
一、什么是 Z-score 归一化?
Z-score 归一化是一种常见的数据预处理方法,目的是将不同量纲、不同取值范围的数据变换为均值为 0、标准差为 1 的分布。
公式:
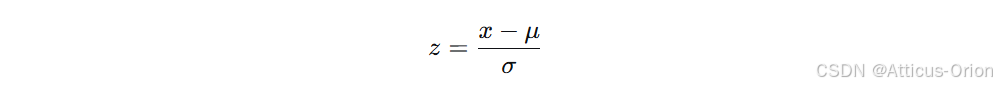
-
x:原始数据
-
μ:数据的均值
-
σ:数据的标准差
转换后的数据称为 Z 分数,表示原始数据距离均值有多少个标准差。
二、Z-score 归一化的特点
1. 不改变数据分布形态
-
只改变数据的位置(均值)和尺度(标准差),不改变原始分布的相对形状(如偏度、峰度等不变)。
2. 对异常值敏感
-
均值和标准差受极端值影响较大,若数据中存在离群点,Z-score 归一化效果可能变差。
3. 输出范围无固定区间
-
与 Min-Max 归一化不同,Z-score 归一化后的数据范围不固定在 [0,1] 或 [-1,1],一般约 99.7% 的数据落在 [-3,3] 之间(假设近似正态分布)。
4. 保留相对关系
-
原始数据的大小顺序、距离的相对关系(在欧氏距离意义下按比例缩放)会被保留。
三、应用场景
| 场景 | 说明 | ||
|---|---|---|---|
| 机器学习算法 | 对基于距离的算法(KNN、SVM、K-Means、PCA)非常必要,防止特征量纲影响模型 | ||
| 正则化与梯度下降 | 使损失函数等高线更圆,加快收敛速度 | ||
| 特征可比性 | 消除不同单位、不同尺度的影响,便于综合比较 | ||
| 异常检测 | Z-score 绝对值过大可视为异常(如 | z | > 3) |
四、优缺点总结
✅ 优点
-
不受数据取值范围限制,适用于近似正态分布的数据
-
保留原始数据的分布形态
-
许多统计模型和机器学习模型假设数据服从标准正态分布,Z-score 可满足该要求
❌ 缺点
-
要求知道或能计算均值和标准差(对实时流数据不友好)
-
对异常值敏感
-
输出范围不确定,不适用于必须限定输出区间的场景(如图像像素值 0–255)
五、与 Min-Max 归一化的简单对比
| 特性 | Z-score 归一化 | Min-Max 归一化 |
|---|---|---|
| 输出范围 | 均值 0,标准差 1,无固定上下界 | 固定区间(如 [0,1]) |
| 对异常值敏感性 | 敏感 | 非常敏感(极端值压缩正常值) |
| 适用分布 | 正态或近似正态 | 任意分布,但需注意边界值 |
| 是否保留零值 | 变换后通常不为零 | 可能保留 0(若原数据有 0) |
六、Mermaid 总结框图
以下框图总结了 Z-score 归一化的核心概念、公式、优缺点及应用场景。
 七、其他常见的归一化
七、其他常见的归一化
一、Min-Max 归一化
公式:
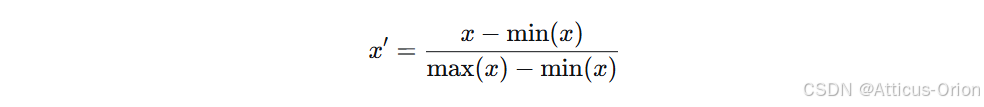
-
输出范围:通常 [0, 1](也可以映射到任意区间 [a, b])
-
特点:
-
将数据线性压缩到固定区间
-
对异常值极其敏感(一个极大值会压缩其余正常数据)
-
保留原始数据的相对大小关系
-
-
适用场景:需要严格限制输出范围的情况(如图片像素处理、神经网络输入层)
二、MaxAbs 归一化
公式:
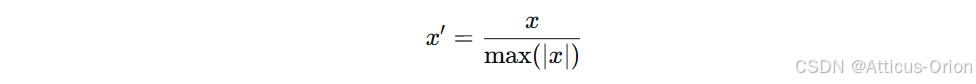
-
输出范围:[-1, 1]
-
特点:
-
不移动/中心化数据,仅缩放
-
保留数据的正负号
-
对异常值敏感(受最大绝对值影响)
-
-
适用场景:稀疏数据(避免破坏零值)、已中心化的数据
三、RobustScaler(鲁棒归一化)
公式:
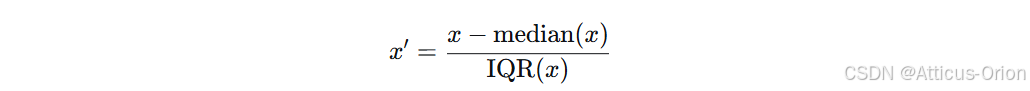
(IQR = 四分位距,即 Q3 - Q1)
-
输出范围:无固定区间
-
特点:
-
对异常值不敏感(使用中位数和分位数)
-
受极端值影响远小于 Z-score 和 Min-Max
-
-
适用场景:数据包含大量离群点
四、单位向量归一化(L2 归一化)
公式:
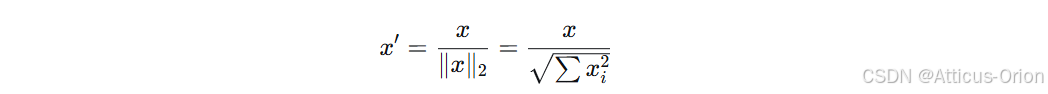
-
输出范围:每个样本的 L2 范数为 1(向量长度为 1)
-
特点:
-
将每个样本(行)缩放为单位向量,而不是逐特征缩放
-
保留方向信息,消除长度影响
-
-
适用场景:文本分类(TF-IDF 后)、聚类(余弦相似度)、需要比较向量方向的场景
五、均值归一化(Mean Normalization)
公式:
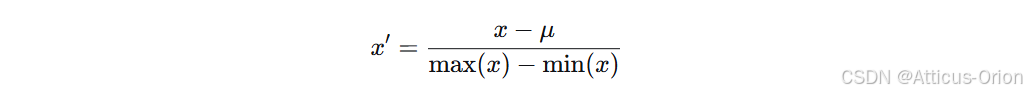
-
输出范围:通常 [-1, 1]
-
特点:
-
结合了中心化(减均值)和缩放(除极差)
-
比 Min-Max 多了中心化,比 Z-score 分母不同
-
-
适用场景:需要数据有正有负且范围可控
六、对数/幂变换(非线性归一化)
-
对数变换:x′=log(1+x)(处理长尾分布)
-
Box-Cox 变换:x′=xλ−1λ1(使数据更接近正态分布)
-
特点:非线性,改变分布形态,压缩大值
-
适用场景:偏态分布、异方差性数据
七、对比总结表
| 方法 | 公式核心 | 输出范围 | 对异常值敏感 | 是否中心化 | 典型应用 |
|---|---|---|---|---|---|
| Z-score | (x - μ)/σ | 无固定(≈99.7%在[-3,3]) | 敏感 | ✅ | 距离类模型、PCA |
| Min-Max | (x - min)/(max - min) | [0,1](或自定义) | 非常敏感 | ❌ | 图像、神经网络 |
| MaxAbs | x / max(|x|) | [-1,1] | 敏感 | ❌ | 稀疏数据 |
| RobustScaler | (x - median)/IQR | 无固定 | 不敏感 | ✅ | 含异常值的数据 |
| L2 归一化 | x / |x|₂ | 单位向量(范数为1) | 视情况 | ❌ | 文本、余弦相似度 |
| 均值归一化 | (x - μ)/(max - min) | [-1,1] 附近 | 非常敏感 | ✅ | 需中心化且范围可控 |
| 对数变换 | log(1 + x) | (0, ∞) → (0, ∞) | 不敏感(压缩大值) | ❌ | 长尾分布 |
八、Mermaid 总结框图
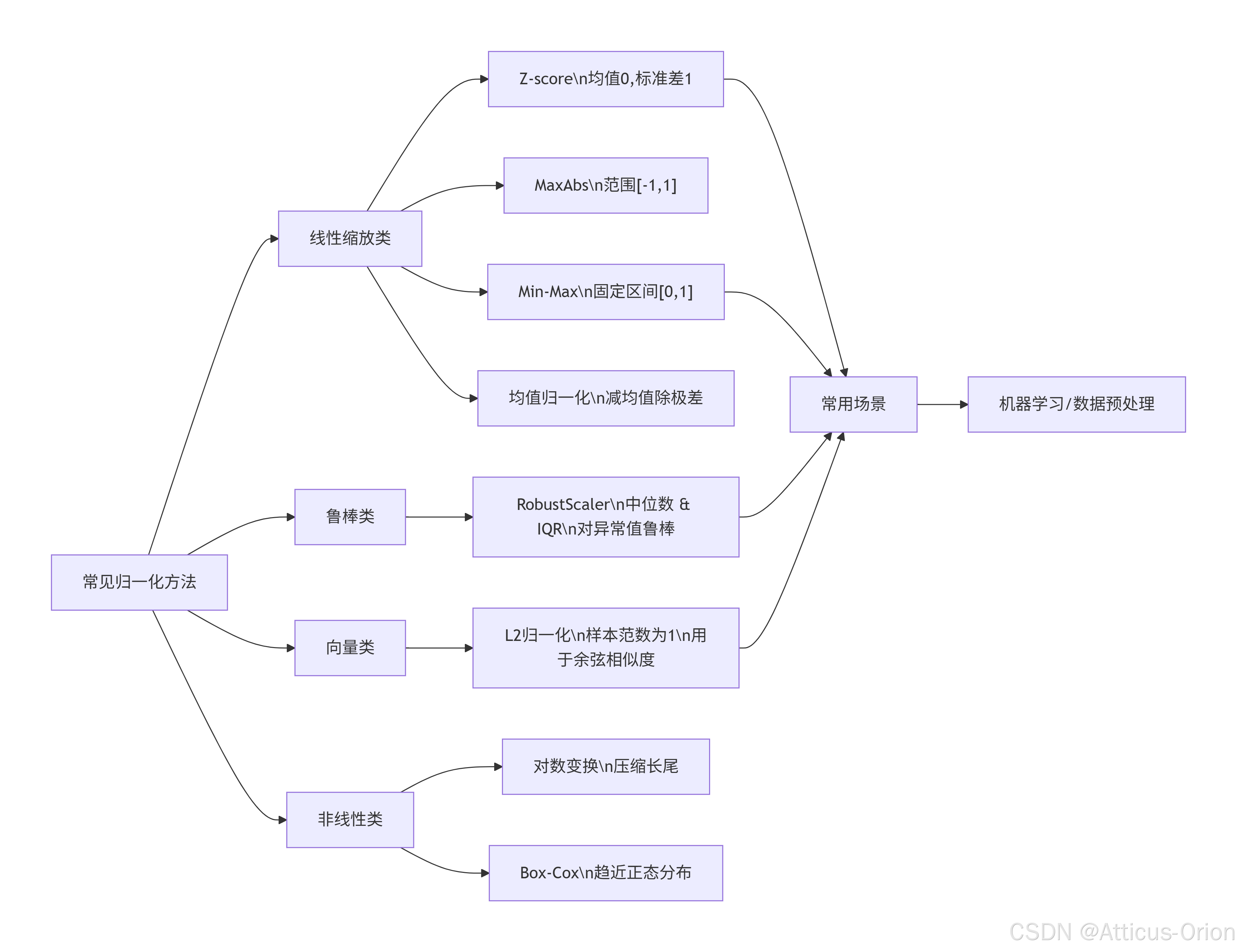
九、选择建议
| 数据情况 | 推荐方法 |
|---|---|
| 近似正态分布,无大异常值 | Z-score |
| 需要严格输出范围(如 [0,1]) | Min-Max |
| 有较多异常值 | RobustScaler |
| 稀疏数据(含很多0) | MaxAbs |
| 需要比较向量方向(文本/推荐) | L2 归一化 |
| 长尾分布 | 对数变换 → 再 Z-score |
| 神经网络输入(无严格要求) | Min-Max 或 Z-score(通常 Z-score 收敛更快) |
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2301_79556402/article/details/159931355

