

一、常用数据结构
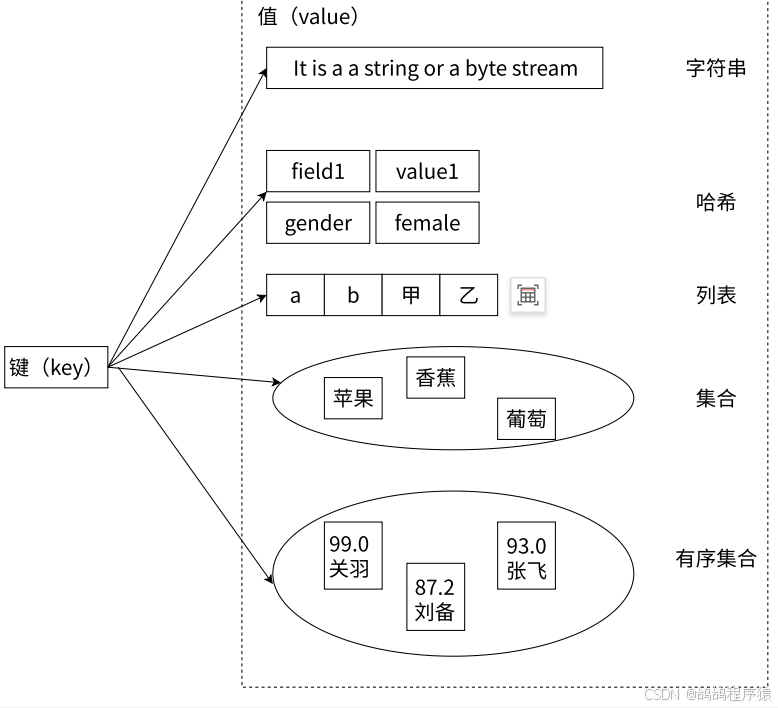
Redis 对外说values 常用的数据结构是:string(字符串)、list(列表)、hash(哈希)、set(集合)、zset(有序集合)等等,但是其实内部实现在不同情况下也与常见的数据结构有一定的不同。
二、 内部编码
- String类型,有 raw ,int,embstr 三种实现。
-
- raw : 最基本的字符串,底层就是字符数组
-
- int :当value就是一个整数的时候,Redis直接使用int来保存
-
- embstr:针对短字符串进行的特殊优化
- hash类型,有hashtable,ziplist两种实现。
-
- hashtable:最基本的hash表
-
- ziplist:在hash表元素比较少的时候,使用压缩列表,节省空间
- list类型,有linkedList 和 ziplist两种实现。
-
- linkedlist:正常普通的链表
-
- ziplist:list元素较少的时候,使用压缩列表。
-
- 在Redis3.2之后,使用quicklist代替上面两种。quicklist就是一个元素是ziplist的链表。
- set类型,有hashtable,intset两种实现。
-
- hashtable:hash表
-
- intset:集合中存的都是整数时使用
- zset类型,有skiplist和ziplist两种实现。
-
- skiplist:跳表,每个节点有多个指针域,巧妙使用可以做到查询元素时间复杂度为O(logN)
-
- ziplist:元素较少的时候使用
可以使用 object encoding key查看key对应的value的内部编码。
三、单线程架构
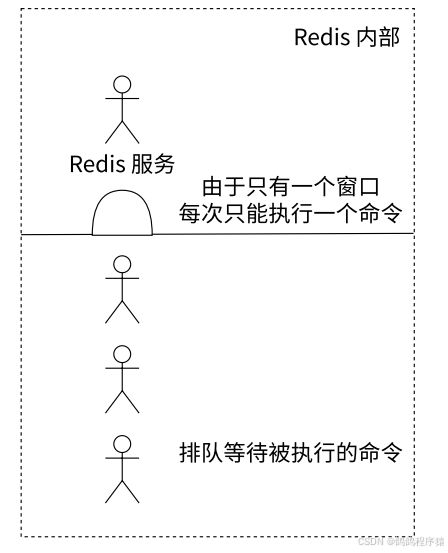
Redis 使⽤了单线程架构来实现⾼性能的内存数据库服务。
宏观上我们多个客户端可能会同时请求Redis服务器,但是实际上由于Redis服务器处理请求的是单线程,就算真的命令同时到达,也得排队串行执行。
- 单线程还能这么快(与关系型数据库相比)的原因:因为Redis核心业务逻辑都是短平快的,不太吃CPU资源。
- 纯内存访问。Redis 将所有数据放在内存中,内存的响应时⻓⼤约为 100 纳秒,这是 Redis 达到每秒万级别访问的重要基础。
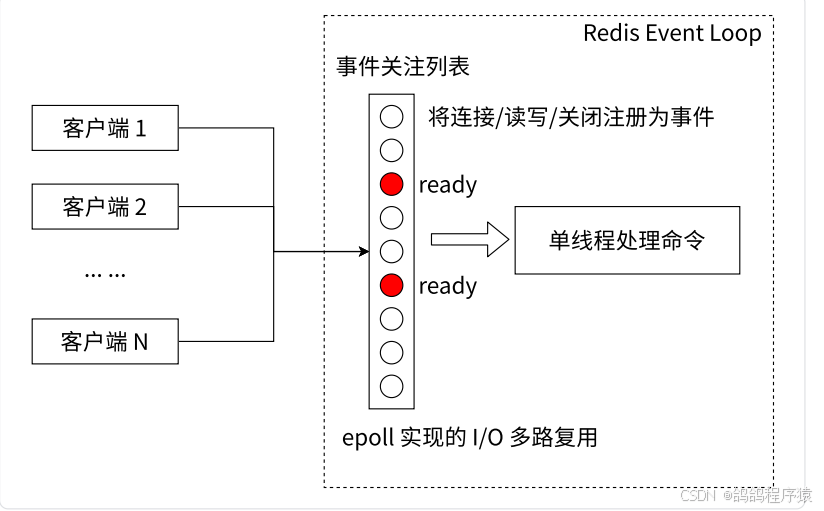
- ⾮阻塞 IO。Redis 使⽤ epoll 作为 I/O 多路复⽤技术的实现,再加上 Redis ⾃⾝的事件处理模型将 epoll 中的连接、读写、关闭都转换为事件,不在⽹络 I/O 上浪费过多的时间.
- 单线程避免了线程切换和竞态产⽣的消耗。单线程可以简化数据结构和算法的实现,让程序模型更简单;其次多线程避免了在线程竞争同⼀份共享数据时带来的切换和等待消耗。
Redis 使⽤ I/O 多路复⽤模型:
- Redis单线程的缺点:如果某个命令执⾏过⻓,会导致其他命令全部处于等待队列中,迟迟等不到响应,造成客⼾
端的阻塞,对于 Redis 这种⾼性能的服务来说是⾮常严重的。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/yj20040627/article/details/153403560

