模式的话会从文件的开头进行。我们来测试一下。
通过手册我们可以了解到以w打开时,它的意思就是如果有数据将文件的长度清零,没有该文件就会创建该文件,并且,使用该模式的话会从文件的开头进行。我们来测试一下。
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
printf("pid:%d\n", getpid());
FILE *fd = fopen("text.txt", "w");
if (fd == NULL)
{
perror("fopen");
return 1;
}
//char *message = "hello 408";
char *message = "hello";
fwrite(message, strlen(message), 1, fd);
fclose(fd);
return 0;
} 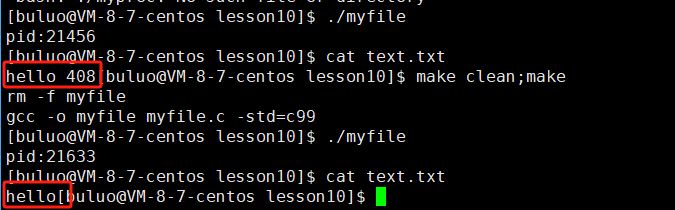

看完上面的程序,大家可能就有点奇怪了, ptr:输入数据的起始地址,nmemb表示要写入的数据个数,stream代表文件流fd,但是size不应该是输入数据的大小么,我们平时在计算字符串大小的时候,会将'\0'的大小也算进去呀,那你为什么用strlen函数只计算字符串的长度呢?大家如果可以提出这个问题就很优秀了,话我们不多说,现在又不是考试,我们试试不就知道了。
fwrite(message, strlen(message) + 1, 1, fd);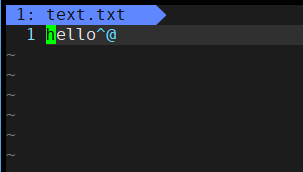
fwrite(message, strlen(message), 1, fd);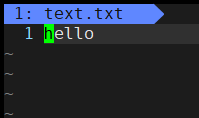
凭着眼见为实的本能,我们可以看到将'\0'加上的话,'\0'会被我们的文本编译器编译为一个乱码的东西,所以我们在写文件的时候不能加'\0',那么为什么呢?那是因为'\0'是字符串的结束标志,这是C语言的规定,和操作系统的文件有什么关系。C语言之所以以'\0'结束,是因为在内存中,它无法标定一个字符串的结束,不得不这么做,而我的文件又没有这样的规定,所以我们在写文件的时候只需要将文件的内容写进去即可。

int main()
{
printf("pid:%d\n", getpid());
FILE *fd = fopen("text.txt", "a");
if (fd == NULL)
{
perror("fopen");
return 1;
}
char *message = "hello 408";
fwrite(message, strlen(message), 1, fd);
fclose(fd);
return 0;
}
而我们通过a的模式进行写入时,如果该文件不存在就创建,打开文件都是在文件的结束的位置进行追加式写入。
C语言中的三个标准输入输出流
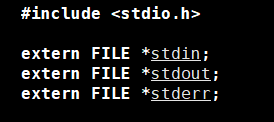
这就是老师上课经常给我们讲的什么标准输入流,标准输出流,标准错误流,之前我们估计只是只闻其声,不明其人,今天我们就来好好理解这三个标准输入输出流,可以看到这时C语言给我们提供的默认打开的三个标准输入输出流,它们和我们上面打开文件时定义的变量是一样的,我们如何使用我们上面的文件流,就如何使用这三个文件流。
fprintf(fd, "%s:%d\n", "buluo", 408);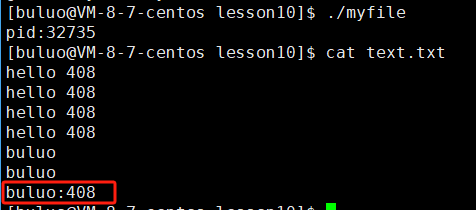
fprintf(stdout, "%s:%d", "buluo", 408);
可以看到我们在使用的时候只需要讲输出流改为标准输出,我们就可以将我们要打印的内容打印到显示器上。那么我们再来试试stderr
fprintf(stderr, "%s:%d\n", "buluo", 408);
可以看到它打印在显示器上了,那么有人就好奇了,这也和stdout没什么区别呀?别着急,我们慢慢来找区别,现在我们先提出两个问题:
- Linux下一切皆文件。
- C程序在默认启动的时候,会打开三个标准输入输出流:stdin(键盘文件),stdout(显示器文件),stderr(显示器文件),其实不止C语言,无论什么语言都会打开这三个标准输入输出流文件,就比如C++中是(cin,cout,cerr),那么为什么要支持这三个标准输入输出呢?
现在我们就讲语言层面的文件上升到系统。
Linux操作系统文件的系统调用接口
首先,文件实在我们的磁盘中存储的,磁盘是外部设备,访问磁盘就是在访问硬件。
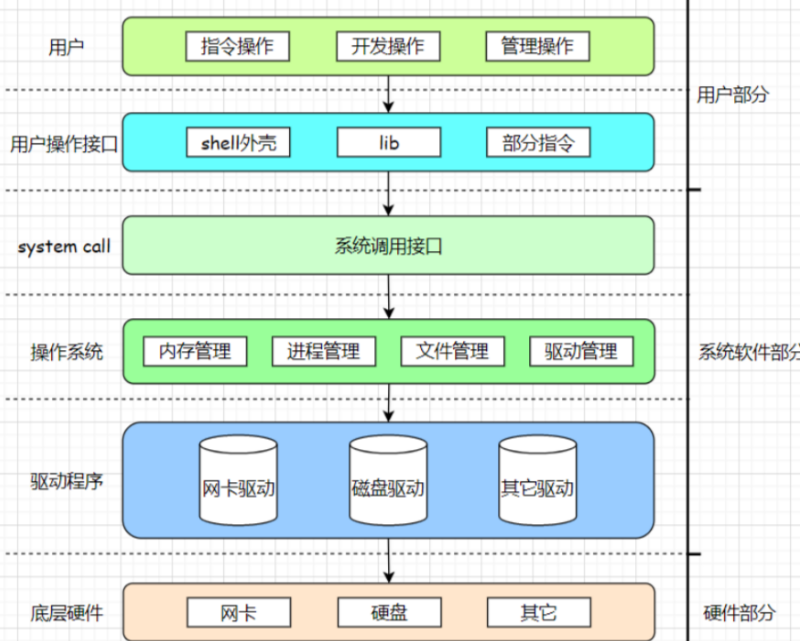
所以我们操作磁盘文件,是不能直接越级去访问的,必须一步一步,由上到下,按步骤访问,而我们的操做系统又不会相信用户,所以我们只能通过系统调用,然后让操作系统替我们去操作磁盘,所以我们可以意识到,所有的语言只要访问硬件设备,必定就要封装系统调用!!!也就是说像C语言的那些接口printf/sprintf/fopen/fread/fgets/scanf....等都是库函数调用接口,下面一定也是封装了系统调用接口才能使用的。那么说了这么多,这个系统的文件调用接口到底是什么呢?我们现在就来了解一下。
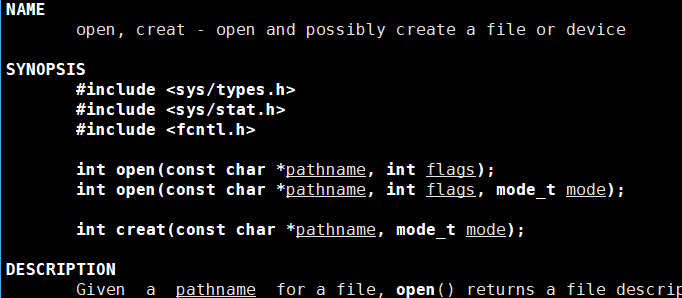
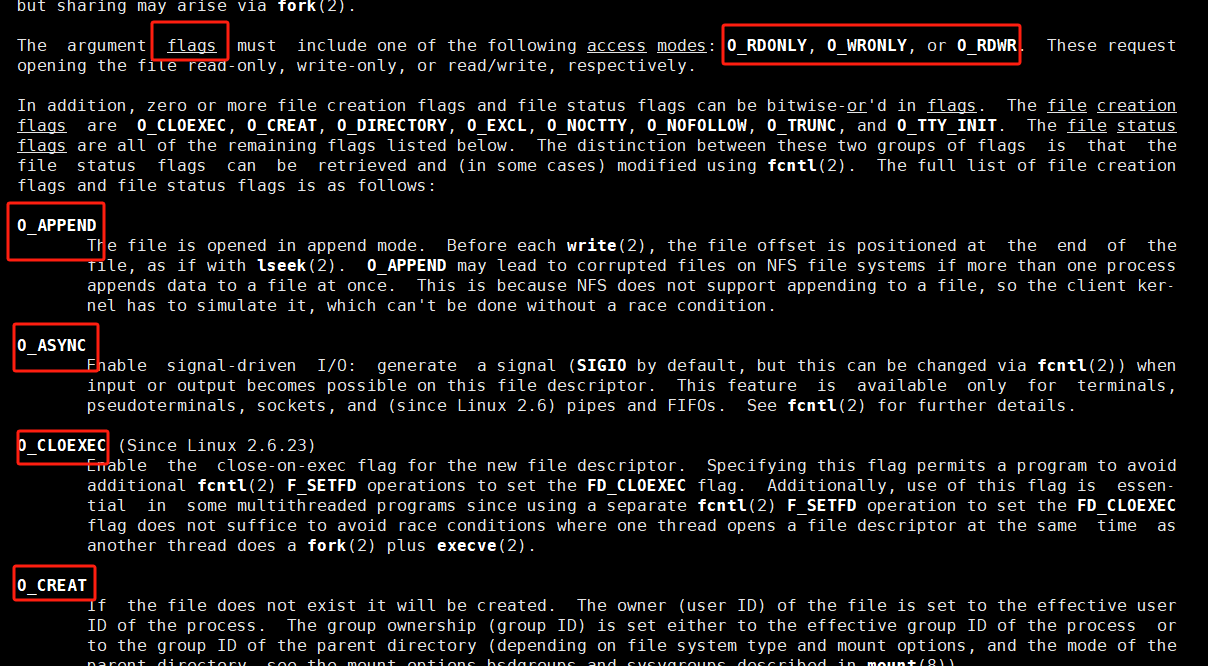
这就是系统调用接口中的open,可以看到我们flags参数中有很多选项,而这些参数都是一个一个宏,而系统调用接口中只给我们一个参数,我们如何传送多个参数呢?我相信,要是让我们实现这个参数,我们顶多就是多多定义几个形参就OK了,但是这里是操作系统,人家还是很牛的,人家这里只定义了一个形参flags就可以实现了,怎么实现的呢?其实这里宏都是比特位级别的标志位传递方式!话不多说,实践出真知。
#define ONE 0X1 //0001
#define TWO 0X2 //0010
#define THREE 0X4 //0100
#define FOUR 0X8 //1000
void show(int flags)
{
if(flags& ONE) printf("hello 1\n");
if(flags& TWO) printf("hello 2\n");
if(flags& THREE) printf("hello 3\n");
if(flags& FOUR) printf("hello 4\n");
printf("----------------------\n");
}
int main()
{
show(ONE);
show(TWO);
show(ONE|TWO);
show(ONE|TWO|THREE);
show(ONE|TWO|THREE|FOUR);
return 0;
}
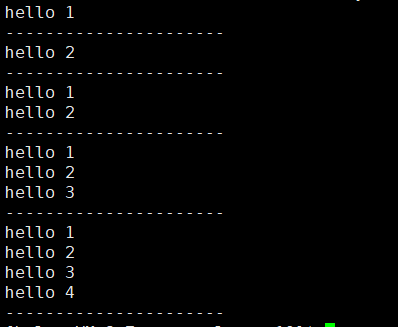
通过这样的方式,我们就可以一次传入多个参数了,很优雅的设计。所以我们在是用系统调用接口的时候就可以传入多个选项。
int main()
{
int fd = open("test.txt",O_WRONLY);
if(fd < 0)
{
printf("open file error\n");
exit(1);
}
return 0;
}![]()
看到结果我们就知道了,我们以O_WRONLY方式打开并不会给我们创建该文件,所以我们打开文件失败,所以我们需要增加权限O_CREAT才可以将其打开。
int fd = open("test.txt", O_WRONLY | O_CREAT);
但是打开之后怎么感觉怪怪的,这个怎么变颜色了,这是因为我们没有设置这个文本文件的权限,现在是系统默认的权限,所以我们需要在函数的第三个参数mode处增加一个权限的参数。
int fd = open("test.txt", O_WRONLY | O_CREAT, 0666);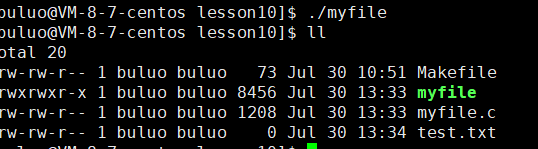
增加了权限之后我们就可以看到我们终于成功创建了文件,接下来我们也来通过系统调用接口来实现和C语言文件接口一样的功能。
文件描述符
我们先来看看系统调用接口的返回值。

可以看到上面这段话的意思就是调用open之后成功返回一个文件描述符(fd),失败则返回-1,那么这里也有一点奇怪,C语言的返回值类型是FILE*,这里是个int,这又是怎么回事?后面再说,我们先来实现C语言的功能
同样使用系统调用接口write进行文件写入。
int main()
{
int fd = open("test.txt", O_WRONLY | O_CREAT, 0666);
if (fd < 0)
{
printf("open file error\n");
exit(1);
}
char* message = "hello file\n";
write(fd, message, strlen(message));
close(fd);
return 0;
}
可以看到成功写入,那么现在我们改变一下message中的长度,再看看会有什么现象?
char* message = "buluo\n";

可以看到我们的这段程序只是实现了文件创建和从头开始写的功能,并没有C语言中的w方式写时有数据会将其清空的现象,那么如何实现呢?肯定就是增加flags的参数即可,我们现在就来实现一下。
int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);![]()
这样我们就成功实现了C语言中以w方式打开后的文件功能了。
那么这样以a方式打开的文件功能我们就可以依葫芦画瓢就可以实现了。
int fd = open("test.txt", O_WRONLY | O_CREAT | O_APPEND, 0666); 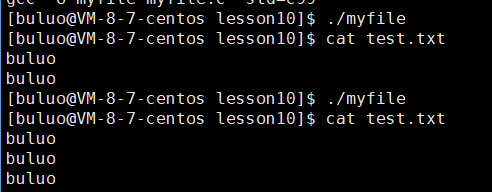
通过实验我们可以明显看出了C语言的文件调用接口在底层就是封装了系统调用接口,所以我们在应用层使用的无论什么语言,只要在Linux下运行,都是通过这些系统调用接口进行实现,对于这点,相信大家应该是没有疑问了,唯一一点的疑问就是FILE*和int fd有什么关系。我们现在就来了解一下访问文件的本质。透过本质看现象。
Linux中打开文件的系统原理
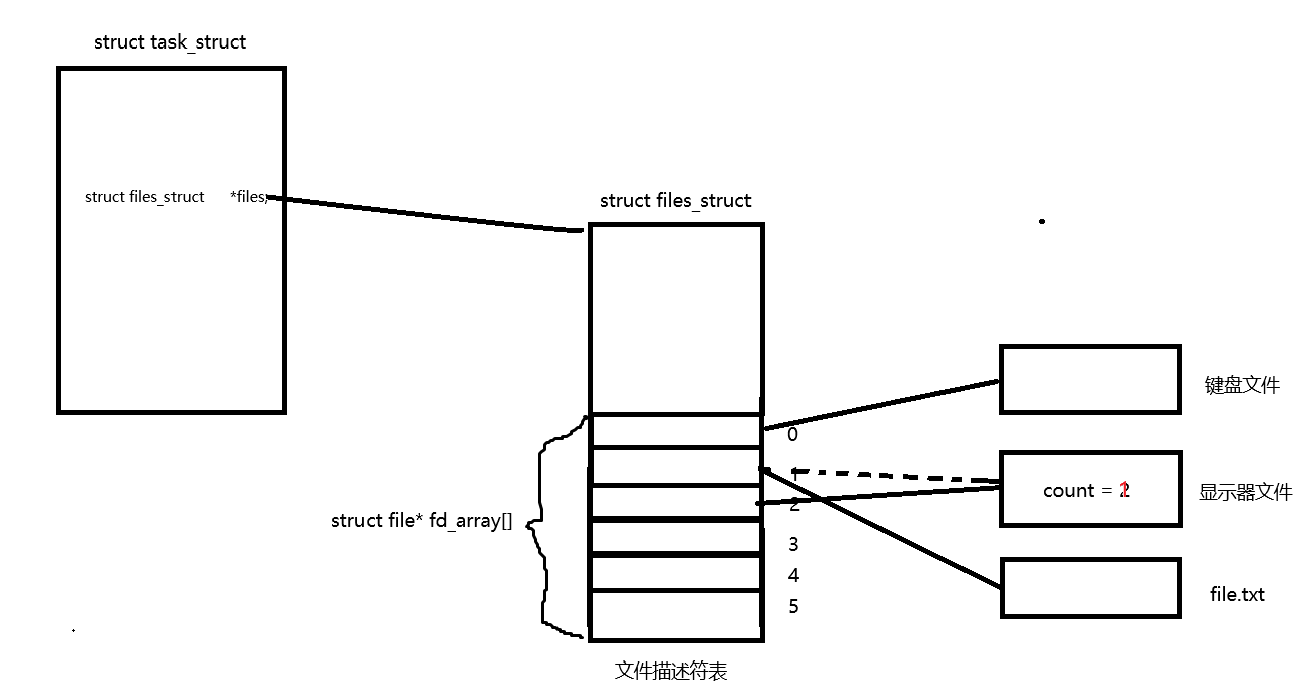
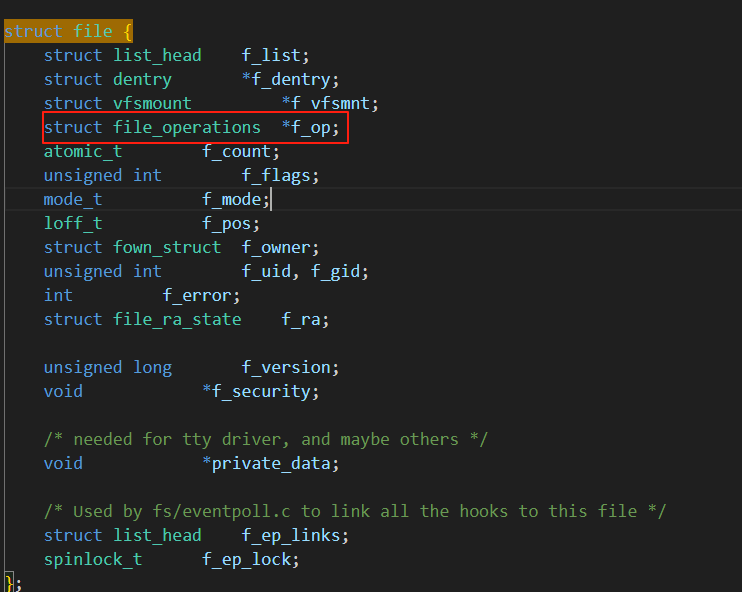
首先,我们打开文件时需要通过进程才能打开的,那么这些打开的文件我们的操作系统一定要对其进行管理,如何管理,先描述再组织,所以在内核中会定义一个struct file的结构体对文件的信息进行描述,当我们从磁盘将文件加载到内存后,操作系统会为这个文件创建对应的struct file结构体,将文件的相关信息放到结构体中,而我们只要在文件中增加一个链表一样的指针指向下一个文件的存放地址,这样我们的操作系统就可以像链表一样,管理我们的文件。


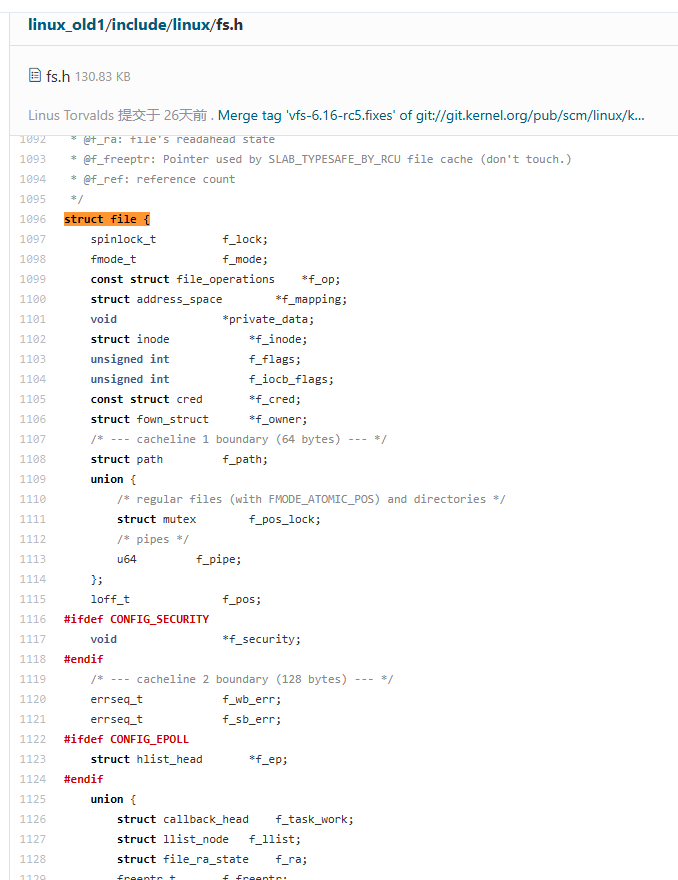
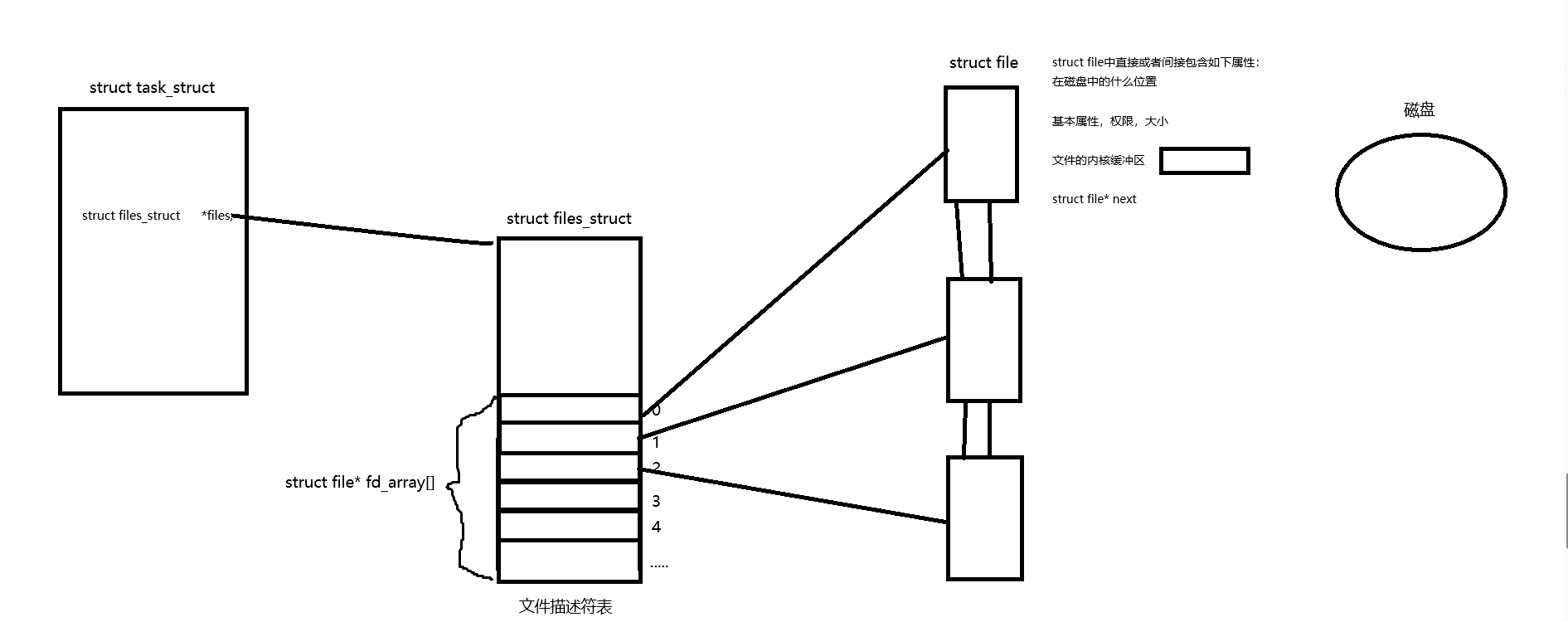
从内核中我们可以看到,在task_struct中会有一个struct files_struct *files的指针指向一个struct files_struct的对象,在该对象内会有一个指针型数组用来存放对应的struct file结构体的地址,每当我们的进程打开一个文件,实际上就是在这个文件描述符表中找到一个还没有分配出去的位置,将文件地址放在进程对应的文件描述符表的位置即可,这样,我们的进程只需要从PCB中找到这个文件描述符表,然后通过下标。就能找到操作系统管理这个文件的地址,这样我们就可以通过这样的方式进行对文件的操作。所以为什么系统调用接口open函数的返回值是int,这个int就是相当于文件描述符表中的一个下标,只要我们知道了下标,我们就可以访问该文件。现在我们就来看看这个文件描述符fd的值。
int main()
{
int fd1 = open("test1.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
int fd2 = open("test2.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
int fd3 = open("test3.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
int fd4 = open("test4.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
printf("fd1:%d\n", fd1);
printf("fd2:%d\n", fd2);
printf("fd3:%d\n", fd3);
printf("fd4:%d\n", fd4);
return 0;
}
我们可以看到,我们打开文件之后确实这些就是数组下标,那我就又有点奇怪了怎么从3开始的,0,1,2去哪了?如何大家比较仔细的话,现在这3个所对应的文件就是标准输入,标准输出和标准错误。所以在我们的操作系统中我们只认fd,至于什么FILE*一致不认,只要有fd就行。因为只有fd才能使我们的进程与文件进行挂钩,其它的都没有效果。现在我们就来证明一下这3个fd对应的就是标准输入,标准输出和标准错误。
系统文件中的标准输入,标准输出和标准错误
同时我们也使用一下系统调用接口read

int main()
{
char buffer1[] = "hello buluo\n";
char buffer2[1024];
read(0, buffer2, sizeof buffer2);
printf("%s\n", buffer2);
write(1, buffer1, strlen(buffer1));
write(2, buffer1, strlen(buffer1));
return 0;
}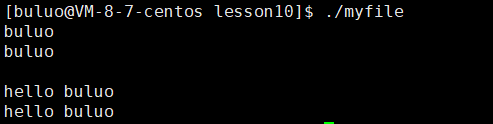
通过这样的实验,我们就可以看到确实操作系统默认会给我们打开标准输入,标准输出和标准错误(0,1,2),因为我们并没有打开它,但是我们依旧可以使用它。所以说这就是为什么那么老师在讲C语言说会默认打开标准输入,标准输出和标准错误,但是也没给我们讲清楚为什么,现在我们就知道为什么了,因为这是我们操作系统的默认就会打开的,所有的高级语言都必须遵循这个规则。注意:C语言中的FILE*这个结构体是C语言封装的,而我们上面的file是操作系统的结构体,这两个不能混为一谈,这是两个不同的东西。
了解到这里,我们也能知道FLIE中也一定封装了fd,我们可以通过C语言库中的定义和代码验证一下。
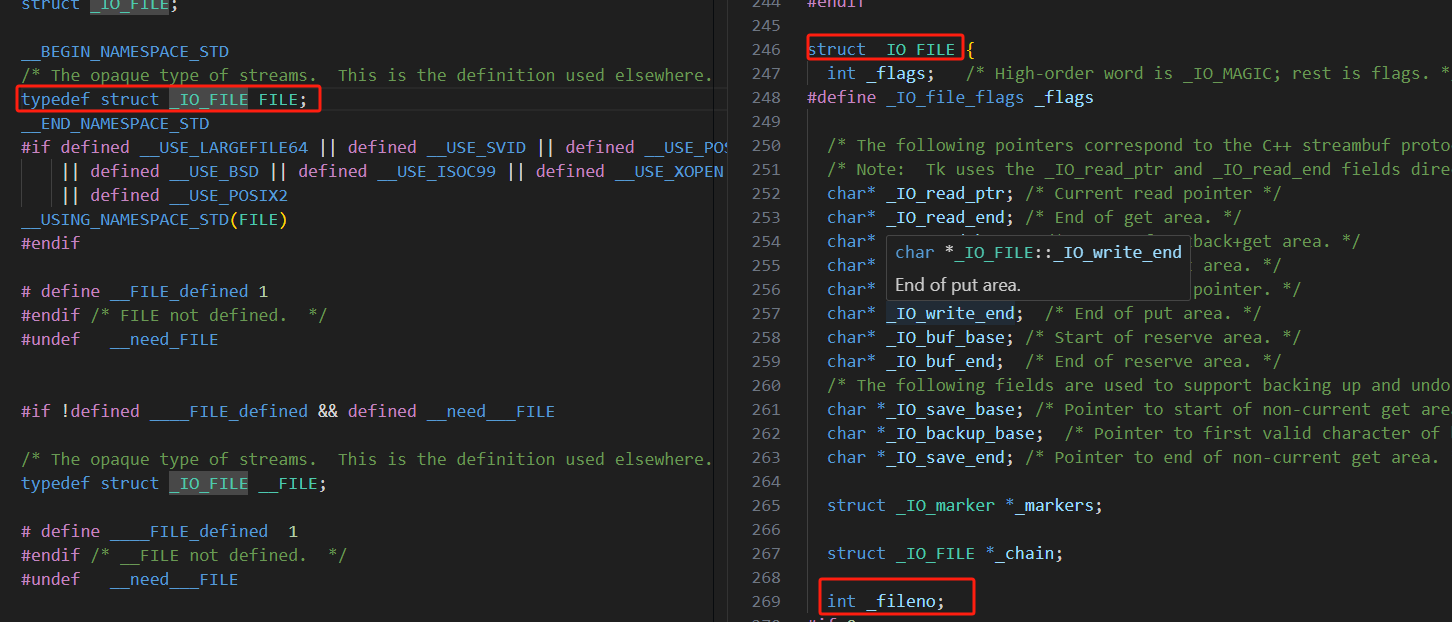
int main()
{
printf("stdin:%d\n", stdin->_fileno);
printf("stdout:%d\n", stdout->_fileno);
printf("stderr:%d\n", stderr->_fileno);
return 0;
}

这样,我们就完美验证了C语言的FILE结构体中是封装了fd这个指针描述符的。接下来我们是看看文件描述符的分配规则。
文件描述符的分配规则
int main()
{
close(0); //close(1); close(2);
int fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0)
{
perror("open");
exit(1);
}
printf("fd : %d\n", fd);
char buffer[] = "hello buluo\n";
write(fd, buffer, strlen(buffer));
sprintf(buffer, "fd : %d\n", fd);
write(fd, buffer, strlen(buffer));
close(fd);
return 0;
}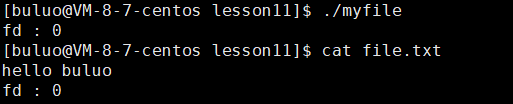

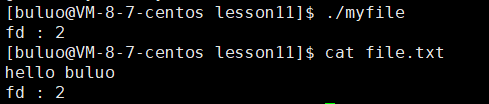
可以看到当我们分别先将0,1,2文件描述符关闭之后,我们的操作系统再给我们的新文件分配文件描述符就是我们关闭的文件描述符,所以我们的文件描述符的分配规则就是从0下标开始,寻找最小的没有被使用过的数组位置,它的下标就是新文件的文件描述符。
int main()
{
int fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0)
{
perror("open");
exit(1);
}
printf("fd : %d\n", fd);
char buffer[] = "hello buluo\n";
write(1, buffer, strlen(buffer));
close(fd);
return 0;
}![]()
int main()
{
close(1);
int fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0)
{
perror("open");
exit(1);
}
char buffer[] = "hello buluo\n";
write(1, buffer, strlen(buffer));
close(fd);
return 0;
}

从上面两部分代码我们可以看出,当我们正常向文件描述符1内打印东西是,会将我们的消息打印到我们的显示器上,但是当我们先将文件描述符1关掉之后,操作系统会给我们新创建的文件描述符从小开始分配,这样文件描述符1就被分配给我们的新文件,所以当我们再次给文件描述符1写内容的时候,就会将我们想向显示器打印的消息打印到我们的新文件中。这就是输出重定向的原理。
但是呢,这种方式感觉就上不了台面,每次我们要执行的时候还得先关闭1号描述符,再进行创建文件,看上去一点也不优雅,因此,我们的操作系统就给我们提供了进行这种操作的系统调用就是dup2。
系统调用接口dup2函数

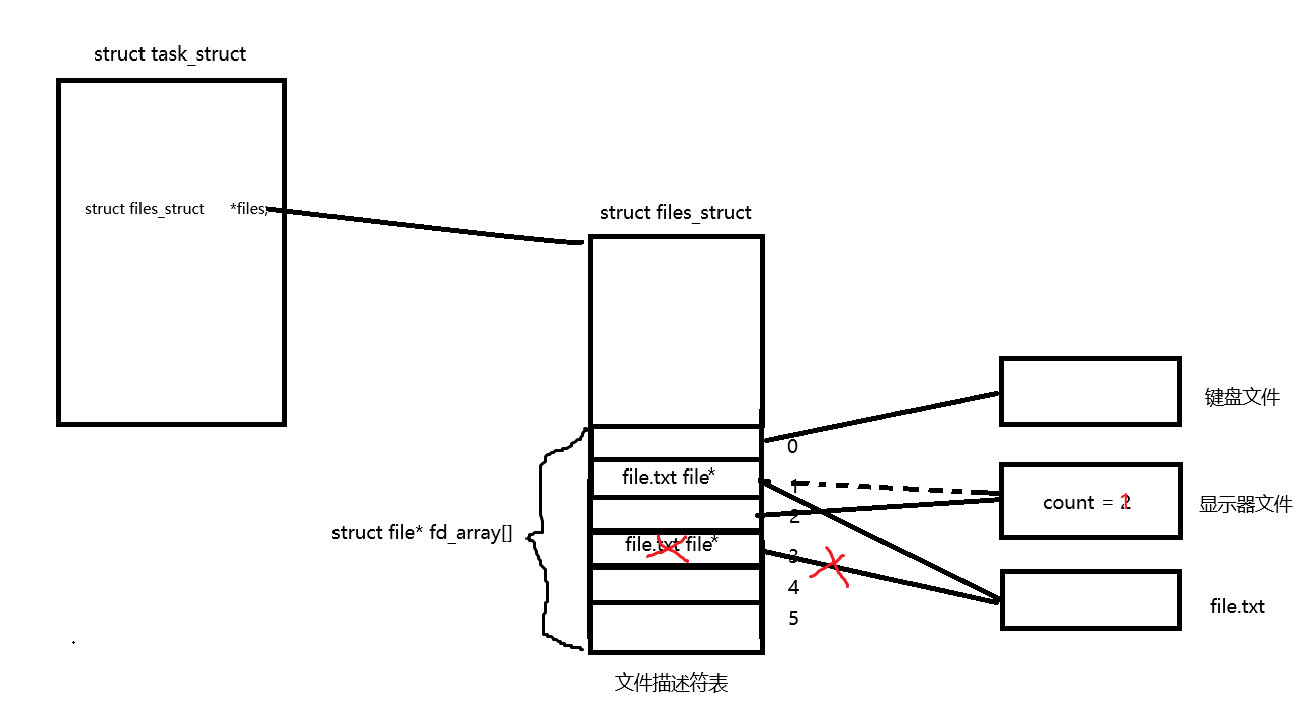 系统调用dup2的功能就是将oldfd(file.txt)这个下标所对应的指针数组内容跟复制给newfd(1号描述符)这个下标所对应的指针数组,然后关闭oldfd这个描述符,这样1号描述符就指向了file.txt文件。是不是感觉这个命名很奇怪?我也觉得,但是我们必须得跟着人家的文档走,不然没法使用这个系统调用接口。个人感觉:是因为在说英文的时候比较喜欢使用倒装句,语法习惯的问题。
系统调用dup2的功能就是将oldfd(file.txt)这个下标所对应的指针数组内容跟复制给newfd(1号描述符)这个下标所对应的指针数组,然后关闭oldfd这个描述符,这样1号描述符就指向了file.txt文件。是不是感觉这个命名很奇怪?我也觉得,但是我们必须得跟着人家的文档走,不然没法使用这个系统调用接口。个人感觉:是因为在说英文的时候比较喜欢使用倒装句,语法习惯的问题。
接下来我们来使用一下这个函数。
int main()
{
int fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0)
{
perror("open");
exit(1);
}
dup2(fd, 1);
char buffer[] = "hello buluo\n";
write(1, buffer, strlen(buffer));
close(fd);
return 0;
}

所以我们的输出重定向(>)就是通过这样的方式将本该输出到显示器上的内容输出到其他文件中,而我们的追加重定向(>>)也是这样的功能,方法就是将我们打开文件的选项进行修改即可。
int fd = open("file.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);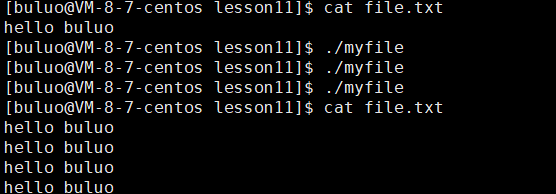
这样我们就实现了追加重定向,接下来我们再看看输出重定向。
int main()
{
int fd = open("file.txt", O_RDONLY, 0666);
if (fd < 0)
{
perror("open");
exit(1);
}
dup2(fd, 0);
char buffer[1024];
ssize_t s = read(0, buffer, sizeof buffer - 1);
if (s > 0)
{
buffer[s] = '\0';
}
printf("###:%s\n", buffer);
close(fd);
return 0;
}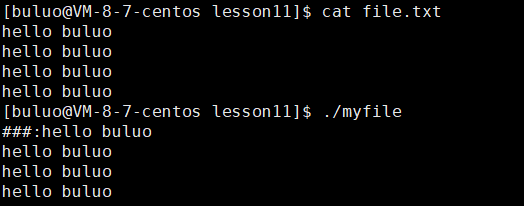
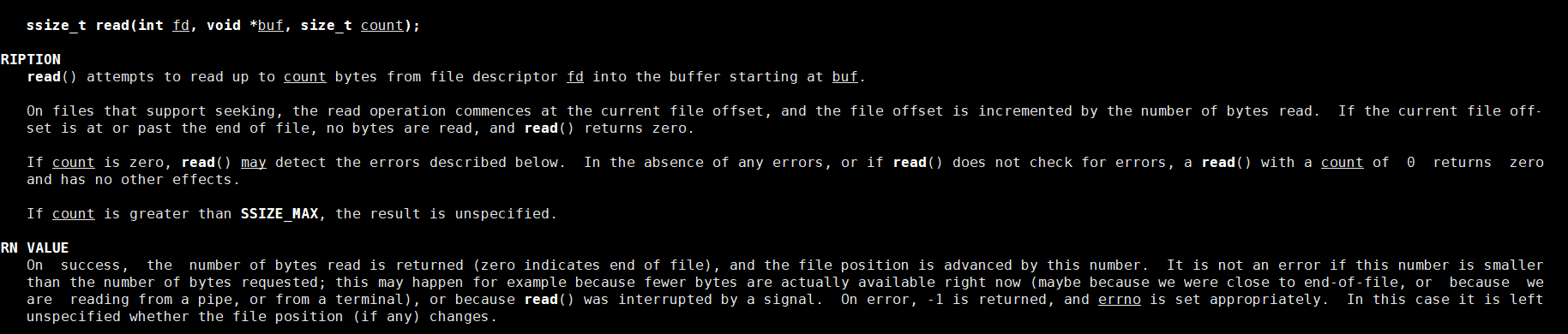
通过这样的方式,通过系统调用dup2,就可以将文件描述符表中的0号位置的内容替换为了新文件的地址,这样我们原本通过标准输入输入的内容,就直接从file.txt的文件中直接读取。还有一点就是针对read函数第三个参数为什么要减一?这是因为我们read函数的第三个参数表示我们此次读取要求读取多少字节数,而我们的返回值则代表我们实际读取的字节数,然而在我们的文件中并没有以'\0'作为字符串的结束标志,但是C语言有这样的规定,所以为了编程,我们在读取的时候需要减一,方便我们的程序在后面执行的时候可以维持C语言以'\0'作为字符串的结束标志的规定。
stdout和stderr的区别
现在我们再来谈一谈stdout和stderr的区别。
int main()
{
fprintf(stdout, "hello linux\n");
fprintf(stdout, "hello linux\n");
fprintf(stdout, "hello linux\n");
fprintf(stdout, "hello linux\n");
fprintf(stderr, "hello world\n");
fprintf(stderr, "hello world\n");
fprintf(stderr, "hello world\n");
fprintf(stderr, "hello world\n");
return 0;
}
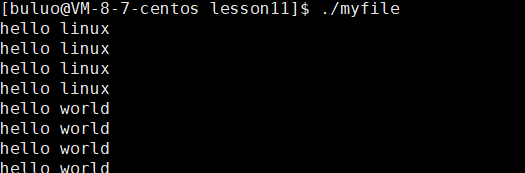
可以看到这个程序就是一个简单的打印语句,现在我们将其输出重定向到文件再看看。
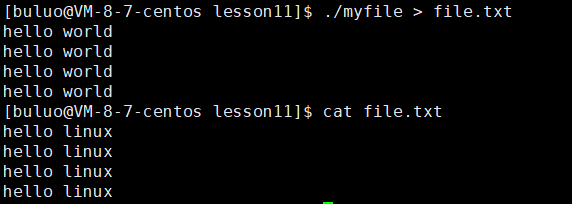
大家看到这结合上面输出重定向的理解应该可以反应过来,输出重定向就是将1号文件描述符的内容被新文件所取代了,所以stdout输出的内容都打印到了文件file.txt中,而stderr的文件描述符是2不受影响,所以会继续答应到显示器上,没有错,但是大家可能会好奇这两个又是往显示器文件中打印,为什么要占用两个文件描述符呢?有点多此一举的味道?这是因为当我们在做项目的时候,我们需要打印一些必要信息,这个时候就需要使用常规输出,但是也会有时需要我们打印一些我们程序中的错误信息,警告,调试信息等,这个时候就需要使用stderr,这样就常规输出和错误信息分开存储,方便我们调试。
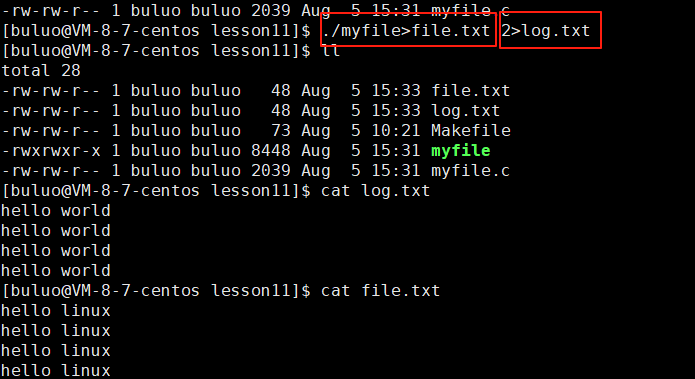
这样就将两个输出放到不同的文件中,如果我们想要对程序进程调式,直接去log.txt文件中获取即可。这就是stdout和stderr的区别。
Linux下一切皆文件
接下来我们来理解“Linux下一切皆文件”
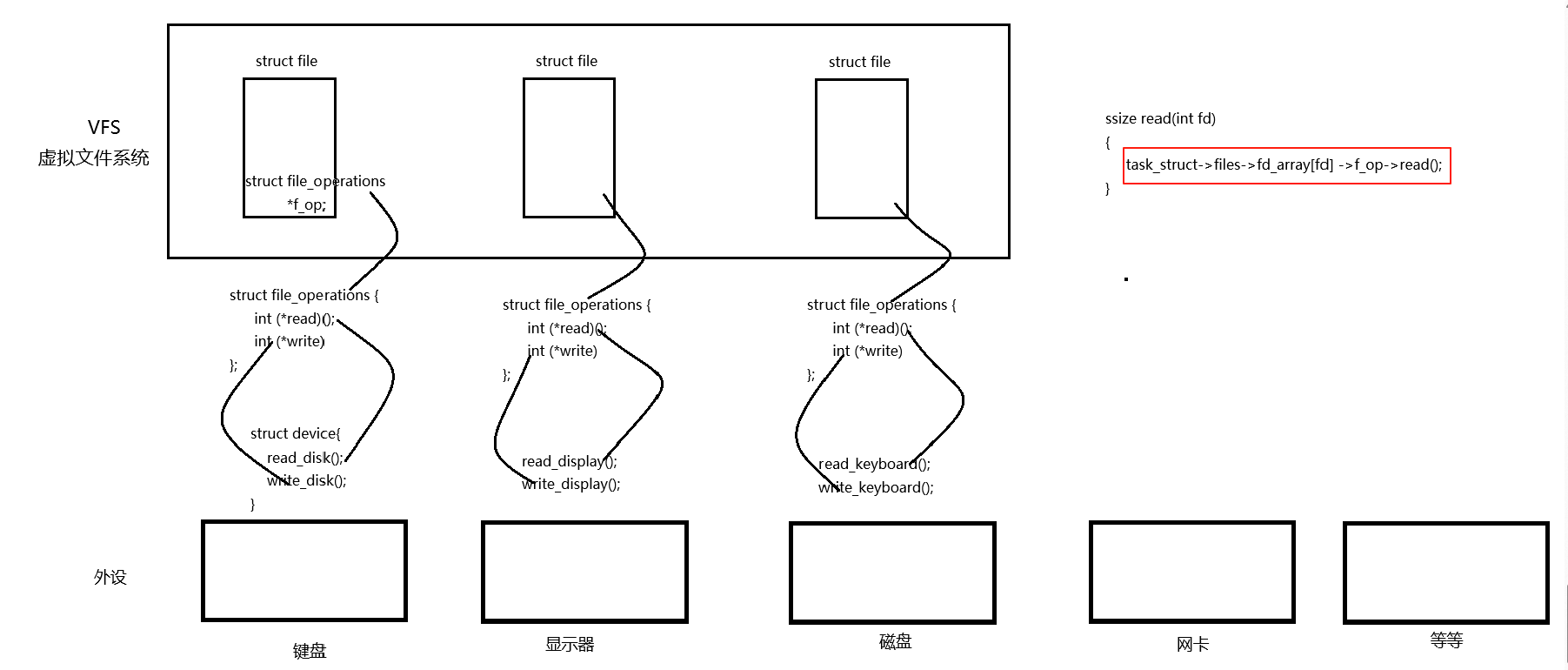
计算机通常配备多种外设(如磁盘、显示器、键盘、网卡等),虽然这些外设的读写功能的实现各不相同,但肯定都会提供相应的读写接口。因此操作系统为了统一管理这些外设,操作系统会为每个设备定义一个描述结构体(struct device),其中包含读写方法、状态标志等设备信息。
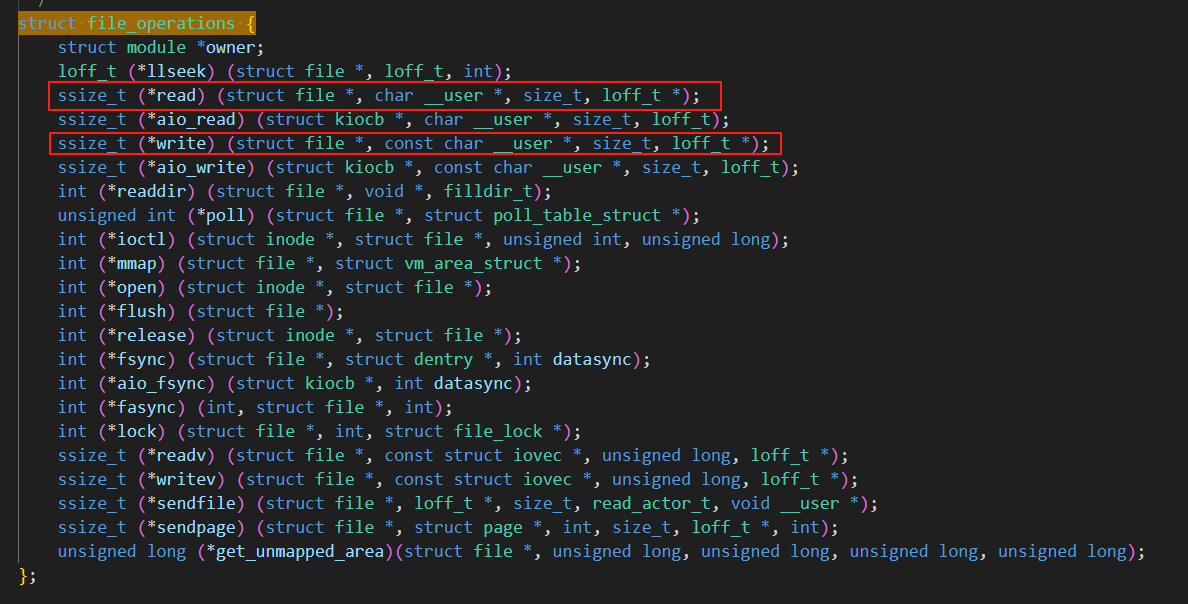
当进程打开设备文件时,内核会创建两个关键数据结构:struct file(表示打开的文件)和struct file_operations(包含文件操作方法)。系统会将设备结构体(struct device)中的读写方法映射到file_operations结构体中,从而建立文件与设备操作的关联。
最终,当我们调用read函数时,系统会通过以下方式找到对应的读写方法:task_struct->files->fd_array[fd]->f_ops->read,实现对外设的访问。
这种给我们的进程提供统一的系统调用接口,从而屏蔽底层具体的实现差异就是我们课本上所学的虚拟文件系统(VFS),所以我们每新增加一种外设,只需要将其读写方法的具体实现映射到struct file_operations中,这样我们的进程通过文件描述符,找到对应的文件(struct file),再通过struct file 中定义的成员变量f_ops(file_operations就可以对其进行读写调用了。
C标准库缓冲区机制与系统调用输出差异
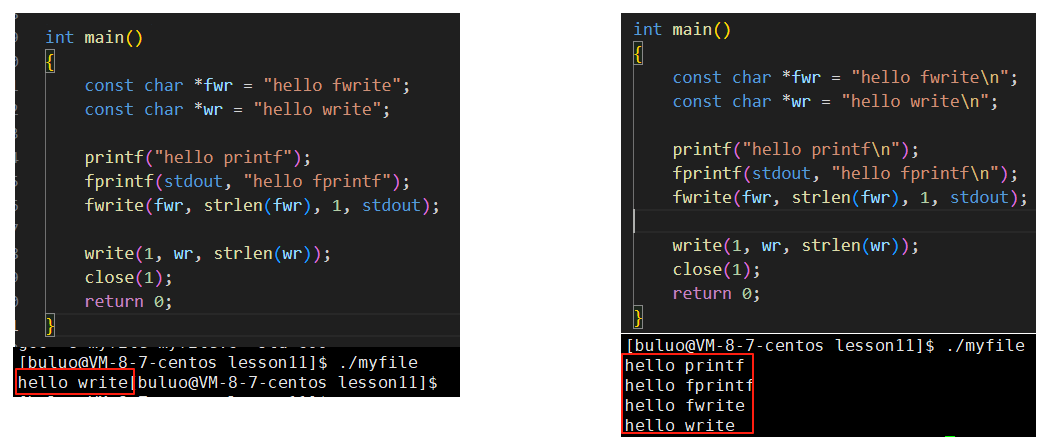
大家看上去有没有觉得好奇怪,为什么这两段代码只是增加了一个'\n',为什么C语言自带的接口就打印不出来了,而我们的系统调用接口还能打出来呢?如果大家觉得这个奇怪,那么别着急,更加奇怪的事情还在后面,往下看
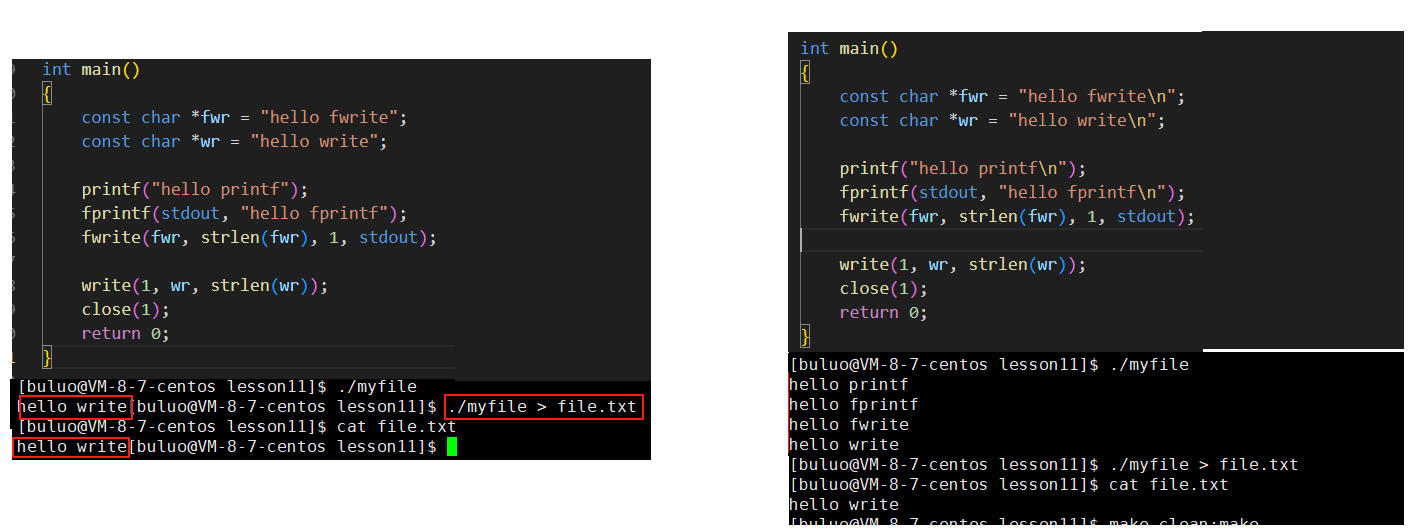
看完这个就更加懵逼了,当我们将这两个的输出结果重定向到文件中的时候,第一个还可以勉勉强强接受,毕竟在显示器打印的时候就只有一个系统调用的输出结果,重定向到文件中的时候一个结果也可以接受,但是第二个我就有点不能接受了,为什么在显示器打印的时候都打印出来了,一旦重定向到文件中的时候就变成这个样子了,是不是这个编译器偷工减料了?哈哈,不要着急,大家接着往下看,这个现象是少了打印,接下来就更奇怪了。
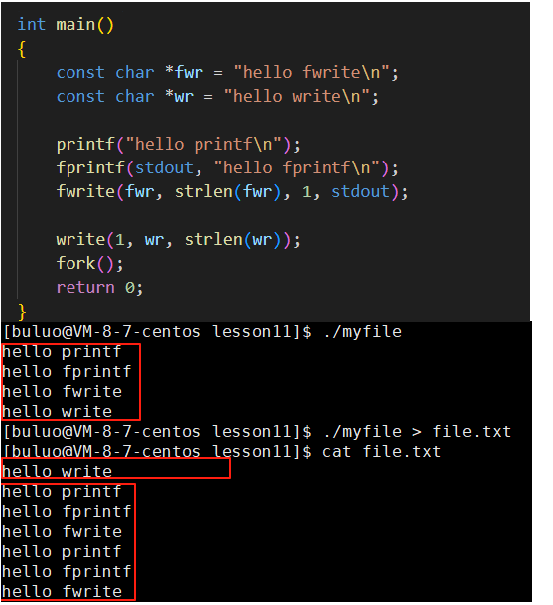
这又是怎么回事?显示器打印的内容是符合我的预期的,但是往文件中重定向的时候我就不是很理解了,fork()不就是创建了一个子进程么,但是他不是在打印内容之后才创建的子进程的么,为什么重定向到文件的时候,子进程好像还回头执行了,而且回头执行就算了,这个子进程还挺叛逆,挑着内容执行呢,C语言的接口有执行了一次,系统调用的接口就不执行,叛逆的很!!!好了,现在我们有了直观感受,接下来我们就来好好分析一下这是什么原因导致的。
大家在看完我之前关于文件的博客后,其实现在可以明白一点就是我们的C语言在底层都是封装了我们的系统调用,因此像fwrite/printf/fprintf/fputs...这些接口在底层都是调用了write这个系统调用接口,那么归根结底都是调用了系统调用接口,那么为什么会有上面如此的差异呢?其实上面这一切的原因就是我们老师在教我们C语言时经常讲到的缓冲区。现在我们在这里就可以真真切切地了解一下这个缓冲区了。其实从上面的例子我们就可以感觉出来,这个缓冲区只是针对C语言提供的接口才有效果,而对我们的系统调用接口并没有什么用。所以,现在我们就可以大胆猜测这个所谓的缓冲区其实就是C语言给我提供的一个缓冲区而已
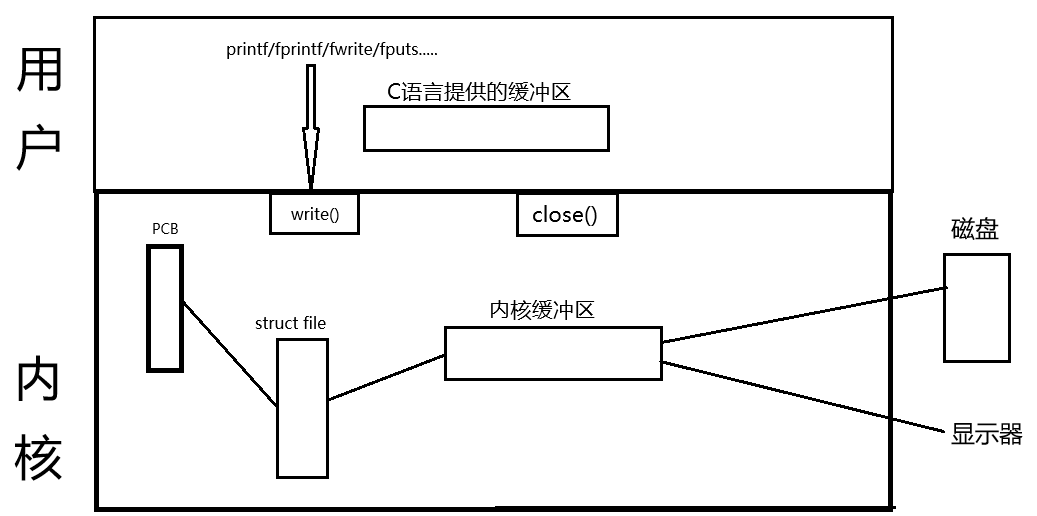
所以每当我们通过C语言的文件接口进行调用的时候,我们首先会将数据放在C语言给我们提供的缓冲区内,当我们的程序运行结束的时候,我们就会将C语言中缓冲区的内容交给我们的内核缓冲区,最后由操作系统替我们输出,但是当我们在程序结束之前一旦使用close这个系统调用接口,我们的操作系统就直接关闭掉这个文件,因此内核缓冲区也就随之销毁了,这个时候还在用户区的缓冲区中的数据再想向内核缓冲区写的时候就已经没有用了,因为内核缓冲区都已经关了,所以用户区的缓冲区就只能吃闭门膏了舍弃掉那些数据了,所以我们在打印的时候并没有将C语言缓冲区的内容打印出来。这个时候就有人说,那不对呀,为什么在增加一个'\n'的时候往显示器打印的时候它们能打印出来呢?很好的一个问题,这个问题的答案就与缓冲区的刷新策略有关了。
缓冲区的刷新策略
缓冲区的刷新策略:
-
无缓冲:数据立即写入目标设备,不经过缓冲区。
-
行缓冲:当遇到换行符(
\n)或缓冲区满时,数据会被刷新。例如,在显示器文件下通常是行缓冲的。 -
全缓冲:只有当缓冲区满或显式调用刷新函数时,数据才会被写入目标设备。例如,文件操作通常使用全缓冲。
这就是我们的缓冲区的刷新策略,当我们向显示器文件进行输出的时候,用户区缓冲区一旦检测到'\n'就会将我们的文件输出到显示器上,而当我们将我们的数据向普通文件进行写入的时候,刷新策略就变为了全缓冲,只有当缓冲区满或显式调用刷新函数时,才会刷新,所以我们在增加'\n'之后向显示器进行写入的时候,C语言的文件接口就被打印出来了;而向普通文件进行写入的时候,却只打印出了系统调用接口的内容,原因就是提前关闭了内核缓冲区,导致用户区缓冲区没有写入。
缓冲区的由来
那么为什么要有这个缓冲区呢?
首先,我们先确认一个共识就是,在我们之前为什么要发展计算机呢?在战争年代,计算机的作用就是传输数据(首长给地下的部队传送重要指令),以及窃取敌军数据等等,总的来说,计算机就是为了让我们的军队可以进行很好的联络,在我们上个世纪末的时候,我们之所以发展计算机,就是为了通信,让我们远在千里的朋友或者亲人可以收到我们的消息,而现在,我们的计算机已经不止是实现通信的作用了,还可以给你们提供看电视,玩游戏等娱乐设施,看似没有通信,其实你在玩游戏的时候也是在访问对应游戏厂商的服务器罢了,只是你没多大感觉而已,总的来说就是我们的计算机天然就是为了给我们通信的。
所以大家在看到这个缓冲区的时候可能会觉得这么这么麻烦,我写个数据,这个还要这么多的缓冲区,我直接就这个数据传递过去不久行了,弄这么多缓冲区多此一举。就像我写程序直接调用printf函数就可以输出多快,所以这个缓冲区没有必要么。我相信肯定有同学是这么想的,但是我们往往想的过于简单了,现在我给大家列举一个生活中的例子大家就可以明白了。
不知道大家有没有寄过快递,没寄过的同学找个时间寄一下,假如现在你有5个箱子的东西需要寄给你的好朋友,现在需要你将这些东西从你家搬到离你家50米处的菜鸟驿站,那么你会选择来回5躺,1次搬1个吗?我觉得咱们作为新时代的懒洋洋肯定不会这么干,大家肯定会选择找个小推车将这5个箱子放上去,然后1次推到菜鸟驿站,然后让菜鸟驿站帮你将这些东西送给你的好朋友,所以这就是为什么要有缓冲区了,大家都尚且知道来回搬5次太麻烦,不高效,操作系统何尝不知道,所以它也想一次性将你的数据全部交给内核缓冲区,这就是为什么我们要有缓冲区,而我们的内核为什么也有缓冲区,这就好比菜鸟驿站可能会一收到你一个人的包裹就送出去吗?肯定不会,它要是这么干了,没干两天他就得倒闭了。所以它肯定会等一堆人的包裹,直到等的差不多一车的量的时候就将这些包裹运输出去。
C标准库缓冲区
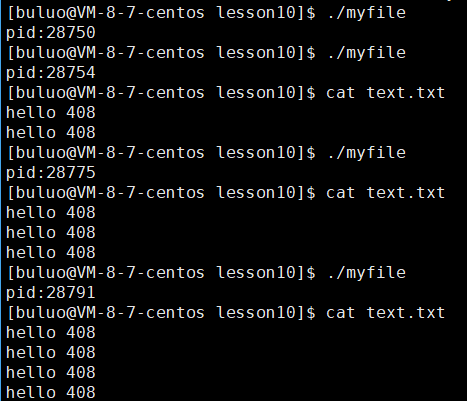
现在我们就来看看C语言给我们提供的缓冲区具体是什么样子的。
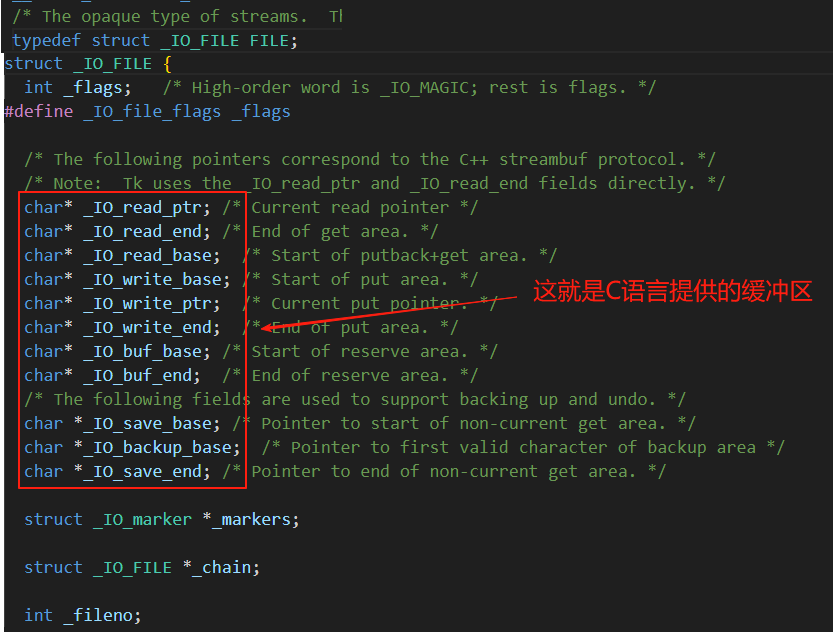
了解了上面这部分内容,相信fork()之后为什么向显示器打印和向文件打印的结果不一样,大家应该对这个问题的答案一清二楚了,这个答案就是因为我们向文件进行打印时,我们的刷新策略变为了全缓冲,所以我们在fork()之后,我们的父子进程代码数据首先会共享,当我们的父子进程通过进程调度之后,无论谁先结束,都会将缓冲区的进程刷新到内核缓冲区,刷新之后,缓冲区的内容被清空,所以刷新的时候也相当于写入的过程,一旦发生写入,父子进程代码共享,数据就会进行写时拷贝,所以,在子进程的缓冲区中也会有相同的数据存在,所以这两个父子进程在退出之前,都会将直接缓冲区的内容刷新到内核缓冲区,所以这就导致C语言的文件接口的数据被打印了两次。而当我们向显示器打印的时候,缓冲区的刷新策略是行刷新,所以我们的数据会立马刷新到磁盘上,所以缓冲区已经没有数据了,因此fork()之后子进程的缓冲区中也是没有数据的,所以显示器文件打印的时候只打印了一份。
所以这也就是在我之前博客介绍exit()和_exit()时,为什么C语言提供的接口exit()函数在退出的时候会将数据全部打印出来之后再退出,而我们的系统调用接口_exit()函数并没有将数据全部打印出来而是直接退出了。这就是因为我们调用的C语言的接口函数,当使用C语言的接口exit()函数会将其加载到内核缓冲区,再由操作系统将其打印出来,而我们操作系统给我们提供的接口函数_exit()属于内核,并不关心这个用户的缓冲区,所以就会直接退出。
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/2302_77620024/article/details/150511139

