
Sergey Levine:机器人的落地周期将快于自动驾驶,具身的发展会复制大语言模型的路径;关于数据飞轮和未来行业格局的讨论
Youtuber Dwarkesh Patel和Sergey完成了长达一个半小时的深度访谈。Sergey讲了他对机器人行业的预期、数据的判断以及对行业争议问题的观点。值得关注的是他对人类学习方式和LLM发展细致入微的观察。对于PI的分析,请见系列文章:
看 PI 创始人Sergey Levine 如何解决VLA的核心难题之一:语言跟随问题
Sergey Levine:非真实数据的阿喀琉斯之踵,任何人设计的组件都会形成瓶颈,而非真实数据本质上就是人类的设计
PI系列解读| 机器人也可以点蜡烛?实时分块技术:告别机器人“卡顿”
PI系列解读|让机器人清理你的家!Π0.5让具身在陌生环境泛化成为可能

总结:
大规模部署机器人的时间线
机器人仍需解决灵巧操作、理解人类意图以及持续学习问题
机器人会在一个小范围可用的时候在真实世界部署并且持续学习;现在要做的事情是在小范围的情况下让机器人先被用起来
机器人相比于LLM反倒更容易做human in the loop下的迭代,因为人可以更容易指出机器人的问题
机器人的发展路径会复制LLM,先解决小部分问题,后来可以自主的解决问题
机器人的突破不需要新的理论突破,只需要现有方法的综合,预估5年机器人能自主完成很多工作
机器人硬件在不断降本,背后的推动力是规模化、技术进步和AI发展对硬件精度要求的下降。目标是找到 “最小可行配置”:功能足够、成本最低的硬件方案。未来不会有一个“万能机器人”,而是不同需求对应不同硬件组合。
机器人可能比自动驾驶发展得更快
技术基础不同:2009 年自动驾驶起步时,机器学习系统的感知能力非常差,能做演示但无法泛化;2025 年已经有了可泛化、鲁棒的感知技术,以及 LLM、VLM 这种具备常识推理的系统,起点远好于当年,且可以在常识中学习
试错成本不同:自动驾驶的错误代价极高(可能导致事故),几乎不能靠试错学习;机器人操作的很多任务允许出错和修正(比如洗碗、折衣服),错误的成本可控,适合通过试错逐步改进。
具身所需要的数据量
具身的数据量:是和多模态训练用的数据集比,差距大概在一到两个数量级之间。
Sergey认为,更重要的不是“要多少数据才能彻底完成”,而是“要多少数据才能真正开始一个数据飞轮”。
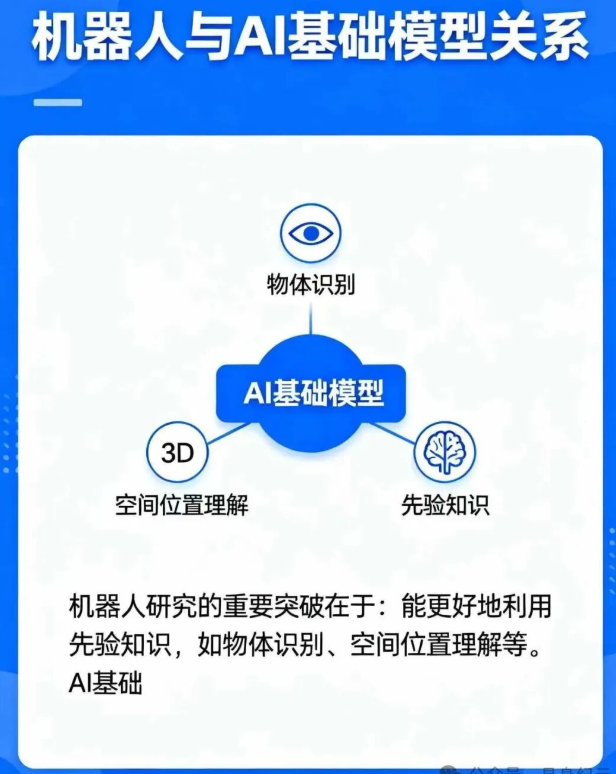
具身智能发展与AI基础模型的关系
机器人研究的重要突破在于:能更好地利用 先验知识(prior knowledge),如物体识别、空间位置理解等。
多模态学习的挑战与价值
视频模型不如语言模型鲁棒:视觉基础模型还未真正理解物理世界;文本天然是抽象表示,信息密度更高,语义更聚焦,更容易直接迁移到复杂任务。
机器人具身性带来聚焦机制当机器人有具体任务时,它的感知会被任务目标引导,不必关心与任务无关的干扰信息。类似人类的“隧道视野”:与目标无关的信息会自动被忽略
视频数据在机器人中的作用:单靠“被动看视频”不足以让机器人学会任务,就像人类光看体育比赛并不能学会打网球。;任务目标 + 视频数据 才能让模型知道关注什么,从而有效学习,而前者是真实数据才能获得的效果。真机数据可以帮助更好的利用视频数据
具身智能的涌现
涌现能力并不是单纯因为互联网数据量大,而是因为当泛化达到一定程度时,它就会表现出组合性,在具身智能领域已经体现
PI目前并没有给机器人操作更多的记忆和上下文信息,因为熟练的动作(如奥运游泳运动员的动作)本质是“当下”的反射式执行。目前重点是先实现人类级的灵巧性和身体熟练度。
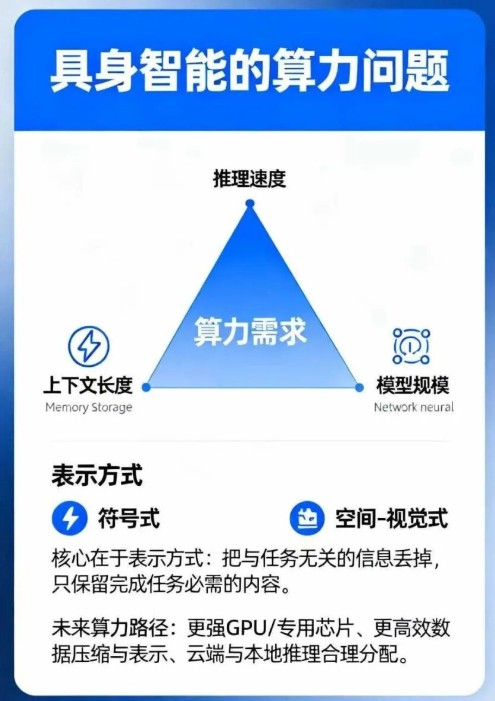
具身智能的算力问题:具身智能的算力三难困境推理速度、上下文长度和模型规模,提升三者意味着较强的算力需求
核心在于表示方式(representation):人类记忆可以是符号式(购物清单)或空间-视觉式(街景);机器人也需要找到合适的表示,把与任务无关的信息丢掉,只保留完成任务必需的内容。未来可能出现新的模态(不局限于图像+文本)
人脑的启示:人脑的优势可能不是硬件算力,而是极度并行化;大脑同时处理:长期记忆、短期空间感知、语义信息、即时感知和规划,并以不同速度并行运行
未来算力的可行路径:依赖更强的 GPU/专用芯片;更高效的数据压缩与表示(只抓住关键信息,而不是存全量感知流)。云端和本地推理合理分配;部分实时环节只消耗少量算力
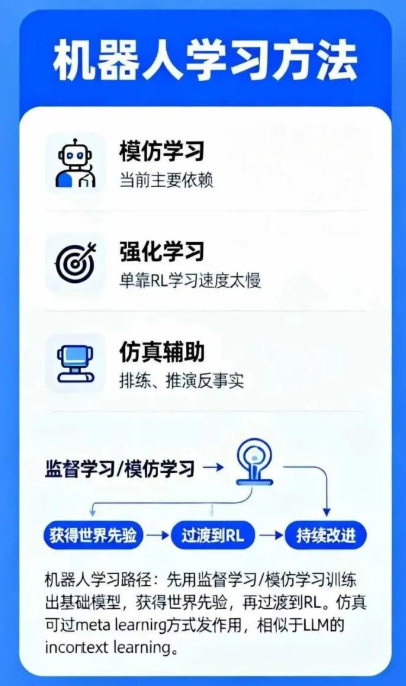
模仿学习、强化学习和仿真:
为什么当下更依赖模仿学习而非强化学习:机器人如果没有任何先验,单靠 RL 学习速度太慢。先用监督学习/模仿学习训练出基础模型,获得世界先验,再过渡到 RL。这和 LLM 的发展路径类似:先大规模文本预测,再用合成数据与 RL 微调。
仿真无法真正学习真实世界意图,只能排练、推演反事实(counterfactual),而不是创造新世界知识。
仿真并非无用,但要发挥作用,前提是模型在真实世界上已经具备足够的基础。在真实数据的基础上,VLA可能像LLM一样涌现出通过in context learning表现出的meta-learning的能力,这是仿真发挥作用的基础
具身行业未来的竞争格局
目前还没有类似英伟达在机器人领域的绝对主导者。Sergey 更希望看到一个多样化、平衡发展的机器人生态。
机器人硬件的核心瓶颈:成本、可靠性都很重要;到目前为止,AI 还没把机器人硬件逼到极限。
不能只关注 AI,本质上需要整体思考:包括硬件、基础设施和制造环节。Physical Intelligence 也在同时规划 AI 路线和硬件路线。
Dwarkesh Patel:今天我和 Sergey Levine 聊天,他是 Physical Intelligence 的联合创始人,这是一家做机器人基础模型的公司。他同时还是加州大学伯克利分校的教授,也是全球在机器人学、强化学习和人工智能领域的顶尖研究者之一。Sergey,非常感谢你来上我的播客。
大规模部署机器人需要多久的时间
Dwarkesh Patel:我们来聊聊机器人。在我开始连珠炮式提问之前,能不能先请你给大家做个总结,介绍一下 Physical Intelligence目前的发展情况?你们公司成立到现在刚好一年,这段时间进展如何?主要在做些什么?
Sergey Levine:Physical Intelligence** 的目标是打造机器人基础模型(robotic foundation models)。简单来说,就是一种通用模型,原则上能够控制任何机器人去完成任何任务。**我们关心这个方向,是因为我们认为这是 AI 中最核心的问题之一。机器人几乎涵盖了所有 AI 技术,如果你能让机器人真正实现通用性,那基本上就能完成大部分人类所做的工作。 目前我们的进展是,很多基础性的部分已经搭建起来了。这些基础其实很酷,也运作得相当不错。比如,我们可以让机器人叠衣服,可以让它进入陌生的家庭并尝试清理厨房。但在我看来,现在 Physical Intelligence所做的还只是非常早期的起点——只是把基本积木搭好,为后面解决真正艰难的问题打下基础。
Dwarkesh Patel:如果按年份来设想未来呢?现在已经过了一年,我有机会看了你们的机器人,它们能完成一些非常灵巧的任务,比如用夹爪折纸箱。老实说,就算用我的手折纸箱也不容易。那如果逐年往前推演,直到出现全面的机器人爆发,每一年需要解锁的关键点是什么?
Sergey Levine:我们需要解决几件事。
-
灵巧性显然是其中之一。最开始,我们必须确保我们的方法能够应对人类能完成的那类复杂任务。正如你提到的,折纸箱、折叠不同种类的衣物、清理桌子、做一杯咖啡。这类任务我们现在基本能做到,效果也挺不错。
-
理解人类意图。但最终目标不是叠一件好看的 T 恤,而是验证我们的初始假设:这些基础是扎实的。在此基础上,还会面临一系列重大挑战。很多时候结果被浓缩成一个三分钟的视频,观众看了就以为“哦,这就是你们做的”。但不是的,那只是一个非常初级的版本,远不是未来真正的样子。你真正想要的机器人,不是你告诉它“帮我折一下 T 恤”,而是告诉它:“嘿机器人,你要帮我处理家务。我希望每天 6 点准备好晚餐,早上 7 点我上班前要整理好,周六帮我洗好衣服。另外,每周一记得和我确认一下,这周去超市需要买些什么。”这才是真正的指令。而机器人需要在六个月、一年,甚至更长的时间里,持续把这些事做好。最终的规模会大得多。
-
持续学习与常识。机器人必须能持续学习,理解物理世界,具备常识,并且在需要时能自己去获取更多信息。比如我说:“今晚你能不能做这种沙拉?”它就要能搞清楚这意味着什么,去查资料、买到食材。这当中需要常识,需要理解特殊情况并做出合理应对,需要不断改进,也需要懂得安全,在关键时刻可靠,并在犯错时能修正自己。这些都远比折衣服复杂。但核心原则是:要能够利用先验知识,并且要有正确的表征方式(representations)。
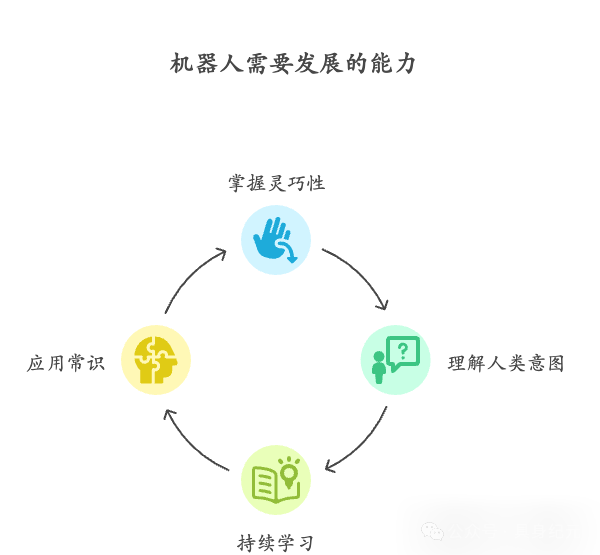
图注:机器人需要发展的能力
Dwarkesh Patel:那这种宏伟愿景,大概是哪一年能实现?如果你要给出一个估计,25 百分位、50 百分位、75 百分位分别是多少?
Sergey Levine:我认为这不会是“我们在实验室里把一切研发完成,然后到 203X 年推出一台机器人”这样的过程。它会更像 AI 助手:一旦达到某个基础可用水平,机器人能提供一些真正有用的功能,它就会被投放到真实世界。而一旦进入真实世界,它就能积累经验,并利用这些经验不断变得更好。所以对我来说,我关注的时间点不是“什么时候彻底完成”,而是“什么时候飞轮开始转动”。
Dwarkesh Patel:那飞轮什么时候启动?
Sergey Levine:可能很快。这取决于一些决策。权衡点在于:范围越窄,就能越早投放到真实世界。我们已经在探索哪些任务是机器人真的可以完成的,可以让飞轮先转起来。但要说那些你真正会在意的事,我觉得个位数年是很现实的。我当然希望一两年内就能有东西出来,但很难说。
Dwarkesh Patel:那“有东西出来”具体是什么意思?
Sergey Levine:意思是会有一个机器人,能完成一件你真正关心、你真正需要完成的任务。它做得足够好,能够真正帮到你。
Dwarkesh Patel:我们已经有大规模部署的 LLM 了,但并没有形成所谓的飞轮。至少从模型公司的角度看,并没有出现“Claude 学会了做经济里的所有工作”或者“GPT 学会了做所有工作”。为什么飞轮没有运转起来?
Sergey Levine:其实已经非常接近了,而且我百分之百确定,很多机构正在做这件事。严格来说,现在已经有一个飞轮了。只不过它不是完全自动的飞轮,而是“人类在环路中的飞轮”(human-in-the-loop flywheel)。所有部署 LLM 的人都会观察它的表现,然后利用这些反馈去改进。这件事很复杂,因为涉及到表征问题(representation),要找到合适的方法来提取监督信号,并将这些信号与系统的行为对应起来,从而朝着目标方向改进。我不认为这是不可能解决的问题,只是在细节上比较棘手,在算法和稳定性上有挑战。整个社区花了不少时间才逐渐摸到门路。
Dwarkesh Patel:那你觉得机器人会更容易吗?还是说利用真实世界数据做标注、当作奖励的这些技术,会让整个领域一同进步,机器人也受益?还是说机器人会额外受益?
Sergey Levine:我不认为机器人和 LLM 在本质上有特别大的不同。但有一些细微差别让机器人更容易管理。尤其是当机器人和人类合作时——无论是人类监督还是指挥机器人——人类都是一种天然的监督来源。人们有很强的动力去帮助机器人成功。另外,在很多动态过程中,机器人可以犯错、纠正错误、反思,并避免下次再错。这种情况在物理操作里比在回答问题时更常见。比如一个 AI 助手答错了问题,它没办法“回头修改”,而且听答案的人可能根本没意识到出错了。但如果机器人叠 T 恤叠错了,大家一眼就能看出来。它可以反思,理解错误原因,然后改进。

图注:人机协作
Dwarkesh Patel:好,假设一年后我们有机器人能做一些有用的事。比如执行一些相对简单的循环任务,比如不停地折纸箱。这样飞轮就开始转动了。但再往后,你想要的是一个能像人类保姆一样完全管理家庭的机器人。这两者之间的差距有多大?
Sergey Levine:其实和 LLM 的发展很像。关键在于任务范围。想想代码助手。最早它们只能做简单的代码补全。你给一个函数签名,它试着帮你写完整个函数,但可能只有一半是对的。随着能力提升,你开始愿意让它承担更多自主性。现在最好的代码助手,如果任务比较公式化,它能帮你生成大部分的 PR(Pull Request)。机器人也类似。随着能力增强、常识提升、任务范围扩展,我们会逐渐扩大它的工作范围。最初它可能只会做一件事,比如冲咖啡,然后它会越来越强大,最终能管理整个咖啡馆。

Dwarkesh Patel:我明白这是一个连续谱,不会有某个瞬间突然“达成”。但如果要你给个中位数年份的估计,什么时候能做到?
Sergey Levine:我觉得还是个位数年,而不是两位数年。难点在于,跟所有研究一样,它取决于几个关键问题的突破。我认为这些问题不需要全新的理论,而需要对现有方法的正确综合(synthesis)。不过要说明的是,综合可能和创新一样困难,同样深刻、同样需要智慧。但我们大概已经知道拼图的碎片,接下来就是把它们拼好。如果顺利,个位数年是合理的。
Dwarkesh Patel:那我就用二分查找来逼你给个年份。少于 10 年,但多于 5 年?你的中位数估计是多少?
Sergey Levine:
我觉得 5 年是个不错的中位数。
Dwarkesh Patel:好,5 年。如果 5 年后机器人能完全自主管理家庭,那它们也能完成大部分体力劳动。你的估计是,5 年内机器人应该能完成经济中大多数蓝领工作?
Sergey Levine:这里有一个细微的区别。如果用代码助手做类比就更清楚了。今天的代码助手不是突然某天取代了所有程序员。最大的生产力提升其实来自专家——也就是程序员——因为他们的工作被这些强大工具增强了。
Dwarkesh Patel:撇开“人会不会被替代”这个问题,另一个问题是:5 年后的经济影响会是什么?我之所以好奇,是因为 LLM 的营收和能力之间存在某种“错位”。模型看起来像 AGI,可以流畅对话、通过图灵测试、能做很多知识工作,显然在写代码等方面也很强。但这些 AI 公司的总营收才 200-300 亿美元,而知识工作市场是 30-40 万亿美元。那 5 年后机器人会不会也处于类似情况?还是说它们会在各处部署,真正做大量实际工作?
Sergey Levine:这是个非常微妙的问题。最终关键还是范围(scope)。LLM 没有取代全部软件工程,是因为它们只在某些范围内表现出色。但这个范围正在逐年扩大。我认为机器人也一样。最初的范围会很小,因为有些事情它们做得很好,但另一些仍需要大量人工监督。随着范围扩大,生产力就会提高。一部分生产力直接来自机器人本身的价值,另一部分来自人类因使用机器人而获得的效率提升。
Dwarkesh Patel:但很多工具都能提高生产力,比如戴手套。我想知道的是:什么样的东西能让生产力提高 100 倍,而不是小幅提升。现在 LLM 对知识工作的覆盖率,从收入占比看,大概只有 1/1000。你的意思是,机器人在 5 年后能覆盖类似比例的体力劳动?
Sergey Levine:这是个很难直接回答的问题。我没法现在就告诉你机器人能完成劳动的百分之多少,因为我不可能临时给出整个体力劳动市场的横截面分析。但我能说的是:在“人类在环”场景下更容易落地。这和代码助手类似。未来我们会看到更多“机器人 + 人类”的模式,这会远好于“纯人类”或“纯机器人”。这种模式不仅合理,而且让技术更容易启动。因为在人机协作中,机器人还能在工作中学习,获得新技能。
Dwarkesh Patel:因为人类能给它打标签?
Sergey Levine:不仅如此,人类还能帮助它,给它提示。我举个例子。去年四月我们发表 π0.5论文时,最初是通过远程操控控制机器人,在不同场景中收集数据。但后来我们发现,当模型的能力基础足够时,不需要仅靠底层动作来监督,直接用语言指令也能带来显著提升。当然,你需要一定的能力基础。但一旦有了,就可以直接站在机器人旁边说:“好,现在把杯子拿起来,放进水槽,把盘子也放进水槽。”光靠语言,就能为机器人提供有用的信息,帮助它不断变好。 想象一下这对“人机互动”的意义。学习就不仅仅来自原始动作,还可以来自语言。最终它还能从观察人类行为中学习,从与人类合作时获得的自然反馈中学习。而这正是大模型先验知识能发挥巨大价值的地方——它让机器人理解这种互动动态。所以,“人机结合”的部署方式有巨大的潜力,让模型进化得更快。
Dwarkesh Patel:好的,再回到大局。我想弄清楚机器人经济什么时候能部署,因为这关系到 AGI 的速度。比如到 2030 年,AI 投资的电力消耗可能是 100-300 吉瓦,每年资本开支是几万亿美元。要建数据中心、芯片厂、光伏厂。我很想知道,到那时机器人经济是否成熟,能显著帮助建设这些基础设施。
Sergey Levine:这是个很酷的问题。你基本上是在问:“我现在要买多少混凝土,到 2030 年建好数据中心,供机器人使用?”好消息是:机器人可以帮你建。
Dwarkesh Patel:但那时它们真能行吗?毕竟不仅要建机器人,还要建机器人工厂。这是整个产业链的爆炸。
Sergey Levine:原则上能帮很多。别把机器人想成人的机械版,它们可以是推土机、汽车,甚至 100 英尺高,或者很小。如果 AI 足够聪明,就能驱动各种异质机器人系统。这会极大提升生产力,也能解决一些人类难以完成的问题。比如数据中心可以建在非常偏远的地方,因为机器人不需要考虑购物中心近不近。
Dwarkesh Patel:那 2030 年全球会有多少机器人?
Sergey Levine:很难说。规模经济还没完全体现出来。但成本在急速下降。比如 2014 年 PR2 机器人 40 万美元;我后来买的机械臂 3 万美元;我们现在用的机械臂只要 3000 美元,而且还能更便宜。
Dwarkesh Patel:这是什么原因?
Sergey Levine:部分是规模效应,部分是技术进步,部分是 AI 降低了硬件精度要求。传统工业机器人要极高精度,但如果有廉价的视觉反馈,就不需要那样的硬件精度。AI 让机器人更便宜。
Dwarkesh Patel:你觉得这种下降会持续吗?比如十年内移动机械臂会只要几百美元?
Sergey Levine:这问题更适合问我的联合创始人 Adnan Esmail。他可能是全球最合适的人来回答。但就我个人经验,每年的成本下降都超出我的预期。
Dwarkesh Patel:
现在世界上大概有多少机械臂?超过一百万吗?
Sergey Levine:我不知道。而且这问题也有点 tricky,因为工厂里的机械臂不是我们要考虑的那类。
Dwarkesh Patel:我指的是你们希望用来训练的那类。可能不到十万?
Sergey Levine:大概吧。
Dwarkesh Patel:可我们需要的是数百万甚至数十亿机器人。如果真要支撑 AI 爆炸,不仅需要机械臂,还需要能移动的机器人。到那时真能生产得出来吗?
Sergey Levine:只要有足够需求,经济就能做到。2001 年世界上有多少 iPhone?几乎没有。几年后就爆发了。研究者要思考的是:AI 如何影响硬件设计。有些特性必须要,比如别老坏。另一些则是疑问,比如到底要几根手指?你之前也说过,两根手指能做很多事。找到功能足够的最小配置很重要。还有些可能根本不需要,比如极高精度,因为反馈能弥补。
我现在的目标是找出“最小可行配置”。我不认为未来会有一个“万能机器人”,更可能是满足不同需求的机器人组合。就像智能手机必须有触摸屏,但其他功能因需求和成本不同而异。一旦我们有了强大的 AI,可以赋能任何机器人达到基本智能,不同厂商就能在硬件设计上各显神通。
为什么机器人要比自动驾驶发展得更快
Dwarkesh Patel:那为什么机器人不会像自动驾驶那样,拖了十几年?Google 2009 年就启动了自动驾驶计划。我记得小时候看过演示,车子开到 Taco Bell 买东西再开回来。可直到现在才真正部署,而且还会出错。也许再过十几年,大部分车也还是不能自动驾驶。你说 5 年能达到很强的机器人,但会不会其实要 20 年?5 年后有了酷炫演示,再过 10 年才像 Waymo 或特斯拉 FSD 那样真正落地?
Sergey Levine:这是个很好的问题。现在和 2009 年相比,有一个重大区别:机器学习系统的感知能力。对自动驾驶来说,感知是关键;对机器人来说,除了感知,还有其他方面。但 2009 年的感知水平真的很差。问题在于,感知是那种可以做一个漂亮演示的东西,但一旦要泛化,就会撞墙。而今天,在 2025 年,我们已经有了更强的、可泛化且鲁棒的感知技术,以及更广义上的、能理解周围世界的可泛化鲁棒系统。在机器学习里,“可扩展”其实意味着“能泛化”。这给了我们一个比当年好得多的起点。
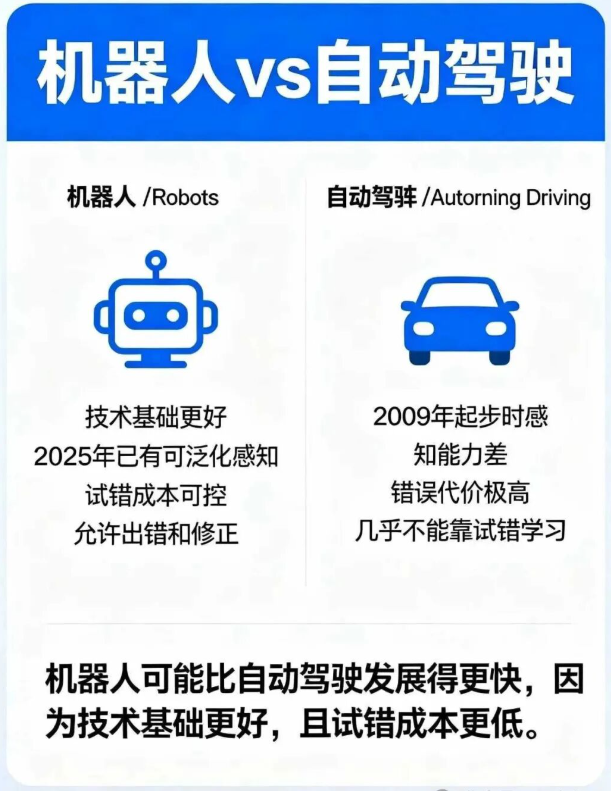
这不是说机器人比自动驾驶容易,而是说 2025 年比 2009 年更有利。机器人和驾驶还有一个差别。某些方面,机器人操作比驾驶难得多。但在另一些方面,它更容易启动飞轮,哪怕范围更小。举例来说,学开车时,你绝不会让孩子一个人练习。就算是 16 岁的青少年,已经了解了很多世界知识,你也不会放心让他独自摸索。但洗碗不一样。虽然碗也会打碎,但你大概率会放心让小孩自己试着洗碗,而不需要你一直在旁边踩刹车。
很多机器人操作任务就是这样。它们允许犯错并修正。犯错、修正,首先完成了任务,其次学会了避免下次再错。而开车不同,错误本身的代价太大,几乎没法靠试错学习。
当然,并不是所有操作任务都安全。有些非常关键的任务必须避免错误。这时候就需要常识(common sense)。常识的意思是:能够做出合理推测,而不必真的犯错才能学会。这极其重要。五年前我们还完全不会做。但现在我们能用 LLM、VLM 来提问,它们能做出合理推断。它们不会给你专家级别的表现,但你问它:“地上有块‘小心地滑’的牌子,我走过去会怎样?”答案显而易见。2009 年的自动驾驶系统完全答不出。
所以,常识 + 犯错并修正的能力,这和人类学习的方式非常相似。这并不意味着机器人操作就容易了,但它确实让我们能从小范围开始,然后逐步扩展。
Dwarkesh Patel:这些年来——我不是说从 2009 年开始,而是说过去这些年——我们已经有了大量的视频数据、语言数据,也有了 5 到 8 年的 Transformer 技术。很多公司尝试用大量训练数据去做基于 Transformer 的机器人,包括谷歌、Meta 等。但他们为什么会遇到瓶颈?现在又有什么不同?
Sergey Levine:这是个非常好的问题。我先稍微修正一下你的说法。他们其实已经取得了很多进展。在某种意义上,我们现在在 Physical Intelligence 所做的工作,就是建立在过去很多优秀成果的基础之上,比如谷歌的工作。我们中的很多人以前也在谷歌,参与过那些研究。现在我们也在借鉴别人做过的成果。所以毫无疑问,这个领域已经有了不少进展。但如果要让机器人基础模型真正发挥作用,这不仅仅是一个实验室里的科学实验,它还需要工业规模的建设投入。它更像是阿波罗登月计划,而不是一个科研实验。过去在工业研究实验室里做的那些优秀研究(我自己也参与了很多),很大程度上是以基础研究为目标。这当然很好,基础研究非常重要,但仅靠它是不够的。你需要基础研究,同时也需要推动力,把它变成现实。让它变成现实意味着真正把机器人投放到外部世界,获取有代表性的数据——那些机器人在现实世界里需要完成的任务数据——并且要在规模上收集这些数据,构建系统,把所有环节都做好。这需要极高的专注度,一种完全聚焦于把机器人基础模型做好本身的专注,而不仅仅是为了做更多科学研究、发论文或者维持一个研究实验室。
具身智能需要的数据量
Dwarkesh Patel:那是什么阻止你们现在立即把数据规模扩大 100 倍?如果数据是瓶颈,为什么不把办公室扩大一百倍,雇 100 倍的操作员来操作机器人,收集更多数据?为什么不立刻把规模拉大一百倍?
Sergey Levine:这也是个很好的问题。挑战在于,要理解在哪些扩展维度(axes of scale)会提升哪些能力维度(axes of capability)。如果我们想横向扩展能力——也就是说,机器人现在会 10 件事,我希望未来它能会 100 件事——那可以通过直接横向扩展已有的东西来实现。但如果我们希望机器人达到真正实用的水平,那就需要在其他维度上扩展。例如,要实现非常高的鲁棒性,要能高效、快速完成任务,要能识别边界情况并智能应对。这些也可以通过扩展解决。但我们必须先找准正确的扩展方向。这意味着要搞清楚收集什么样的数据、在什么场景下收集、用什么方法处理这些数据、这些方法具体是怎么运作的。只有更深入地回答这些问题,我们才能更清楚地知道哪些变量、哪些维度是需要扩展的。现在我们还不完全清楚未来的样子。但我认为我们很快就能弄明白。这正是我们正在积极研究的方向。我们希望在真正扩大规模之前,把这些搞对,这样扩展出来的能力才会真正对现实应用有意义。
Dwarkesh Patel:给我一个数量级的感觉吧。你们收集的数据量和互联网规模的预训练数据相比如何?我知道很难逐 token 去比,因为视频信息和互联网文本信息很难直接对比。但用你的合理估计,大概是一个什么比例?
Sergey Levine:这确实很难比较,因为机器人经验是由时间步组成的,而这些时间步之间高度相关。原始字节表示的规模是巨大的,但信息密度相对较低。也许更好的比较方式是和多模态训练用的数据集比。上次我们统计时,差距大概在 一到两个数量级之间。
Dwarkesh Patel:你设想的机器人愿景,是否要等到你们再收集 100 倍、1000 倍的数据之后才有可能实现?
Sergey Levine:关键在于——我们其实不知道。这么推理是合理的:机器人是个难题,可能确实需要和语言模型一样多的经验。但因为我们不知道答案,所以我觉得更有用的思考方式是,不是“要多少数据才能彻底完成”,而是“要多少数据才能真正开始”。也就是说,什么时候能形成一个数据飞轮(data flywheel),让数据收集过程自我维持、不断增长。
Dwarkesh Patel:你说的“自我维持”,是指在工作中学习吗?还是还有别的方式?
Sergey Levine:是的,包括在工作中学习,或者以一种方式采集数据,让数据采集过程本身就有价值、有意义。
Dwarkesh Patel:我懂了,有点像强化学习(RL)。
Sergey Levine:对,就是要做一些真正的实际事情。理想情况下我当然希望是 RL,因为 RL 能让机器人自主行动,这样更容易。但也不排除是混合自主的方式。正如我之前提到的,机器人可以从各种信号中学习。我举过例子,机器人可以通过人类的语言指令学习。这就在“完全远程操控”和“完全自主”之间提供了大量中间地带。
具身智能发展与AI基础模型的关系
Dwarkesh Patel:那 π0 模型具体是怎么工作的?
Sergey Levine:我们现在的模型,本质上是一个视觉-语言模型(VLM),但被改造过,可以用于运动控制。打个比方,如果类比大脑,一个 VLM 就像是一个 LLM 外加一个“类视觉皮层”的视觉编码器。而我们的模型除了有视觉编码器,还加了一个动作专家(action expert),也就是动作解码器。可以理解为,它有一个“小视觉皮层”,再加一个“小运动皮层”。模型的决策过程是这样的:它先读取来自机器人的感知信息,然后做一些内部处理,这可能会生成一些中间步骤。比如你告诉它“打扫厨房”,它可能会在内部思考:“好,要打扫厨房,我需要捡起盘子,需要拿起海绵,需要把这些东西放好……”最后,这些推理会传递到动作专家,由动作专家生成连续的动作输出。因为动作是连续的、高频的,数据格式和文本 token 完全不同,所以必须是一个独立模块。但总体结构上,它仍然是一个端到端的 Transformer。严格来说,技术上它对应的是一种混合专家架构(mixture-of-experts)。
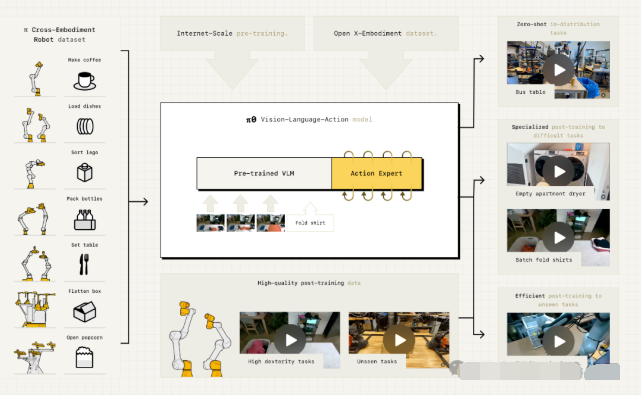
图注:π0 模型架构
Dwarkesh Patel:所以实际运行时,它的过程就是:“我应该做 X 动作”,然后有一个图像 token,再接着一些动作 token——这就是它实际做的动作——然后再有更多图像、更多文字描述、更多动作 token。基本上我看到的就是一个数据流。
Sergey Levine:对,差不多就是这样。唯一的例外是:动作不是离散 token。它们是连续的,所以我们用了流匹配(flow matching)和扩散模型(diffusion),因为要实现灵巧控制,就必须让动作足够精确。
Dwarkesh Patel:我觉得很有意思,你们是基于开源的 Gemma 模型(谷歌开源的 LLM),然后在上面加了动作专家。我觉得 AI 不同领域的进展不仅仅是用相似的技术,甚至是用完全相同的模型。你可以直接拿一个开源 LLM,加一个动作专家在上面。直觉上你可能会以为机器人是一个完全独立的研究领域,而 LLM 和 NLP 又是另外的领域。但实际上不是,它们就是一回事。考量点一样,架构一样,甚至权重都一样。我知道你们在这些开源模型基础上会做更多训练,但这点真的很有意思。
Sergey Levine:这里有一个主题很重要:这些基础构件之所以宝贵,是因为 AI 社区已经变得更擅长利用先验知识(prior knowledge)。我们从预训练好的 LLM 和 VLM 中获得了关于世界的先验知识。它有点抽象,但它能识别物体,能大概知道物体在图像里的位置,类似的东西。如果让我用一句话总结,最近 AI 创新给机器人最大的好处,就是能够利用先验知识。至于模型是否相同,这在深度学习里一直都是如此。但真正强大的是,它能把来自各种来源的抽象知识纳入进来。
 Dwarkesh Patel:我和 GDM 的研究员 Sander 聊过,他做视频和音频模型。他认为不同模态之间的迁移学习并不显著。比如训练语言模型时加了视频和图像,不一定会让它在文本任务上更强。他的理由是:文本在模型内部是高语义层次的表示,而图像和视频只是压缩后的像素。它们被嵌入之后,并没有变成高层语义信息,而只是压缩像素。因此,在模型内部没有发生真正的迁移。这显然和你们的研究很相关。你们希望通过把机器人看到的视觉数据(甚至以后可能来自 YouTube 的视频)、语言信息,以及机器人自身的动作数据一起训练,让模型更鲁棒。你还写过一篇博文,讨论为什么视频模型不像语言模型那么鲁棒。抱歉,我的问题没完全成型,我只是想听听你的反应。
Dwarkesh Patel:我和 GDM 的研究员 Sander 聊过,他做视频和音频模型。他认为不同模态之间的迁移学习并不显著。比如训练语言模型时加了视频和图像,不一定会让它在文本任务上更强。他的理由是:文本在模型内部是高语义层次的表示,而图像和视频只是压缩后的像素。它们被嵌入之后,并没有变成高层语义信息,而只是压缩像素。因此,在模型内部没有发生真正的迁移。这显然和你们的研究很相关。你们希望通过把机器人看到的视觉数据(甚至以后可能来自 YouTube 的视频)、语言信息,以及机器人自身的动作数据一起训练,让模型更鲁棒。你还写过一篇博文,讨论为什么视频模型不像语言模型那么鲁棒。抱歉,我的问题没完全成型,我只是想听听你的反应。
Sergey Levine:是啊,这确实是个关键点。我可以说两点,有坏消息也有好消息。坏消息是,你说的确实触及了视频和图像生成模型长期以来的核心挑战。从某种意义上说,用视频预测来获取智能系统的想法,比用文本预测更早。但文本方向更早变成了实用的东西。视频方向当然也很酷,现在能生成很棒的视频,最近的成果也非常惊艳。但光是生成视频和图像,还没能产生真正“理解世界”的系统,它们无法像语言模型那样完成更复杂的任务。而语言模型显然已经做到了。这点归根到底还是表示问题。
你可以这样想:假设你拿个摄像机对着大楼外面,天空、云、河水、汽车、人群都在动。如果你想预测未来会发生什么,可以有无数角度。你可以说:“好,有人在走路,那我就研究人群心理,预测行人。”也可以说:“好,天上有云,我就研究水分子和冰晶。”你甚至可以钻研到亚原子层面。但就算你把某个方向研究到 100% 准确,等你研究到别的东西时,世界早就变了。视频场景里太多东西需要预测。而文本就不一样,它已经是抽象的表示,聚焦在我们人类真正关心的部分。表示已经被提炼过了。这就是坏消息。
但好消息是:我们不需要只靠“把摄像机对准大楼外面”来获取信息。当机器人有具体任务时,它的感知就是为完成任务服务的。这是一个非常强大的聚焦机制。人类也是这样。心理学实验表明,人类有惊人的“隧道视野”——如果某个东西和你的目标无关,你可能完全没注意到它。这种机制必然有巨大的价值,否则自然选择不会保留它。机器人也会有这种聚焦机制,因为它们要完成任务。
Dwarkesh Patel:既然视频模型没那么鲁棒,这对机器人是不是不利?你们未来会用大量视频数据。理想状态是能把 YouTube 上所有视频丢进去,让模型学会物理世界的运行规律、学会如何移动。它看到人类做任务就能学。但你刚才的意思是:光靠这些不够,它还得亲自去练习。
Sergey Levine:我换个角度说吧。如果我给你大量录像,比如各种体育比赛,让你看一年。看完一年后,我说:“好,现在你的工作是去打网球。”显然这很蠢,对吧?但如果我先告诉你:“你的目标是学会打网球”,然后再让你去看比赛,你就会知道要关注什么。这就是关键。挑战是真实存在的,我不想低估它。但与此同时,具身的基础模型,通过与环境互动、控制机器人学习,会更擅长利用这些额外数据,因为它知道自己要做什么。我不认为这是灵丹妙药,但确实有帮助。我们已经看到一些苗头,比如把网页数据引入机器人训练,确实提高了泛化能力。我怀疑长期来看,这会让我们更容易利用那些过去很难用好的数据源。
具身智能的涌现
Dwarkesh Patel:众所周知,LLM 会出现各种“涌现能力”,很多都不是工程化设计进去的,而是因为互联网文本里确实有相关数据,模型学会了。机器人这边看起来数据都是你们手动收集的。那就不会出现这种神秘的新能力了吧?这似乎让鲁棒的分布外能力更难获得。我在想,未来 5-10 年,会不会是这样的:每一个子任务都要给它成千上万次训练样例。那样很难通过这种方式自动化很多工作。想想咖啡师、服务员、厨师,他们的工作不是在一个工位上重复动作,而是需要走动、补货、修机器、在柜台和收银台之间来回。那是不是会有一个很长的技能尾巴,需要不断手动加样例、加标注?还是说会有更通用的进展?
Sergey Levine:这里有个细微之处。涌现能力并不是单纯因为互联网数据量大,而是因为当泛化达到一定程度时,它就会表现出组合性(compositionality)。我学生举过一个有趣的例子:你知道什么是国际音标(IPA)吗?
Dwarkesh Patel:不知道。
Sergey Levine:查词典时,单词的发音通常用一些奇怪的符号写出来,那就是 IPA。它几乎只用于记录单词的发音。你可以让 LLM 用 IPA 写一份菜谱,它也能做到。很显然,它没见过这种用法,因为 IPA 平常只用来写发音。但它能把它组合起来。这就是组合性泛化。
所以,涌现能力来自于:当模型拥有足够多样的行为样本时,它能把这些行为在新场景下组合起来。我们已经在自己的模型里看到一些小小的涌现。比如我们在做叠衣服实验时,机器人有一次从箱子里抓出两件 T 恤而不是一件。它开始折第一件,另一件挡住了,它就顺手把第二件扔回箱子里。我们当时完全没想到。后来发现,它每次都会这样做。再比如,桌上掉了东西,它会顺手捡起来放回去。袋子倒了,它会扶起来。我们没有专门采集过这些数据,但模型学会了。这就是规模化学习下的组合性。再加上语言、链式思维推理,模型就有很大潜力能以新的方式组合已有技能。
Dwarkesh Patel:对,我在你们办公室参观时也见过类似例子。机器人在叠一条短裤。我为了好玩,把短裤翻到里面朝外,它居然理解到先要把短裤翻回来,再折叠好。更让我吃惊的是,它的夹爪只是“拇指+手指”式的,但能完成很多事。而且它的上下文似乎只有一秒。语言模型可以看上万 token,机器人模型只看上一秒的画面,就能执行一分钟的计划。这很疯狂。 对,我想问的是:你们为什么会选择只给它一秒的上下文?为什么它能在这种情况下完成任务?如果一个人类只有一秒记忆,是不可能做体力工作的。
Sergey Levine:首先说明,不是说记忆少有什么好处。加长记忆、提升分辨率都会让模型更强。但为什么它在你看到的那些任务上没那么关键呢?这就回到 Moravec 悖论。Moravec 悖论说:在 AI 里,容易的事反而难,难的事反而容易。我们习以为常的事情,比如拿东西、感知世界,恰恰是 AI 里的难题;而下棋、做微积分,这些我们觉得费劲的事,反而相对容易。记忆问题其实是这个悖论的另一种表现。我们以为需要很多记忆的任务才是难的,但实际上熟练的体力任务,比如奥运游泳运动员的动作,其实是“当下”的,不需要复杂的上下文,只要神经网络里烙印好的技能。
这不意味着记忆不重要。只是如果我们要先达到人类那种灵巧和身体熟练度,还有更重要的基础要搞定。等这些做好了,再逐步提升到推理、长上下文、规划等认知层次。
具身智能的算力问题
Dwarkesh Patel:你们面临一个三难困境:推理速度、上下文长度、模型规模,这三者都想提升,但都需要更多算力。人类每秒能处理 24 帧甚至更快,同时还能记忆数小时乃至几十年,参数量是数十万亿。但你们的模型只有几十亿参数,推理速度 100 毫秒,上下文一秒。这三者提升一个,推理时就要牺牲另一个。怎么解决?
Sergey Levine:这是个大问题。我们先拆开看。关键在于表示方式。人类有时会用符号方式记忆(比如购物清单),有时会用空间-视觉方式记忆(比如街景)。选择正确的表示形式——能捕捉到完成任务所需的信息,同时丢掉无关信息——是非常关键的。我们看到多模态模型在探索这一点。但我认为多模态远不止“图像+文本”,未来这里还有巨大创新空间。
Dwarkesh Patel:你是指在表示上下文和推理时?
Sergey Levine:对,包括过去发生的事、未来的计划、中间步骤,都要用合适的模态来表示。这可能包括学习到的新模态,只要它适合任务。这就是潜力所在。
Dwarkesh Patel:再对比人脑。人脑能在几十毫秒内反应,记忆几十年,还能处理数十万亿参数。是不是因为人脑硬件远超 GPU?还是说算法更高效?
Sergey Levine:我不确定,但如果让我猜,我会说:人脑极度并行化,比 GPU 还并行。Transformer 本身也能并行,但在实现上我们通常让它顺序执行。而大脑更可能是并行的:同时处理长期记忆、短期空间感知、语义信息、即时感知和规划。它们以不同速度并行运行。这个机制其实和注意力机制有点像。
Dwarkesh Patel:那如果 5 年后系统能像人一样鲁棒地与世界交互,是什么让它在算力上可行?是英伟达出了更强 GPU,还是算法更高效?
Sergey Levine:可能两方面都有。比如,未来机器人可能部分思考在本地,部分思考在云端。如果网络好,它更聪明;网络差,它更依赖本地反应。另一方面,算法也会进步,比如更高效地压缩感知流,抓住关键信息而不是全存。
Dwarkesh Patel:那是不是要请 YouTube 数据中心的人来帮你们优化视频编码?另外,和 LLM 一样,大模型推理通常是在云端批量运行,而不是本地。机器人是不是也会这样?否则你得在每个机器人里塞进 $50,000 的 GPU,不现实。
Sergey Levine:我猜会两者都有。低成本机器人可能依赖云端,高可靠性机器人则会有本地推理。其实很多动作可以提前规划好,实时部分只需少量计算。关键在于找到哪些表示能提前规划,哪些需要实时反馈。
对模仿学习、强化学习和仿真的观点
Dwarkesh Patel:几年前你说过,机器人用 RL 往往比模仿学习更好。但现在大家还是主要在做模仿学习。为什么还没做 RL?
Sergey Levine:关键是先验知识。要想有效地从自身经验学习,必须先知道一点东西,否则学习速度太慢。就像小孩需要很久才能学会基本动作。但如果有了先验,学习速度会快很多。所以我们现在先用监督学习建立基础模型,给它先验,再过渡到 RL。这和 LLM 的发展完全一样:先用大规模文本预测训练,打好基础,再做合成数据和 RL 微调。
Dwarkesh Patel:10 年后,最强的知识工作模型,会不会其实也是个机器人模型,或者至少带有动作专家?
Sergey Levine:我当然希望是。我很偏心机器人,但我真心觉得它很基础。而且我乐观地认为,机器人部分会让其他部分更强。原因有两个:第一,任务导向会让模型在世界表示上更聚焦;第二,对物理世界的深刻理解,会帮助解决抽象问题。比如我们会说“这家公司有很大动能”,这是物理隐喻。我们的主观经验会塑造我们对抽象概念的理解。
Dwarkesh Patel:我有点不理解为什么仿真对机器人没用。人类飞行员、F1 车手都能通过模拟学习。机器人更聪明后,难道不能像人类一样学会从仿真中提炼出有用部分?还是说永远需要真实世界数据?
Sergey Levine:这是个微妙问题。飞行员用模拟器时,目标很明确:学会开飞机,不是学会玩模拟器。但模型在训练时并不知道它的最终目标。它只会认为“这是一个任务,那是另一个任务”。所以模拟对它来说可能更像“电子游戏”。不是没用,但不同。
Dwarkesh Patel:能不能用元强化学习(meta-RL)?比如 2017 年你写过一篇论文,讨论训练在不同游戏上如何提升下游任务表现。
Sergey Levine:你是说:让模型在模拟里训练,不是为了模拟本身,而是为了提升真实任务的表现,并把这个作为损失函数,对吧?
Dwarkesh Patel:对。
Sergey Levine:这里关键还是:要能在真实任务上训练它。其实 meta-learning 本身可能会涌现。LLM 就通过“上下文学习”表现出类似的 meta-learning。大模型只要有合适的目标和真实数据,就会更好地利用其他数据源。所以,要想用好仿真,前提是先在真实世界上打好基础。就像 LLM 先在真实文本上训练,然后才能有效利用合成数据。
Dwarkesh Patel:那等到 2030 或 2035 年,真正的 AGI 出现,它是不是就能自己构建模拟来练习人类和 AI 都没机会练过的技能?比如要造戴森球,它就先在模拟里练。还是说仿真问题依然存在?
Sergey Levine:模拟本身不能带来新世界知识,它只能让你排练、推演反事实。但世界知识必须来自真实经验。所以归根结底,强大的 AI 会用模拟,但它的知识还是来自世界。
Dwarkesh Patel:人类有没有对应机制?比如做梦、白日梦,是不是类似?
Sergey Levine:很可能是。大脑在睡眠时会重放经验,或生成相似的经验。这其实就是在考虑反事实。最根本的是,最优决策本质上需要考虑反事实:“如果我做另一件事,会不会更好?”不论你用模拟还是价值函数,关键就是要能比较反事实。
具身行业未来的竞争格局
Dwarkesh Patel:有没有“机器人界的英伟达”?
Sergey Levine:现在没有。也许未来会有。也许我是理想主义者,但我希望看到一个多样化的机器人世界。
Dwarkesh Patel:作为算法研究者,你觉得硬件现在的最大瓶颈是什么?
Sergey Levine:很难说,因为变化太快。对我来说,最关注的还是可靠性和成本。成本决定能造多少机器人,进而决定数据量。作为机器学习研究者,我当然希望数据越多越好。可靠性也同样重要。随着 AI 系统越来越强,硬件才会被真正推到极限,到时我们会有更明确的答案。但至少到现在,AI 还没把硬件逼到极限。
Dwarkesh Patel:我问过很多嘉宾一个问题:AI 爆炸涉及的产业链,很多基础环节都在中国生产,除了芯片。比如太阳能组件、机器人机械臂。为什么不会是中国自动获胜?
Sergey Levine:这是个复杂问题。宏观上看,自动化能显著提高劳动力生产率,放大每个人的产出。这和 LLM 增强程序员一样。机器人会增强所有人的生产力。终点是美好的,但过程复杂,需要社会、产业、政治层面做很多决策。关键在于:要建立一个平衡的机器人生态,同时重视软件和硬件创新。我对此很乐观,因为终点和我们的社会愿景一致。
Dwarkesh Patel:但如果价值瓶颈在硬件,数亿机器人要如何在美国或盟友体系内制造?
Sergey Levine:具体怎么实现,这需要更长的讨论,我也不是最合适的人。但一个关键点是:机器人能帮做体力劳动,而制造机器人本身就是体力劳动。只要机器人足够强大,它们也能参与制造机器人。虽然有点循环,但比制造电脑、手机要容易。
Dwarkesh Patel:我注意到,不论讨论哪个环节,大家最后都会说:“这个环节中国占 80%。”
Sergey Levine:所以我说要有平衡的生态。AI 很令人兴奋,但它不是唯一需要关注的。我们需要整体思考,包括硬件、基础设施。比如在 Physical Intelligence,我们同时规划 AI 路线和硬件路线。作为社会,我们需要更整体的对话。
Dwarkesh Patel:从社会角度看,大家该如何思考机器人和知识工作的进步?是不是该为全面自动化做准备?
Sergey Levine:方向上你说得对。但科技的发展路径往往出乎意料。旅程和终点一样重要。我们要同时关注过程。真正重要的一点是:教育。教育是缓冲技术变革冲击的最好方式。如果社会要抓一个杠杆,那就是更多教育。
Dwarkesh Patel:可 Moravec 悖论也说,教育对人类最有价值的部分,可能正是最容易被自动化的。因为 AI 学知识很快。
Sergey Levine:教育的价值不在于具体事实,而在于灵活性,在于获取新技能的能力。当然,前提是教育质量要好。
Dwarkesh Patel:好,Sergey,非常感谢你来上播客,内容太精彩了。
Sergey Levine:谢谢,这真是一场高强度的对话,好多尖锐的问题。
原文链接:https://mp.weixin.qq.com/s/MCOV8DvW3fUCcCafJD4nNg
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/2501_91883294/article/details/152077929

