
python环境准备
1. Python基本介绍
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990 年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
Python解释器易于扩展,可以使用C语言或C++(或者其他可以通过C调用的语言)扩展新的功能和数据类型。 Python 也可用于可定制化软件中的扩展程序语言。Python丰富的标准库,提供了适用于各个主要系统平台的源码或机器码。
2022年01月,语言流行指数的编译器Tiobe将Python加冕为最受欢迎的编程语言,20年来首次将其置于Java、C和JavaScript之上
1.1 Python语言特点
优点:
-
1- 免费、开源、简单、易学、易读,易维护:
Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样。它使你能够专注于解决问题而不是去搞明白语言本身。
Python极其容易上手,因为Python有极其简单的说明文档
风格清晰划一、强制缩进
-
2- 高层语言:
用Python语言编写程序的时候无需考虑诸如如何管理你的程序使用的内存一类的底层细节。 很多功能已经封装好了, 我们只需要关系业务本身即可
-
3- 可移植性:
由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE、PocketPC、Symbian以及Google基于linux开发的android平台。
-
4- 解释性:
在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。这使得使用Python更加简单。也使得Python程序更加易于移植。
-
5- 面向对象
Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。与其他主要的语言如C++和Java相比,Python以一种非常强大又简单的方式实现面向对象编程。
-
6- 可扩展性、可扩充性
如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
-
7- 可嵌入性
可以把Python嵌入C/C++程序,从而向程序用户提供脚本功能。
-
8- 丰富的库
Python标准库很庞大。 它可以帮助处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。这被称作Python的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
-
9- 规范的代码
Python采用强制缩进的方式使得代码具有极佳的可读性。
弊端:
Python语言非常完善,没有明显的短板和缺点,唯一的缺点就是执行效率慢,这个是解释型语言所通有的,同时这个缺点也将被计算机越来越强大的性能所弥补
1.2 Python的应用场景
目前基于Python的应用场景非常的广泛, 包括web开发, 测试, 爬虫, 机器学习, 数据分析等, 由于是在最近几年python在大数据中应用也是非常的广泛, 比如在 spark中, pyspark库的每月下载量超过500w次
2. Python环境的搭建
2.1 python解析器安装
-
1- 下载python解释器
Windows或macOS,选择自己的环境

-
windows为例
-
-
2- 安装解析器:
windows:
-

-

-
安装成功,close即可
-
打开CMD, 进行校验:
-
输入:python -V
-
输出:Python 3.10.9
-
2.2 pycharm 安装操作
-
1- 下载pycharm
下载专业版本:
先next,然后选这些

install
finish
-
2- 安装pycharm:
双击打开即可: 如果弹出一下界面, 选择即可

常见的程序设计语言组成部分:
-
词法元素(Lexical Elements):程序设计语言使用一些基本的词法元素来构建语句和表达式,如标识符、关键字、运算符、常量等。
-
语法(Syntax):语法定义了程序设计语言中的语句和表达式的结构和组织方式。语法规则定义了合法的语法结构和语句的形式。
-
语义(Semantics):语义规定了程序设计语言中的语句和表达式的含义和行为。语义描述了程序执行的结果和效果。
-
数据类型(Data Types):程序设计语言中定义了不同的数据类型,用于存储和操作数据。数据类型可以包括整数、浮点数、布尔值、字符、字符串等。
-
控制结构(Control Structures):控制结构用于控制程序的执行流程,包括条件语句(if-else、switch)、循环语句(for、while)和跳转语句(break、continue、return)等。
-
函数和模块(Functions and Modules):程序设计语言中通常有函数和模块的概念,用于组织和重用代码。函数是一个封装了一系列操作的代码块,而模块是一个包含多个函数和数据的单元。
-
标准库(Standard Library):许多程序设计语言都提供了一个标准库,其中包含了一些常用的函数和类,用于实现常见的操作和算法。
-
输入输出(Input/Output):程序设计语言提供了用于输入和输出数据的机制,如读写文件、控制台输入输出等。
3. 开发第一个Python程序
-
1- 打开pycharm. 选择 new project 创建第一个python项目:点击

-
2- 选择
Location表示该项目保存的路径,Interpreter表示使用的Python解释器版本,最后点击Create创建项目 -

-
new directory
-
3-右击项目 选择new, 在选择python File
-
new Python File
-
4- 在弹出的对话框中输入的文件名hello_world,直接回车,表示创建一个Python程序的文本文件,文本文件后缀名默认.py
-
5- 输入以下代码,并右击空白处,选择
Run运行,表示打印一个字符串"hello world!" -
print("hello world!")
-
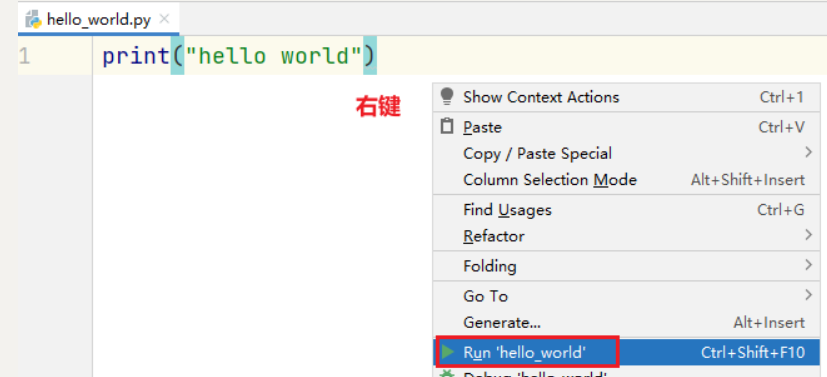 6- 运行成功后,Pycharm Console窗口将显示我们的输出结果
6- 运行成功后,Pycharm Console窗口将显示我们的输出结果
-
就是如此简单!!!
python基础
1.python基础语法
1.1 注释
-
单行注释: 以#开头,#右边的所有文字当作说明,而不是真正要执行的程序,起辅助说明作用
# 我是注释,可以在里写一些功能说明之类的哦
print('hello world')-
2- 多行注释
-
"""内容""", 三个引号引起来的内容作为对代码的解释说明, 这里的解释往往比较详尽,行数较多(三个单引号或者三个双引号都可以)
-
'''
我是多行注释,可以写很多很多行的功能说明
下面的代码完成 ,打印一首诗
名字叫做:春江花月夜
'''1.2 定义变量
如何定义变量呢?
-
格式: 变量名=值
num1 = 100
num2 = 87
result = num1 + num2当我们直接定义值的时候, python会自动推断类型的, 那么如何查看python所推断的类型是什么呢?
# 定义一个数字类型变量num
num = 10
# 这里使用type就可以查看num的具体类型
print(type(num))
1.3 输出操作
-
标准输出操作
# 输出函数print的使用
print('hello world')
print('萨瓦迪卡---泰语,你好的意思')-
格式化输出
age = 10
print("我今年%d岁" % age)
age = 11
print("我今年%d岁" % age)
age = 12
print("我今年%d岁" % age)看上面的代码可以知道, 只需要改标age的大小, 就可以输出不同的结果而不需要每一次都去修改
"我今年10岁"
在程序中,看到了%这样的操作符,就是Python中格式化输出.
格式化输出的作用: 可以在不改变print函数中的数据的情况下就可以输出不同的数据
age = 18
name = "xiaohua"
print("我的姓名是%s, 年龄是%d" % (name, age))常用的格式符号:
| 格式符号 | 转换 |
|---|---|
| %c | 字符 |
| %s | 字符串 |
| %d | 有符号十进制整数 |
| %u | 无符号十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数(小写字母0x) |
| %X | 十六进制整数(大写字母0X) |
| %f | 浮点数 |
| %e | 科学计数法(小写'e') |
| %E | 科学计数法(大写“E”) |
| %g | %f和%e 的简写 |
| %G | %f和%E的简写 |
-
换行输出
print("1234567890-------") # 会在一行显示
print("1234567890\n-------") # 一行显示1234567890,另外一行显示--------
f-strings 输出
-
f-strings 提供一种简洁易读的方式, 可以在字符串中包含 Python 表达式. f-strings 以字母 'f' 为前缀, 格式化字符串使用一对单引号、双引号、三单引号、三双引号. 格式化字符串中
-
name = '老铁'
age = 33
print('--------------------------------------------------')
print(f'名字:{name},年龄{age}')
print('--------------------------------------------------')结果:
-------------------------------------------------- 名字:老铁,年龄33 --------------------------------------------------
1.4 输入操作
-
input() 函数
password = input("请输入密码:")
print('您刚刚输入的密码是:%s' % password)运行结果:
点击运行,输入密码:123456,按enter即可
注意:
input()的小括号中放入的是,提示信息,用来在获取数据之前给用户的一个简单提示
input()在从键盘获取了数据以后,会存放到等号右边的变量中
input()会把用户输入的任何值都作为字符串来对待
1.5 运算符
-
1- 算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 两个对象相加 a + b 输出结果 30 |
| - | 减 | 得到负数或是一个数减去另一个数 a - b 输出结果 -10 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 |
| / | 除 | b / a 输出结果 2 |
| // | 取整除 | 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
| % | 取余 | 返回除法的余数 b % a 输出结果 0 |
| ** | 指数 | a**b 为10的20次方, 输出结果 100000000000000000000 |
注意:混合运算时,优先级顺序为:
**高于*/%//高于+-,为了避免歧义,建议使用()来处理运算符优先级。并且,不同类型的数字在进行混合运算时,整数将会转换成浮点数进行运算。
下面以a=10 ,b=20为例进行计算,只要是">>>"开头的,在cmd输入python运行解释器,就可以直接验证
>>> 10 + 5.5 * 2
21.0
>>> 10 + (5.5 * 2)
21.0-
2- 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 赋值运算符 | 把 = 号右边的结果 赋给 左边的变量,如 num = 1 + 2 * 3,结果num的值为7 |
# 单个变量赋值
>>> num = 10
>>> num
10
# 多个变量赋值
>>> num1, num2, f1, str1 = 100, 200, 3.14, "hello"
>>> num1
100
>>> num2
200
>>> f1
3.14
>>> str1
"hello"-
3- 复合赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c = a 等效于 c = c **a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
1.6 常用数据类型转换
在程序中往往会出现需要数据类型转化的需求
例如:
input()函数默认接受到的是str(字符串)数据类型数据, 而我们需要input()函数给我们一个数字类型的数据. 这时候我们就可以把接受到的数据进行数据类型转化.
| INT(X [,BASE ]) | 将X转换为一个整数 |
|---|---|
| 函数 | 说明 |
| float(x ) | 将x转换为一个浮点数 |
| complex(real [,imag ]) | 创建一个复数,real为实部,imag为虚部 |
| str(x ) | 将对象 x 转换为字符串 |
| repr(x ) | 将对象 x 转换为表达式字符串 |
| eval(str ) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s ) | 将序列 s 转换为一个元组 |
| list(s ) | 将序列 s 转换为一个列表 |
| chr(x ) | 将一个整数转换为一个Unicode字符 |
| ord(x ) | 将一个字符转换为它的ASCII整数值 |
| hex(x ) | 将一个整数转换为一个十六进制字符串 |
| oct(x ) | 将一个整数转换为一个八进制字符串 |
| bin(x ) | 将一个整数转换为一个二进制字符串 |
举例:
>>> # int(): 将数据转换为 int 类型
>>> str1 = "10"
>>> # int() 默认按10进制转换后显示
... num1 = int(str1)
>>> print(num1)
10
>>> # int() 处理浮点数,只留下整数部分,舍弃小数部分(并不是四舍五入操作)
... num2 = int(3.74)
>>> print(num2)
32. 判断语句和循环语句
2.1 if判断语句
-
if语句是用来进行判断的,其使用格式如下:
if 要判断的条件:
条件成立时,要做的事情
-
案例一: 写一个网吧登录的程序, 年满18岁就可以上网,不满18岁就不可以上网, 那么这个程序在编写的时候就需要用到if判断语句
print("------if判断开始------")
if age >= 18:
print("我已经成年了")
print("------if判断结束------")结果:
------if判断开始------
我已经成年了
------if判断结束------
注意:
-
if判断语句的作用:就是当满足一定条件时才会执行代码块语句,否则就不执行代码块语句。
-
注意:代码的缩进为一个tab键,或者4个空格
-
if-else的使用格式
if 条件:
满足条件时要做的事情1
满足条件时要做的事情2
满足条件时要做的事情3
...(省略)...
else:
不满足条件时要做的事情1
不满足条件时要做的事情2
不满足条件时要做的事情3
...(省略)...
示例一:
ticket = 1 # 用1代表有车票,0代表没有车票
if ticket == 1:
print("有车票,可以上火车")
print("终于可以见到Ta了,美滋滋")
else:
print("没有车票,不能上车")
print("亲爱的,那就下次见了")-
if-elif-else语法
if xxx1:
事情1
elif xxx2:
事情2
elif xxx3:
事情3
else:
其他
说明:
当xxx1满足时,执行事情1,然后整个if结束
当xxx1不满足时,那么判断xxx2,如果xxx2满足,则执行事情2,然后整个if结束
当xxx1不满足时,xxx2也不满足,如果xxx3满足,则执行事情3,然后整个if结束
以上都不满足 走 else
案例:
score = 77
if score>=90 and score<=100:
print('本次考试,等级为A')
elif score>=80 and score<90:
print('本次考试,等级为B')
elif score>=70 and score<80:
print('本次考试,等级为C')
elif score>=60 and score<70:
print('本次考试,等级为D')
else:
print('本次考试,等级为E')-
if嵌套使用
if 条件1:
满足条件1 做的事情1
满足条件1 做的事情2
if 条件2:
满足条件2 做的事情1
满足条件2 做的事情2
说明
外层的if判断,也可以是if-else
内层的if判断,也可以是if-else
根据实际开发的情况,进行选择
ticket = 1 # 用1代表有车票,0代表没有车票
knief_length = 9 # 刀子的长度,单位为cm
if ticket == 1:
print("有车票,可以进站")
if knief_length < 10:
print("通过安检")
print("终于可以见到Ta了,美滋滋<font color=Coral size=5>~")
else:
print("没有通过安检")
print("刀子的长度超过规定,等待警察处理...")
else:
print("没有车票,不能进站")
print("亲爱的,那就下次见了")2.2 比较/逻辑运算符
常见的比较运算符:
| 运算符 | 描述 | 示例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果是则条件变为真。 | 如a=3,b=3,则(a == b) 为 True |
| != | 检查两个操作数的值是否相等,如果值不相等,则条件变为真。 | 如a=1,b=3,则(a != b) 为 True |
| > | 检查左操作数的值是否大于右操作数的值,如果是,则条件成立。 | 如a=7,b=3,则(a > b) 为 True |
| < | 检查左操作数的值是否小于右操作数的值,如果是,则条件成立。 | 如a=7,b=3,则(a < b) 为 False |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件成立。 | 如a=3,b=3,则(a >= b) 为 True |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件成立。 | 如a=3,b=3,则(a <= b) 为 True |
# 关系运算符
# 这里的True代表成立 False代表不成立
>>> # == 等于:表示左右两个操作数是否相等,如果相等则整个表达式的值为 True;不相等则为False
>>> num1 = 15
>>> num2 = 20
>>> print(num1 == num2)
False
>>> # != 不等于
>>> print(num1 != num2)
True
>>> # > 大于
>>> print(num1 > num2)
False
>>> # < 小于
>>> print(num1 < num2)
True
>>> # >= 大于等于: num1 大于 或者 等于 num2 ,条件都成立
>>> print(num1 >= num2)
False
>>> # <= 小于等于: num1 小于 或者 等于 num2 ,条件都成立
>>> print(num1 <= num2)
True常见逻辑运算符:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与":如果 x 为 False,x and y 返回 False,否则它返回 y 的值。 | True and False, 返回 False。 |
| or | x or y | 布尔"或":如果 x 是 True,它返回 True,否则它返回 y 的值。 | False or True, 返回 True。 |
| not | not x | 布尔"非":如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not True 返回 False, not False 返回 True |
# 逻辑运算符
>>> # and : 左右表达式都为True,整个表达式结果才为 True
if (1 == 1) and (10 > 3):
print("条件成立!")
条件成立!
>>> # or : 左右表达式有一个为True,整个表达式结果就为 True
if (1 == 2) or (10 > 3):
print("条件成立!")
条件成立!
>>> # not:将右边表达式的逻辑结果取反,Ture变为False,False变为True
if not (1 == 2):
print("条件成立!")
条件成立!2.3 三目计算
python本身并不支持三目(三元)计算, 但是我们可以通过 if else 变形来解决
if 判断条件1:
表达式1
else:
表达式2
判断条件成立,执行表达式 1, 条件不成立,执行表达式 2
变量 = 表达式1 if 判断条件 else 表达式2 # 推荐使用扁平化代码
变量最终存储的结构是:
判断条件成立,表达式1的值,
条件不成立,表达式2的值

2.4 小案例: 猜拳游戏
需求:
-
输⼊要出的拳 —— ⽯头(1)/剪⼑(2)/布(3)
-
电脑 随机 出拳 —— 先假定电脑只会出⽯头,完成整体代码功能
-
⽐较胜负
如何实现随机操作:
-
在 Python 中,要使⽤随机数,⾸先需要导⼊ 随机数 的 模块 —— “⼯具包”
import random-
导⼊模块后,可以直接在 模块名称 后⾯敲⼀个 . 然后按 Tab 键,会提示该模块中包含的所有函数
-
random.randint(a, b) ,返回 [a, b] 之间的整数,包含 a 和 b
-
例如:
>>> import random
>>> random.randint(1,3)
3
>>> random.randint(1,3)
3
>>> random.randint(1,3)
2
>>> random.randint(1,3)
3
>>> random.randint(1,3)
2
>>> random.randint(1,3)
1代码实现:
import random
"""
需求:
1. 输⼊要出的拳 —— ⽯头(1)/剪⼑(2)/布(3)
2. 电脑 随机 出拳 —— 先假定电脑只会出⽯头,完成整体代码功能
3. ⽐较胜负
"""
# 1) 输⼊要出的拳 —— ⽯头(1)/剪⼑(2)/布(3)
player_user = int(input("请输入: ⽯头(1)/剪⼑(2)/布(3):"))
# 2)电脑随机出拳:
# 随机产生 一个 1~3之间的数字: 1 或者 2 或者 3
player_pc = random.randint(1,3)
# 3) 比较操作:
if player_user == player_pc:
print("平局......")
elif ((player_user == 1) and (player_pc == 2)) or ((player_user ==2) and (player_pc == 3)) or ((player_user == 3) and (player_pc == 1)):
print("我赢了")
else:
print("我输了")2.5 循环语句
2.5.1 while循环
格式:
while 条件:
条件满足时,做的事情1
条件满足时,做的事情2
条件满足时,做的事情3
...(省略)...
案例: 循环打印5次
i = 0
while i < 5:
print("当前是第%d次执行循环" % (i + 1))
print("i=%d" % i)
i+=1死循环
while True:
print(1)综合案例:所有代码建议不要直接复制粘贴,学习阶段慢慢敲代码
-
需求一: 计算1~100 的累加和(包含1~100)
i = 1
sum = 0
while i <= 100:
sum = sum + i
i += 1
print("1~100的累加和为:%d" % sum)
-
需求二: 计算1~100之间偶数的累加和(包含1和100)
i = 1
sum = 0
while i <= 100:
if i % 2 == 0:
sum = sum + i
i+=1
print("1~100的累加和为:%d" % sum)
-
while嵌套
格式:
while 条件1:
条件1满足时,做的事情1
条件1满足时,做的事情2
条件1满足时,做的事情3
...(省略)...
while 条件2:
条件2满足时,做的事情1
条件2满足时,做的事情2
条件2满足时,做的事情3
...(省略)...
案例1:
要求:打印如下图形:
* * * * *
* * * * *
* * * * *
* * * * *
* * * * *
代码实现:
i = 1
while i <= 5:
j = 1
while j <= 5:
print("*", end=" ")
j += 1
print()
i += 1
案例2:
要求:打印如下图形:
*
* *
* * *
* * * *
* * * * *
参考代码:
i = 1
while i <= 5:
j = 1
while j <= i:
# end 设置 print的结尾内容, 默认是 \n 回车 更改为 空格, 表示不换行
print("*", end=" ")
j += 1
print()
i += 1
2.5.2 for 循环
格式:
for 临时变量 in 列表或者字符串等可迭代对象:
循环满足条件时执行的代码
示例1:
name = 'dashuju'
for x in name:
print(x)示例2:
# 作为刚开始学习python的我们,此阶段仅仅知道range(5)表示可以循环5次即可
for i in range(5):
print(i)
'''
效果等同于 while 循环的:
i = 0
while i < 5:
print(i)
i += 1
'''2.5.3 break 和 continue
break作用: 立刻结束break所在的循环
-
break 在for循环中使用
name = 'itzyjdashuju'
for x in name:
print('----')
if x == 'e':
break
print(x)
else:
print("==for循环过程中,如果没有执行break退出,则执行本语句==")-
break 在while循环中使用
i = 0
while i<5:
i = i+1
print('----')
if i==3:
break
print(i)
else:
print("==while循环过程中,如果没有执行break退出,则执行本语句==")continue作用: 用来结束本次循环,紧接着执行下一次的循环
案例:
i = 0
while i<5:
i = i+1
print('----')
if i==3:
continue
print(i)3. python的容器
容器:容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用各种内置方法对容器中的数据进行增删改查等操作
人话: 容器就是存储数据的东西, 同时Python为了方便我们对容器中的数据进行增加删除修改查询专门提供了相应的方法便于我们操作
Python中常见容器有如下几种:
-
字符串
-
列表
-
元组
-
字典
-
集合
3.1字符串
-
字符串是 Python 中最常用的数据类型。我们可以使用引号( ' 或 " )来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'Hello World!' var2 = "itzyj"
-
Python 访问字符串中的值
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号 [] 来截取字符串,字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。

从后面索引
如下实例:
实例(Python 3.0+)
#!/usr/bin/python3 var1 = 'Hello World!' var2 = "itzyj" print ("var1[0]: ", var1[0]) print ("var2[1:5]: ", var2[1:5])
以上实例执行结果: var1[0]: H var2[1:5]: tzyj
Python 字符串更新
你可以截取字符串的一部分并与其他字段拼接,如下实例:
#!/usr/bin/python3
var1 = 'Hello World!'
print ("已更新字符串 : ", var1[:6] + 'itzyj!')以上实例执行结果
已更新字符串 : Hello itzyj!
Python 转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 ** 转义字符。如下表:
| 转义字符 | 描述 | 实例 |
|---|---|---|
| (在行尾时) | 续行符 | >>> print("line1 \ ... line2 \ ... line3") line1 line2 line3 >>> |
| \ | 反斜杠符号 | >>> print("\\") \ |
| ' | 单引号 | >>> print('\'') ' |
| " | 双引号 | >>> print("\"") " |
| \a | 响铃 | >>> print("\a")执行后电脑有响声。 |
| \b | 退格(Backspace) | >>> print("Hello \b World!") Hello World! |
| \000 | 空 | >>> print("\000") >>> |
| \n | 换行 | >>> print("\n") >>> |
| \v | 纵向制表符 | >>> print("Hello \v World!") Hello World! >>> |
| \t | 横向制表符 | >>> print("Hello \t World!") Hello World! >>> |
| \r | 回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 | >>> print("Hello\rWorld!") World! >>> print('google runoob taobao\r123456') 123456 runoob taobao |
| \f | 换页 | >>> print("Hello \f World!") Hello World! >>> |
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | >>> print("\110\145\154\154\157\40\127\157\162\154\144\41") Hello World! |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | >>> print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21") Hello World! |
| \other | 其它的字符以普通格式输出 |
使用 \r 实现百分比进度:
import time
for i in range(101):
print("\r{:3}%".format(i),end=' ')
time.sleep(0.05)以下实例,我们使用了不同的转义字符来演示单引号、换行符、制表符、退格符、换页符、ASCII、二进制、八进制数和十六进制数的效果:
print(''Hello, world!'') # 输出:'Hello, world!'
print("Hello, world!\nHow are you?") # 输出:Hello, world! # How are you?
print("Hello, world!\tHow are you?") # 输出:Hello, world! How are you?
print("Hello,\b world!") # 输出:Hello world!
print("Hello,\f world!") # 输出: # Hello, # world!
print("A 对应的 ASCII 值为:", ord('A')) # 输出:A 对应的 ASCII 值为: 65
print("\x41 为 A 的 ASCII 代码") # 输出:A 为 A 的 ASCII 代码
decimal_number = 42 binary_number = bin(decimal_number) # 十进制转换为二进制 print('转换为二进制:', binary_number) # 转换为二进制: 0b101010
octal_number = oct(decimal_number) # 十进制转换为八进制 print('转换为八进制:', octal_number) # 转换为八进制: 0o52
hexadecimal_number = hex(decimal_number) # 十进制转换为十六进制 print('转换为十六进制:', hexadecimal_number) # 转换为十六进制: 0x2a
Python 字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| *· | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | 'H' in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | 'M' not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print( r'\n' ) print( R'\n' ) |
| % | 格式字符串 | 请看上一节内容。 |
实例(Python 3.0+)
#!/usr/bin/python3
a = "Hello"
b = "Python"
print("a + b 输出结果:", a + b)
print("a * 2 输出结果:", a * 2)
print("a[1] 输出结果:", a[1])
print("a[1:4] 输出结果:", a[1:4])
if( "H" in a) :
print("H 在变量 a 中")
else : print("H 不在变量 a 中")
if( "M" not in a) :
print("M 不在变量 a 中")
else : print("M 在变量 a 中")
print (r'\n') print (R'\n')
以上实例输出结果为:
a + b 输出结果: HelloPython a * 2 输出结果: HelloHello a[1] 输出结果: e a[1:4] 输出结果: ell H 在变量 a 中 M 不在变量 a 中 \n \n
Python 字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
实例(Python 3.0+)
#!/usr/bin/python3 print ("我叫 %s 今年 %d 岁!" % ('小明', 10))
以上实例输出结果:
我叫 小明 今年 10 岁!
python字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
| 0 | 显示的数字前面填充'0'而不是默认的空格 |
| % | '%%'输出一个单一的'%' |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
Python三引号
python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。实例如下
实例(Python 3.0+)
#!/usr/bin/python3 para_str = """这是一个多行字符串的实例 多行字符串可以使用制表符 TAB ( \t )。 也可以使用换行符 [ \n ]。 """ print (para_str)
以上实例执行结果为:
这是一个多行字符串的实例 多行字符串可以使用制表符 TAB ( )。 也可以使用换行符 [ ]。
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。
一个典型的用例是,当你需要一块HTML或者SQL时,这时用字符串组合,特殊字符串转义将会非常的繁琐。
errHTML = ''' <HTML><HEAD><TITLE> Friends CGI Demo</TITLE></HEAD> <BODY><H3>ERROR</H3> %s<P> <FORM><INPUT TYPE=button VALUE=Back ONCLICK="window.history.back()"></FORM> </BODY></HTML> ''' cursor.execute(''' CREATE TABLE users ( login VARCHAR(8), uid INTEGER, prid INTEGER) ''')
f-string
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
之前我们习惯用百分号 (%):
实例
>>> name = 'itzyj'
>>> 'Hello %s' % name
'Hello itzyj'
f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去,实例如下:
实例
>>> name = 'itzyj'
>>> f'Hello {name}' # 替换变量
'Hello itzyj'
>>> f'{1+2}' # 使用表达式
'3'
>>> w = {'name': 'itzyj', 'url': 'www.runoob.com'}
>>> f'{w["name"]}: {w["url"]}'
'itzyj: www.runoob.com'
用了这种方式明显更简单了,不用再去判断使用 %s,还是 %d。
在 Python 3.8 的版本中可以使用 = 符号来拼接运算表达式与结果:
实例
>>> x = 1
>>> print(f'{x+1}') # Python 3.6
2
>>> x = 1
>>> print(f'{x+1=}') # Python 3.8
x+1=2
Unicode 字符串
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在Python3中,所有的字符串都是Unicode字符串。
Python 的字符串内建函数
Python 的字符串常用内建函数如下:
| 序号 | 方法及描述 |
|---|---|
| 1 | capitalize() 将字符串的第一个字符转换为大写 |
| 2 | center(width, fillchar)返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| 3 | count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| 4 | bytes.decode(encoding="utf-8", errors="strict") Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| 5 | encode(encoding='UTF-8',errors='strict') 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
| 6 | endswith(suffix, beg=0, end=len(string)) 检查字符串是否以 suffix 结束,如果 beg 或者 end 指定则检查指定的范围内是否以 suffix 结束,如果是,返回 True,否则返回 False。 |
| 7 | expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 | find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 | index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 |
| 10 | isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| 11 | isalpha() 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False |
| 12 | isdigit() 如果字符串只包含数字则返回 True 否则返回 False.. |
| 13 | islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 | isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 | isspace() 如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 | istitle() 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 | isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 | join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 | len(string) 返回字符串长度 |
| 20 | [ljust(width, fillchar]) 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 21 | lower() 转换字符串中所有大写字符为小写. |
| 22 | lstrip() 截掉字符串左边的空格或指定字符。 |
| 23 | maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 | max(str) 返回字符串 str 中最大的字母。 |
| 25 | min(str) 返回字符串 str 中最小的字母。 |
| 26 | [replace(old, new , max]) 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 |
| 27 | rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
| 28 | rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始. |
| 29 | [rjust(width,, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 | rstrip() 删除字符串末尾的空格或指定字符。 |
| 31 | split(str="", num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 |
| 32 | [splitlines(keepends]) 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 | startswith(substr, beg=0,end=len(string)) 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 | [strip(chars]) 在字符串上执行 lstrip()和 rstrip() |
| 35 | swapcase() 将字符串中大写转换为小写,小写转换为大写 |
| 36 | title() 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 | translate(table, deletechars="") 根据 table 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 | upper() 转换字符串中的小写字母为大写 |
| 39 | zfill (width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 | isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
3.2 列表
-
序列是 Python 中最基本的数据结构。
序列中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。
Python 有 6 个序列的内置类型,但最常见的是列表和元组。
列表都可以进行的操作包括索引,切片,加,乘,检查成员。
此外,Python 已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的 Python 数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['Google', 'itzyj', 1997, 2000] list2 = [1, 2, 3, 4, 5 ] list3 = ["a", "b", "c", "d"] list4 = ['red', 'green', 'blue', 'yellow', 'white', 'black']
访问列表中的值
与字符串的索引一样,列表索引从 0 开始,第二个索引是 1,依此类推。
通过索引列表可以进行截取、组合等操作。

实例
#!/usr/bin/python3
list = ['red', 'green', 'blue', 'yellow', 'white', 'black']
print( list[0] )
print( list[1] )
print( list[2] )以上实例输出结果:
red
green
blue
索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2,以此类推。

实例
#!/usr/bin/python3
list = ['red', 'green', 'blue', 'yellow', 'white', 'black']
print( list[-1] )
print( list[-2] )
print( list[-3] )以上实例输出结果:
black
white
yellow
使用下标索引来访问列表中的值,同样你也可以使用方括号 [] 的形式截取字符,如下所示:
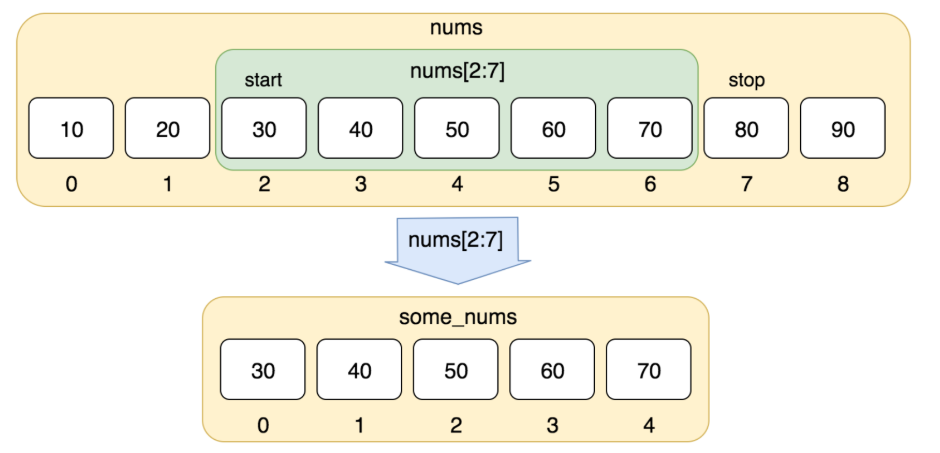
实例
#!/usr/bin/python3
nums = [10, 20, 30, 40, 50, 60, 70, 80, 90]
print(nums[0:4])以上实例输出结果:
[10, 20, 30, 40]
使用负数索引值截取:
实例
#!/usr/bin/python3
list = ['Google', 'itzyj', "Zhihu", "Taobao", "Wiki"]
# 读取第二位
print ("list[1]: ", list[1])
# 从第二位开始(包含)截取到倒数第二位(不包含)
print ("list[1:-2]: ", list[1:-2]) 以上实例输出结果:
list[1]: itzyj
list[1:-2]: ['itzyj', 'Zhihu']
更新列表
你可以对列表的数据项进行修改或更新,你也可以使用 append() 方法来添加列表项,如下所示:
实例(Python 3.0+)
#!/usr/bin/python3
list = ['Google', 'itzyj', 1997, 2000]
print ("第三个元素为 : ", list[2])
list[2] = 2001 print ("更新后的第三个元素为 : ", list[2])
list1 = ['Google', 'itzyj', 'Taobao']
list1.append('Baidu')
print ("更新后的列表 : ", list1)
注意:我们会在接下来的章节讨论 append() 方法的使用。
以上实例输出结果:
第三个元素为 : 1997 更新后的第三个元素为 : 2001 更新后的列表 : ['Google', 'itzyj', 'Taobao', 'Baidu']
删除列表元素
可以使用 del 语句来删除列表的的元素,如下实例:
实例(Python 3.0+)
#!/usr/bin/python3
list = ['Google', 'itzyj', 1997, 2000]
print ("原始列表 : ", list)
del list[2] print ("删除第三个元素 : ", list)
以上实例输出结果:
原始列表 : ['Google', 'itzyj', 1997, 2000] 删除第三个元素 : ['Google', 'itzyj', 2000]
注意:我们会在接下来的章节讨论 remove() 方法的使用
Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
| PYTHON 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
Python 列表截取与拼接
Python 的列表截取与字符串操作类似,如下所示:
L=['Google', 'itzyj, 'Taobao']
操作:
| PYTHON 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'Taobao' | 读取第三个元素 |
| L[-2] | 'itzyj' | 从右侧开始读取倒数第二个元素: count from the right |
| L[1:] | ['itzyj', 'Taobao'] | 输出从第二个元素开始后的所有元素 |
L=['Google', 'itzyj', 'Taobao'] print(L[2]) 'Taobao' print(L[-2]) 'itzyj' print(L[1:]) ['itzyj', 'Taobao'] #列表还支持拼接操作 squares = [1, 4, 9, 16, 25] squares += [36, 49, 64, 81, 100] print(squares) [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
嵌套列表
使用嵌套列表即在列表里创建其它列表,例如:
a = ['a', 'b', 'c'] n = [1, 2, 3] x = [a, n] print(x) [['a', 'b', 'c'], [1, 2, 3]] print(x[0]) ['a', 'b', 'c'] print(x[0][1]) 'b'
列表比较
列表比较需要引入 operator 模块的 eq 方法(详见:Python operator 模块):
实例
# 导入 operator 模块 import operator
a = [1, 2] b = [2, 3] c = [2, 3]
print("operator.eq(a,b): ", operator.eq(a,b)) print("operator.eq(c,b): ", operator.eq(c,b))
以上代码输出结果为:
operator.eq(a,b): False operator.eq(c,b): True
Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | len(list) 列表元素个数 |
| 2 | max(list) 返回列表元素最大值 |
| 3 | min(list) 返回列表元素最小值 |
| 4 | list(seq) 将元组转换为列表 |
Python包含以下方法: 5555556666
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop(index=-1) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort( key=None, reverse=False) 对原列表进行排序 |
| 10 | list.clear() 清空列表 |
| 11 | list.copy() 复制列表 |
3.3 元组
-
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号 ( ),列表使用方括号 [ ]。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。

实例(Python 3.0+)
>>> tup1 = ('Google', 'itzyj', 1997, 2000) >>> tup2 = (1, 2, 3, 4, 5 ) >>> tup3 = "a", "b", "c", "d" # 不需要括号也可以 >>> type(tup3) <class 'tuple'>
创建空元组
tup1 = ()
元组中只包含一个元素时,需要在元素后面添加逗号 , ,否则括号会被当作运算符使用:
实例(Python 3.0+)
>>> tup1 = (50) >>> type(tup1) # 不加逗号,类型为整型 <class 'int'>
>>> tup1 = (50,) >>> type(tup1) # 加上逗号,类型为元组 <class 'tuple'>
元组与字符串类似,下标索引从 0 开始,可以进行截取,组合等。
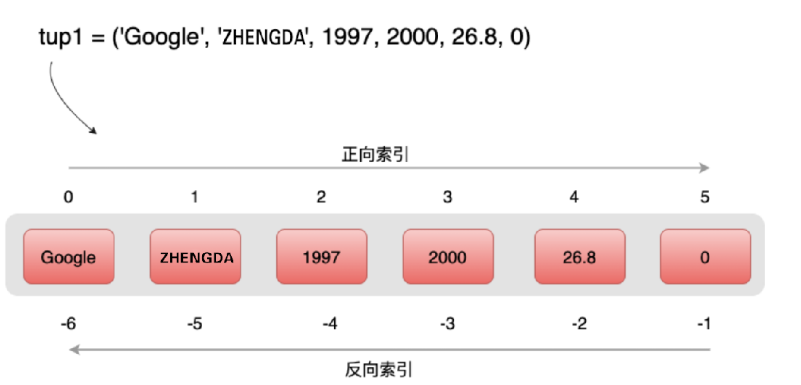
访问元组
元组可以使用下标索引来访问元组中的值,如下实例:
实例(Python 3.0+)
#!/usr/bin/python3 tup1 = ('Google', 'itzyj', 1997, 2000) tup2 = (1, 2, 3, 4, 5, 6, 7 ) print ("tup1[0]: ", tup1[0]) print ("tup2[1:5]: ", tup2[1:5])
以上实例输出结果:
tup1[0]: Google tup2[1:5]: (2, 3, 4, 5)
修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例:
实例(Python 3.0+)
#!/usr/bin/python3
tup1 = (12, 32.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print (tup3)
以上实例输出结果:
(12, 34.56, 'abc', 'xyz')
删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
实例(Python 3.0+)
#!/usr/bin/python3
tup = ('Google', 'itzyj', 1997, 2000)
print (tup)
del tup print ("删除后的元组 tup : ")
print (tup)
以上实例元组被删除后,输出变量会有异常信息,输出如下所示:
删除后的元组 tup :
Traceback (most recent call last):
File "test.py", line 8, in <module>
print (tup)
NameError: name 'tup' is not defined
元组运算符
与字符串一样,元组之间可以使用 +、+=和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| PYTHON 表达式 | 结果 | 描述 |
|---|---|---|
len((1, 2, 3)) | 3 | 计算元素个数 |
>>> a = (1, 2, 3) >>> b = (4, 5, 6) >>> c = a+b >>> c (1, 2, 3, 4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接,c 就是一个新的元组,它包含了 a 和 b 中的所有元素。 |
>>> a = (1, 2, 3) >>> b = (4, 5, 6) >>> a += b >>> a (1, 2, 3, 4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接,a 就变成了一个新的元组,它包含了 a 和 b 中的所有元素。 |
('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
3 in (1, 2, 3) | True | 元素是否存在 |
for x in (1, 2, 3): print (x, end=" ") | 1 2 3 | 迭代 |
元组索引,截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下所示:
元组:
tup = ('Google', 'itzyj', 'Taobao', 'Wiki', 'Weibo','Weixin')

| PYTHON 表达式 | 结果 | 描述 |
|---|---|---|
| tup[1] | 'itzyj' | 读取第二个元素 |
| tup[-2] | 'Weibo' | 反向读取,读取倒数第二个元素 |
| tup[1:] | ('itzyj', 'Taobao', 'Wiki', 'Weibo', 'Weixin') | 截取元素,从第二个开始后的所有元素。 |
| tup[1:4] | ('itzyj', 'Taobao', 'Wiki') | 截取元素,从第二个开始到第四个元素(索引为 3)。 |
运行实例如下:
实例
tup = ('Google', 'itzyj', 'Taobao', 'Wiki', 'Weibo','Weixin')
print(tup[1])
'itzyj'
print(tup[-2])
'Weibo'
print(tup[1:])
('itzyj', 'Taobao', 'Wiki', 'Weibo', 'Weixin')
print(tup[1:4])
('itzyj', 'Taobao', 'Wiki')
元组内置函数
Python元组包含了以下内置函数
| 序号 | 方法及描述 | 实例 |
|---|---|---|
| 1 | len(tuple) 计算元组元素个数。 | >>> tuple1 = ('Google', 'itzyj', 'Taobao') >>> len(tuple1) 3 >>> |
| 2 | max(tuple) 返回元组中元素最大值。 | >>> tuple2 = ('5', '4', '8') >>> max(tuple2) '8' >>> |
| 3 | min(tuple) 返回元组中元素最小值。 | >>> tuple2 = ('5', '4', '8') >>> min(tuple2) '4' >>> |
| 4 | tuple(iterable) 将可迭代系列转换为元组。 | >>> list1= ['Google', 'Taobao', 'itzyj', 'Baidu'] >>> tuple1=tuple(list1) >>> tuple1 ('Google', 'Taobao', 'itzyj', 'Baidu') |
关于元组是不可变的
#所谓元组的不可变指的是元组所指向的内存中的内容不可变。
tup = ('r', 'u', 'n', 'o', 'o', 'b')
tup[0] = 'g' # 不支持修改元素
Traceback (most recent call last):
File "<stdin>", line 1, **in** <module>
TypeError: 'tuple' object does **not** support item assignment
id(tup) # 查看内存地址
4440687904
tup = (1,2,3)
id(tup)
4441088800 # 内存地址不一样了
3.4 字典
-
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2, key3 : value3 }注意:**dict** 作为 Python 的关键字和内置函数,变量名不建议命名为 dict。
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
一个简单的字典实例:
tinydict = {'name': 'itzyj', 'likes': 123, 'url': 'www.itzyj.com'}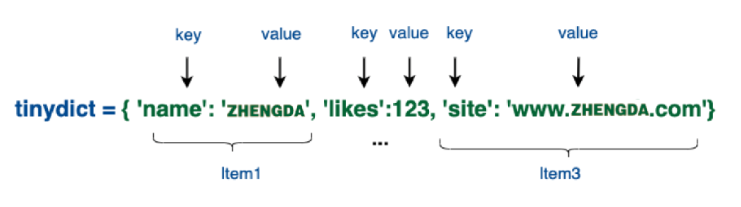
也可如此创建字典:
tinydict1 = { 'abc': 456 } tinydict2 = { 'abc': 123, 98.6: 37 }
创建空字典
使用大括号 { } 创建空字典:
实例
# 使用大括号 {} 来创建空字典 emptyDict = {} # 打印字典 print(emptyDict) # 查看字典的数量 print("Length:", len(emptyDict)) # 查看类型 print(type(emptyDict))以上实例输出结果:
{} Length: 0 <class 'dict'>使用内建函数 dict() 创建字典:
实例
emptyDict = dict() # 打印字典 print(emptyDict) # 查看字典的数量 print("Length:",len(emptyDict)) # 查看类型 print(type(emptyDict))以上实例输出结果:
{} Length: 0 <class 'dict'>
访问字典里的值
把相应的键放入到方括号中,如下实例:
实例
#!/usr/bin/python3 tinydict = {'Name': 'itzyj', 'Age': 7, 'Class': 'First'} print ("tinydict['Name']: ", tinydict['Name']) print ("tinydict['Age']: ", tinydict['Age'])以上实例输出结果:
tinydict['Name']: itzyj tinydict['Age']: 7
如果用字典里没有的键访问数据,会输出错误如下:
实例
#!/usr/bin/python3 tinydict = {'Name': 'itzyj', 'Age': 7, 'Class': 'First'} print ("tinydict['Alice']: ", tinydict['Alice'])以上实例输出结果:
Traceback (most recent call last): File "test.py", line 5, in <module> print ("tinydict['Alice']: ", tinydict['Alice']) KeyError: 'Alice'
------
## 修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
## 实例
```PYTHON
#!/usr/bin/python3
tinydict = {'Name': 'itzyj', 'Age': 7, 'Class': 'First'}
tinydict['Age'] = 8 # 更新 Age
tinydict['School'] = "职业培训学校" # 添加信息
print ("tinydict['Age']: ", tinydict['Age'])
print ("tinydict['School']: ", tinydict['School'])
以上实例输出结果:
tinydict['Age']: 8 tinydict['School']: xxxx
删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显式删除一个字典用del命令,如下实例:
实例
#!/usr/bin/python3
tinydict = {'Name': 'itzyj', 'Age': 7, 'Class': 'First'}
del tinydict['Name']
# 删除键 'Name' tinydict.clear()
# 清空字典 del tinydict
# 删除字典 print ("tinydict['Age']: ", tinydict['Age'])
print ("tinydict['School']: ", tinydict['School'])
但这会引发一个异常,因为用执行 del 操作后字典不再存在:
Traceback (most recent call last):
File "/runoob-test/test.py", line 9, in <module>
print ("tinydict['Age']: ", tinydict['Age'])
NameError: name 'tinydict' is not defined
注:del() 方法后面也会讨论。
字典键的特性
字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
实例
#!/usr/bin/python3
tinydict = {'Name': 'itzyj', 'Age': 7, 'Name': '菜鸡'}
print ("tinydict['Name']: ", tinydict['Name'])
以上实例输出结果:
tinydict['Name']: 菜鸡
2)键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行,如下实例:
实例
#!/usr/bin/python3
tinydict = {['Name']: 'itzyj', 'Age': 7}
print ("tinydict['Name']: ", tinydict['Name'])
以上实例输出结果:
Traceback (most recent call last):
File "test.py", line 3, in <module>
tinydict = {['Name']: 'itzyj', 'Age': 7}
TypeError: unhashable type: 'list'
字典内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数及描述 | 实例 |
|---|---|---|
| 1 | len(dict) 计算字典元素个数,即键的总数。 | >>> tinydict = {'Name': 'itzyj', 'Age': 7, 'Class': 'First'} >>> len(tinydict) 3 |
| 2 | str(dict) 输出字典,可以打印的字符串表示。 | >>> tinydict = {'Name': 'itzyj', 'Age': 7, 'Class': 'First'} >>> str(tinydict) "{'Name': 'itzyj', 'Class': 'First', 'Age': 7}" |
| 3 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 | >>> tinydict = {'Name': 'itzyj', 'Age': 7, 'Class': 'First'} >>> type(tinydict) <class 'dict'> |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | key in dict 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回一个视图对象 |
| 7 | dict.keys() 返回一个视图对象 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 返回一个视图对象 |
| 11 | [pop(key,default]) 删除字典 key(键)所对应的值,返回被删除的值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
3.5 集合
-
集合(set)是一个无序的不重复元素序列。
集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
可以使用大括号 { } 创建集合,元素之间用逗号 , 分隔, 或者也可以使用 set() 函数创建集合。
创建格式:
parame = {value01,value02,...} 或者 set(value)以下是一个简单实例:
set1 = {1, 2, 3, 4} # 直接使用大括号创建集合 set2 = set([4, 5, 6, 7]) # 使用 set() 函数从列表创建集合注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
更多实例演示:
实例(Python 3.0+)
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} >>> print(basket) # 这里演示的是去重功能 {'orange', 'banana', 'pear', 'apple'} >>> 'orange' in basket # 快速判断元素是否在集合内 True >>> 'crabgrass' in basket False
>>> # 下面展示两个集合间的运算. ... >>> a = set('abracadabra') >>> b = set('alacazam') >>> a {'a', 'r', 'b', 'c', 'd'} >>> a - b # 集合a中包含而集合b中不包含的元素 {'r', 'd', 'b'} >>> a | b # 集合a或b中包含的所有元素 {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'} >>> a & b # 集合a和b中都包含了的元素 {'a', 'c'} >>> a ^ b # 不同时包含于a和b的元素 {'r', 'd', 'b', 'm', 'z', 'l'}
类似列表推导式,同样集合支持集合推导式(Set comprehension):
实例(Python 3.0+)
>>> a = {x for x in 'abracadabra' if x not in 'abc'} >>> a {'r', 'd'}
集合的基本操作
1、添加元素
语法格式如下:
s.add( x )
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
实例(Python 3.0+)
>>> thisset = set(("Google", "itzyj", "TIANMAO")) >>> thisset.add("Facebook") >>> print(thisset) {'TIANMAO', 'Facebook', 'Google', 'itzyj'}
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:
s.update( x )
x 可以有多个,用逗号分开。
实例(Python 3.0+)
>>> thisset = set(("Google", "itzyj", "TIANMAO")) >>> thisset.update({1,3}) >>> print(thisset) {1, 3, 'Google', 'TIANMAO', 'itzyj'} >>> thisset.update([1,4],[5,6]) >>> print(thisset) {1, 3, 4, 5, 6, 'Google', 'TIANMAO', 'itzyj'} >>>
2、移除元素
语法格式如下:
s.remove( x )
将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
实例(Python 3.0+)
>>> thisset = set(("Google", "itzyj", "TIANMAO")) >>> thisset.remove("TIANMAO") >>> print(thisset) {'Google', 'itzyj'} >>> thisset.remove("Facebook") # 不存在会发生错误 Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'Facebook' >>>
此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:
s.discard( x )
实例(Python 3.0+)
>>> thisset = set(("Google", "itzyj", "TIANMAO")) >>> thisset.discard("Facebook") # 不存在不会发生错误 >>> print(thisset) {'TIANMAO', 'Google', 'itzyj'}
我们也可以设置随机删除集合中的一个元素,语法格式如下:
s.pop()
脚本模式实例(Python 3.0+)
thisset = set(("Google", "itzyj", "TIANMAO", "Facebook")) x = thisset.pop()
print(x)
输出结果:
itzyj
多次执行测试结果都不一样。
set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除。
3、计算集合元素个数
语法格式如下:
len(s)
计算集合 s 元素个数。
实例(Python 3.0+)
>>> thisset = set(("Google", "itzyj", "TIANMAO")) >>> len(thisset) 3
4、清空集合
语法格式如下:
s.clear()
清空集合 s。
实例(Python 3.0+)
>>> thisset = set(("Google", "itzyj", "TIANMAO")) >>> thisset.clear() >>> print(thisset) set()
5、判断元素是否在集合中存在
语法格式如下:
x in s
判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False。
实例(Python 3.0+)
>>> thisset = set(("Google", "itzyj", "TIANMAO")) >>> "itzyj" in thisset True >>> "Facebook" in thisset False >>>
集合内置方法完整列表
方法 描述 add() 为集合添加元素 clear() 移除集合中的所有元素 copy() 拷贝一个集合 difference() 返回多个集合的差集 difference_update() 移除集合中的元素,该元素在指定的集合也存在。 discard() 删除集合中指定的元素 intersection() 返回集合的交集 intersection_update() 返回集合的交集。 isdisjoint() 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 issubset() 判断指定集合是否为该方法参数集合的子集。 issuperset() 判断该方法的参数集合是否为指定集合的子集 pop() 随机移除元素 remove() 移除指定元素 symmetric_difference() 返回两个集合中不重复的元素集合。 symmetric_difference_update() 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 union() 返回两个集合的并集 update() 给集合添加元素 len() 计算集合元素个数
3.6 公共方法
-
运算符
| 运算符 | 描述 | 支持的容器类型 |
|---|---|---|
| + | 合并 | 字符串、列表、元组 |
| * | 复制 | 字符串、列表、元组 |
| in | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 元素是否不存在 | 字符串、列表、元组、字典 |
-
+运算
# 1. 字符串 str1 = 'aa' str2 = 'bb' str3 = str1 + str2 print(str3) # aabb # 2. 列表 list1 = [1, 2] list2 = [10, 20] list3 = list1 + list2 print(list3) # [1, 2, 10, 20] # 3. 元组 t1 = (1, 2) t2 = (10, 20) t3 = t1 + t2 print(t3) # (10, 20, 100, 200)
-
*运算
# 1. 字符串
print('-' * 10) # ----------
# 2. 列表
list1 = ['hello']
print(list1 * 4) # ['hello', 'hello', 'hello', 'hello']
# 3. 元组
t1 = ('world',)
print(t1 * 4) # ('world', 'world', 'world', 'world')
-
in或not in
# 1. 字符串
print('a' in 'abcd') # True
print('a' not in 'abcd') # False
# 2. 列表
list1 = ['a', 'b', 'c', 'd']
print('a' in list1) # True
print('a' not in list1) # False
# 3. 元组
t1 = ('a', 'b', 'c', 'd')
print('aa' in t1) # False
print('aa' not in t1) # True
-
公共方法
| 函数 | 描述 |
|---|---|
| len() | 计算容器中元素个数 |
| del 或 del() | 删除 |
| max() | 返回容器中元素最大值 |
| min() | 返回容器中元素最小值 |
-
len()
# 1. 字符串
str1 = 'abcdefg'
print(len(str1)) # 7
# 2. 列表
list1 = [10, 20, 30, 40]
print(len(list1)) # 4
# 3. 元组
t1 = (10, 20, 30, 40, 50)
print(len(t1)) # 5
# 4. 集合
s1 = {10, 20, 30}
print(len(s1)) # 3
# 2. 字典
dict1 = {'name': 'Rose', 'age': 18}
print(len(dict1)) # 2
-
del()
# 1. 字符串 str1 = 'abcdefg' del str1 print(str1) # 2. 列表 list1 = [10, 20, 30, 40] del(list1[0]) print(list1) # [20, 30, 40]
-
max()
# 1. 字符串 str1 = 'abcdefg' print(max(str1)) # g # 2. 列表 list1 = [10, 20, 30, 40] print(max(list1)) # 40
-
min()
# 1. 字符串 str1 = 'abcdefg' print(min(str1)) # a # 2. 列表 list1 = [10, 20, 30, 40] print(min(list1)) # 10
#
4. python的函数
python的函数可以简单理解为java的方法, 但是要比java的方法更加的灵活
4.1 函数基本使用
-
定义的格式:
def 函数名(参数):
代码1
代码2
......
-
调用函数:
函数名(参数)
不同的需求,参数可有可无。
在Python中,函数必须
先定义后使用
简单体验:
-
需求: 定义一个ATM机的功能函数:
-
输出: 查询余额 存款 取款 几个内容
-
# 封装ATM机功能选项 -- 定义函数
def select_func():
print('-----请选择功能-----')
print('查询余额')
print('存款')
print('取款')
print('-----请选择功能-----')
调用函数:
select_func()
4.2 函数的参数
# 定义函数时同时定义了接收用户数据的参数a和b,a和b是形参
def add_num2(a, b):
result = a + b
print(result)
# 调用函数时传入了真实的数据10 和 20,真实数据为实参
add_num2(10, 20)
4.3 函数的返回值
在python中, 函数也是可以有返回值的, 我们可以使用return 进行返回
def add2num(a, b):
c = a+b
return c
或者:
def add2num(a, b):
return a+b
调用函数时, 我们可以接收其返回值
#定义函数
def add2num(a, b):
return a+b
#调用函数,顺便保存函数的返回值
result = add2num(100,98)
#因为result已经保存了add2num的返回值,所以接下来就可以使用了
print(result)
4.4 函数的嵌套使用
例如:
def testB():
print('---- testB start----')
print('这里是testB函数执行的代码...(省略)...')
print('---- testB end----')
def testA():
print('---- testA start----')
testB()
print('---- testA end----')
testA()
4.5 函数的应用
需求:
-
写一个函数打印一条横线
-
打印自定义行数的横线
# 打印一条横线
def print_one_line():
print("-"*30)
# 打印多条横线
def print_num_line(num):
i=0
# 因为printOneLine函数已经完成了打印横线的功能,
# 只需要多次调用此函数即可
while i<num:
print_one_line()
i+=1
print_num_line(3)
需求:
-
写一个函数求三个数的和
-
写一个函数求三个数的平均值
# 求3个数的和
def sum3number(a,b,c):
return a+b+c # return 的后面可以是数值,也可是一个表达式
# 完成对3个数求平均值
def average3number(a,b,c):
# 因为sum3Number函数已经完成了3个数的就和,所以只需调用即可
# 即把接收到的3个数,当做实参传递即可
sum_result = sum3number(a,b,c)
ave_result = sum_result/3.0
return ave_result
# 调用函数,完成对3个数求平均值
result = average3number(11,2,55)
print("average is %d"%result)
4.6 变量的作用域
变量作用域指的是变量生效的范围,主要分为两类:局部变量和全局变量
-
局部变量:
-
所谓局部变量是定义在函数体内部的变量,即只在函数体内部生效。
-
def testA():
a = 100
print(a)
# 调用:
testA() # 100
# 直接打印变量a
print(a) # 报错:name 'a' is not defined
局部变量的作用:在函数体内部,临时保存数据,即当函数调用完成后,则销毁局部变量。
-
全局变量:
-
所谓全局变量,指的是在函数体内、外都能生效的变量。
-
# 定义全局变量a
a = 100
def testA():
print(a) # 访问全局变量a,并打印变量a存储的数据
def testB():
print(a) # 访问全局变量a,并打印变量a存储的数据
testA() # 100
testB() # 100
思考:testB函数需求修改变量a的值为200,如何修改程序?
a = 100
def testA():
print(a)
def testB():
a = 200
print(a)
testA() # 100
testB() # 200
print(f'全局变量a = {a}') # 全局变量a = 100
思考:在testB函数内部的a = 200中的变量a是在修改全局变量a吗?
答:不是。观察上述代码发现,15行得到a的数据是100,仍然是定义全局变量a时候的值,而没有返回
testB函数内部的200。综上:testB函数内部的a = 200是定义了一个局部变量。
思考:如何在函数体内部修改全局变量?
a = 100
def testA():
print(a)
def testB():
# global 关键字声明a是全局变量
global a
a = 200
print(a)
testA() # 100
testB() # 200
print(f'全局变量a = {a}') # 全局变量a = 200
4.7 函数返回多个返回值
思考:如果一个函数如些两个return (如下所示),程序如何执行?
def return_num():
return 1
return 2
result = return_num()
print(result) # 1
答:只执行了第一个return,原因是因为return可以退出当前函数,导致return下方的代码不执行。
思考:如果一个函数要有多个返回值,该如何书写代码?
def return_num():
return 1, 2
result = return_num()
print(result) # (1, 2)
注意:
-
return a, b写法,返回多个数据的时候,默认是元组类型。 -
return后面可以连接列表、元组或字典,以返回多个值。
4.8 函数的多种参数
-
1- 位置参数
-
位置参数:调用函数时根据函数定义的参数位置来传递参数。
-
def user_info(name, age, gender):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('TOM', 20, '男')
注意:传递和定义参数的顺序及个数必须一致。
-
2- 关键字参数
-
函数调用,通过“键=值”形式加以指定。可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求。
-
def user_info(name, age, gender):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('Rose', age=20, gender='女')
user_info('小明', gender='男', age=16)
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序。
-
3- 缺省参数
-
缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)。
-
def user_info(name, age, gender='男'):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('TOM', 20)
user_info('Rose', 18, '女')
注意:函数调用时,如果为缺省参数传值则修改默认参数值;否则使用这个默认值。
-
4- 不定长参数
-
不定长参数也叫可变参数。用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。此时,可用包裹(packing)位置参数,或者包裹关键字参数,来进行参数传递,会显得非常方便。
-
#包裹位置传递
def user_info(*args):
print(args)
# ('TOM',)
user_info('TOM')
# ('TOM', 18)
user_info('TOM', 18)
#包裹关键字传递
def user_info(**kwargs):
print(kwargs)
# {'name': 'TOM', 'age': 18, 'id': 110}
user_info(name='TOM', age=18, id=110)
4.9 拆包和交换变量值
-
拆包
-
拆包:元组
def return_num():
return 100, 200
num1, num2 = return_num()
print(num1) # 100
print(num2) # 200
-
交换变量值
需求:有变量
a = 10和b = 20,交换两个变量的值。-
方法一
借助第三变量存储数据。
# 1. 定义中间变量 c = 0 # 2. 将a的数据存储到c c = a # 3. 将b的数据20赋值到a,此时a = 20 a = b # 4. 将之前c的数据10赋值到b,此时b = 10 b = c print(a) # 20 print(b) # 10
-
方法二
a, b = 1, 2 a, b = b, a print(a) # 2 print(b) # 1
-
-
可变和不可变类型
所谓可变类型与不可变类型是指:数据能够直接进行修改,如果能直接修改那么就是可变,否则是不可变.
-
可变类型
-
列表
-
字典
-
集合
-
-
不可变类型
-
整型
-
浮点型
-
字符串
-
元组
-
-
4.10 引用
-
了解引用
在python中,值是靠引用来传递来的。
我们可以用
id()来判断两个变量是否为同一个值的引用。 我们可以将id值理解为那块内存的地址标识。
# 1. int类型 a = 1 b = a print(b) # 1 print(id(a)) # 140708464157520 print(id(b)) # 140708464157520 a = 2 print(b) # 1,说明int类型为不可变类型 print(id(a)) # 140708464157552,此时得到是的数据2的内存地址 print(id(b)) # 140708464157520 # 2. 列表 aa = [10, 20] bb = aa print(id(aa)) # 2325297783432 print(id(bb)) # 2325297783432 aa.append(30) print(bb) # [10, 20, 30], 列表为可变类型 print(id(aa)) # 2325297783432 print(id(bb)) # 2325297783432
-
引用当做实参
代码如下:
def test1(a):
print(a)
print(id(a))
a += a
print(a)
print(id(a))
# int:计算前后id值不同
b = 100
test1(b)
# 列表:计算前后id值相同
c = [11, 22]
test1(c)
4.11 匿名函数
-
lambda语法
用lambda关键词能创建小型匿名函数, 这种函数得名于省略了用def声明函数的标准步骤.
lambda 参数列表 : 表达式
注意
lambda表达式的参数可有可无,函数的参数在lambda表达式中完全适用。
lambda表达式能接收任何数量的参数但只能返回一个表达式的值。
-
快速入门
# 函数
def fn1():
return 200
print(fn1)
print(fn1())
# lambda表达式
fn2 = lambda: 100
print(fn2)
print(fn2())
注意:直接打印lambda表达式,输出的是此lambda的内存地址
-
-
示例:计算a + b
函数实现
-
def add(a, b):
return a + b
result = add(1, 2)
print(result)
思考:需求简单,是否代码多?
lambda实现
fn1 = lambda a, b: a + b print(fn1(1, 2))
-
lambda的应用
在之前的参数学习时, 参数只能是一个具体的数值, 字符串. 然而很多时候我们可能需要的参数不仅仅值一个简单的数值而已, 有可能是一种算法, 一个公式, 一种功能. lambda表达式就可以作为参数来使用, 这样去传递参数不仅仅传递的是某个数值.
# func函数相当于一个计算器
def func(count):
a = 10
b = 20
result = count(a, b)
print(result)
# 传递相加
func(lambda a, b: a + b)
# 传递相减
func(lambda a, b: a - b)
# 传递相乘
func(lambda a, b: a * b)
# 传递相除
func(lambda a, b: a / b)
5. 文件的基本操作
文件操作的基本步骤:
-
打开文件
-
对文件进行相关的操作
-
关闭文件
注意:可以只打开和关闭文件,不进行任何读写操作
-
打开文件
在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
open(name, mode)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
扩展说明: 打开文件的模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
快速体验
f = open('test.txt', 'w')
注意:此时的
f是open函数的文件对象。
文件的读写
-
写 write()
-
语法
对象对象.write('内容')-
体验
# 1. 打开文件 f = open('test.txt', 'w') # 2.文件写入 f.write('hello world') # 3. 关闭文件 f.close()注意:
-
w和a模式:如果文件不存在则创建该文件;如果文件存在,w模式先清空再写入,a模式直接末尾追加。 -
r模式:如果文件不存在则报错。
-
-
读read()
文件对象.read(num)
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
-
readlines()
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
f = open('test.txt') content = f.readlines() # ['hello world\n', 'abcdefg\n', 'aaa\n', 'bbb\n', 'ccc'] print(content) # 关闭文件 f.close()-
readline() : 一次读取一行内容。
f = open('test.txt') content = f.readline() print(f'第一行:{content}') content = f.readline() print(f'第二行:{content}') # 关闭文件 f.close() -
-
关闭
文件对象.close()
6. 文件备份
需求:用户输入当前目录下任意文件名,程序完成对该文件的备份功能(备份文件名为xx[备份]后缀,例如:test[备份].txt)。
步骤
-
接收用户输入的文件名
-
规划备份文件名
-
备份文件写入数据
代码实现
-
接收用户输入目标文件名
old_name = input('请输入您要备份的文件名:')
-
规划备份文件名
2.1 提取目标文件后缀
2.2 组织备份的文件名,xx[备份]后缀
# 2.1 提取文件后缀点的下标
index = old_name.rfind('.')
# print(index) # 后缀中.的下标
# print(old_name[:index]) # 源文件名(无后缀)
# 2.2 组织新文件名 旧文件名 + [备份] + 后缀
new_name = old_name[:index] + '[备份]' + old_name[index:]
# 打印新文件名(带后缀)
# print(new_name)
-
备份文件写入数据
3.1 打开源文件 和 备份文件
3.2 将源文件数据写入备份文件
3.3 关闭文件
# 3.1 打开文件
old_f = open(old_name, 'rb')
new_f = open(new_name, 'wb')
# 3.2 将源文件数据写入备份文件
# .read(1024) 返回读取的结果,这样当内存小于文件大小时,可以分批读取文件,并进行操作。
while True:
con = old_f.read(1024)
if len(con) == 0:
break
new_f.write(con)
# 3.3 关闭文件
old_f.close()
new_f.close()
7. 异常
1. 了解异常
当检测到一个错误时,解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的"异常"。
例如:以r方式打开一个不存在的文件。
open('test.txt', 'r')
2. 异常的写法
-
语法
try:
可能发生错误的代码
except Exception:
如果出现异常执行的代码
-
快速体验
需求:尝试以
r模式打开文件,如果文件不存在,则以w方式打开。
try:
f = open('test.txt', 'r')
except:
f = open('test.txt', 'w')
3. 捕获指定异常
-
语法
try:
可能发生错误的代码
except 异常类型:
如果捕获到该异常类型执行的代码
-
体验
try:
print(num)
except NameError:
print('有错误')
注意:
如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
一般try下方只放一行尝试执行的代码。
-
捕获多个指定异常
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except 后,并使用元组的方式进行书写。
try:
print(1/0)
except (NameError, ZeroDivisionError):
print('有错误')
-
捕获异常描述信息
try:
print(num)
except (NameError, ZeroDivisionError) as result:
print(result)
-
捕获所有异常
Exception是所有程序异常类的父类。
try:
print(num)
except Exception as result:
print(result)
4. 异常的else
else表示的是如果没有异常要执行的代码。
try:
print(1)
except Exception as result:
print(result)
else:
print('我是else,是没有异常的时候执行的代码')
5. 异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件。
try:
f = open('test.txt', 'r')
except Exception as result:
f = open('test.txt', 'w')
else:
print('没有异常,真开心')
finally:
f.close()
6. 异常处理案例
体验异常传递
需求:
-
尝试只读方式打开test.txt文件,如果文件存在则读取文件内容,文件不存在则提示用户即可。
-
读取内容要求:尝试循环读取内容,读取过程中如果检测到用户意外终止程序,则
except捕获异常并提示用户。
import time
try:
f = open('test.txt')
try:
while True:
content = f.readline()
if len(content) == 0:
break
time.sleep(2)
print(content)
except:
# 如果在读取文件的过程中,产生了异常,那么就会捕获到
# 比如 按下了 ctrl+c
print('意外终止了读取数据')
finally:
f.close()
print('关闭文件')
except:
print("没有这个文件")
8. 模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。
模块能定义函数,类和变量,模块里也能包含可执行的代码
8.1 导入模块
-
导入模块的方式
-
import 模块名
-
from 模块名 import 功能名
-
from 模块名 import *
-
import 模块名 as 别名
-
from 模块名 import 功能名 as 别名
-
导入方式详解
import
-
语法
# 1. 导入模块 import 模块名 import 模块名1, 模块名2... # 2. 调用功能 模块名.功能名()
-
体验
import math print(math.sqrt(9)) # 3.0 from..import..
-
语法
from 模块名 import 功能1, 功能2, 功能3...
-
体验
from math import sqrt print(sqrt(9)) from .. import *
-
语法
from 模块名 import *
-
体验
from math import * print(sqrt(9)) as定义别名
-
语法
# 模块定义别名 import 模块名 as 别名 # 功能定义别名 from 模块名 import 功能 as 别名
-
体验
# 模块别名
import time as tt
tt.sleep(2)
print('hello')
# 功能别名
from time import sleep as sl
sl(2)
print('hello')
8.2 制作模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。也就是说自定义模块名必须要符合标识符命名规则。
-
定义模块
新建一个Python文件,命名为
my_module1.py,并定义testA函数。
def testA(a, b):
print(a + b)
-
测试模块
在实际开发中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息.,例如,在my_module1.py文件中添加测试代码。
def testA(a, b):
print(a + b)
testA(1, 1)
此时,无论是当前文件,还是其他已经导入了该模块的文件,在运行的时候都会自动执行testA函数的调用。
解决办法如下:
def testA(a, b):
print(a + b)
# 只在当前文件中调用该函数,其他导入的文件内不符合该条件,则不执行testA函数调用
if __name__ == '__main__':
testA(1, 1)
-
调用模块
import my_module1 my_module1.testA(1, 1)
-
注意事项
如果使用
from .. import ..或from .. import *导入多个模块的时候,且模块内有同名功能。当调用这个同名功能的时候,调用到的是后面导入的模块的功能。 -
体验`
# 模块1代码
def my_test(a, b):
print(a + b)
# 模块2代码
def my_test(a, b):
print(a - b)
# 导入模块和调用功能代码
from my_module1 import my_test
from my_module2 import my_test
# my_test函数是模块2中的函数
my_test(1, 1)
8.3 __all__ 变量
如果一个模块文件中有__all__变量,当使用from xxx import *导入时,只能导入这个列表中的元素。
-
my_module1模块代码
__all__ = ['testA']
def testA():
print('testA')
def testB():
print('testB')
-
导入模块的文件代码
from my_module1 import * testA() testB()
8.4 包
包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为__init__.py 文件,那么这个文件夹就称之为包。
-
制作包
[New] — [Python Package] — 输入包名 — [OK] — 新建功能模块(有联系的模块)。
注意:新建包后,包内部会自动创建
__init__.py文件,这个文件控制着包的导入行为。 -
快速体验
-
新建包
mypackage -
新建包内模块:
my_module1和my_module2 -
模块内代码如下
-
# my_module1
print(1)
def info_print1():
print('my_module1')
# my_module2
print(2)
def info_print2():
print('my_module2')
-
导入包
方法一
import 包名.模块名 包名.模块名.目标
操作:
import my_package.my_module1 my_package.my_module1.info_print1()
方法二
注意:必须在__init__.py文件中添加__all__ = [],控制允许导入的模块列表。
from 包名 import * 模块名.目标
操作:
from my_package import * my_module1.info_print1()
8.5 常用模块说明
8.5.1 sys模块
sys是system的缩写,用来获取操作系统和编译器的一些配置,设置及操作。
-
1- sys.argv
-
可以用sys.argv获取当前正在执行的命令行参数的参数列表(list)。
-
类似于: 编写一个shell脚本, 然后执行shell脚本, 外部传递参数
-
import sys
print(sys.argv)
print(sys.argv[0])
print(sys.argv[1])
print("第二个参数:%s"%sys.argv[2])
print("参数个数:%s"%(len(sys.argv)-1))
-------------------结果:
#python /root/mcw.py arg1 arg2
['/root/mcw.py', 'arg1', 'arg2']
/root/mcw.py #当前程序名
arg1
第二个参数:arg2
参数个数:2
-
2- sys.platform
-
获取当前执行环境的平台,如win32表示是Windows系统,linux2表示是linux平台
-
# 在win环境执行 print(sys.platform) -------------结果: win32
# linux环境执行 test.py [itzyj@linux02 mypackage]$ python test.py -------------结果: linux
-
3- sys.exit(n)
-
调用sys.exit(n)可以中途退出程序,当参数非0时,会引发一个SystemExit异常,从而可以在主程序中捕获该异常。
-
# 在linux环境执行python代码 test2.py 文件内容如上图 [itzyj@linux02 mypackage]$ python test2.py [itzyj@linux02 mypackage]$ echo $? 3 [itzyj@linux02 mypackage]$
8.5.2 os模块
OS模块是Python中用于与操作系统进行交互的标准库模块。它提供了大量的函数,允许Python程序员在程序中执行与文件系统、进程管理、环境变量等相关的操作。OS模块是Python进行系统级编程的重要工具。
OS模块主要功能
-
文件和目录操作
创建、删除、移动文件和目录
import os os.makedirs('new_directory', exist_ok=True) # 创建目录 os.remove('example.txt') # 删除文件 -
环境变量访问
获取和设置环境变量
import os os.environ['MY_VARIABLE'] = 'my_value' # 设置环境变量
-
获取当前目录(当前工作目录)
使用
os.getcwd()函数可以获取当前工作目录(即当前Python脚本执行的目录)import os current_directory = os.getcwd() print(current_directory)
-
获取文件的绝对路径
如果你有一个相对于当前工作目录的文件路径,并且想要得到这个文件的绝对路径,你可以使用os.path.abspath()函数
import os relative_path = "example_file.txt" # 假设有一个相对于当前工作目录的文件或目录名 absolute_path = os.path.abspath(relative_path) print(absolute_path)
8.5.3 Pathlib模块
-
创建Path对象
通过Path对象可以方便地进行文件路径的操作
from pathlib import Path p = Path('/usr/bin') -
文件路径拼接
使用
/操作符可以方便地拼接路径。示例:
from pathlib import Path folder = Path('/usr') filename = Path('example.txt') path = folder / filename -
基本操作
获取路径信息(如文件名、目录名、文件扩展名等)
检查路径的存在性
创建和删除路径
遍历目录
from pathlib import Path p = Path('.') for entry in p.iterdir(): print(entry.name) -
文件操作
读取和写入文件
复制和移动文件
from pathlib import Path p = Path('example.txt') with p.open('r') as file: content = file.read()
8.5.4 time模块
Python 提供了一个 time 模块可以用于格式化日期和时间
time.time( )
返回当前时间的时间戳(1970年后经过的浮点秒数)
time.sleep(secs)
推迟调用线程的运行,secs指秒数
8.5.5 logging模块
logging模块简介
logging 模块是 Python 的标准库模块,用于生成日志。它可以记录应用程序或模块的运行状态、错误信息等,帮助开发者了解程序的运行情况,进行故障排查和性能分析。
搭建日志系统
-
配置日志级别:如 DEBUG、INFO、WARNING、ERROR、CRITICAL 等。
-
选择日志处理器:如将日志输出到控制台、文件、网络等。
-
设置日志格式:定义日志的输出格式,包括时间戳、日志级别、消息内容等。
示例代码
import logging
# 配置日志
logging.basicConfig(filename='app.log', level=logging.INFO,
format='%(asctime)s %(levelname)s %(message)s')
# 写入日志
logging.debug('这是一条 debug 级别的日志')
logging.info('这是一条 info 级别的日志')
logging.warning('这是一条 warning 级别的日志')
logging.error('这是一条 error 级别的日志')
logging.critical('这是一条 critical 级别的日志')
8.5.6 SMTP模块
SMTP(Simple Mail Transfer Protocol)模块用于发送电子邮件;Python 的 smtplib 模块提供了 SMTP 协议的客户端实现,而 email 模块则用于构建电子邮件消息;
发送邮件示例
-
设置 SMTP 服务器和端口:如 Gmail、QQ 邮箱等提供的 SMTP 服务器;
-
创建邮件对象:使用
email模块构建邮件内容; -
发送邮件:使用
smtplib模块连接到 SMTP 服务器,并发送邮件;
示例代码
import smtplib from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText # 邮箱服务器和端口 smtp_server = 'smtp.example.com' smtp_port = 587 # 发送者和接收者邮箱 sender = '[email protected]' receiver = '[email protected]'
其他的可参考文档: Python 日期和时间 | 菜鸟教程
9. 装饰器
就是给已有函数增加额外功能的函数。
装饰器的功能特点:
-
不修改已有函数的源代码
-
不修改已有函数的调用方式
-
给已有函数增加额外的功能
主要用于: 对原有函数进行增强
9.1. 装饰器的示例代码
# 添加一个登录验证的功能
def check(fn):
def inner():
print("请先登录....")
fn()
return inner
def comment():
print("发表评论")
# 使用装饰器来装饰函数
comment = check(comment)
comment()
# 装饰器的基本雏形
# def decorator(fn): # fn:目标函数.
# def inner():
# '''执行函数之前'''
# fn() # 执行被装饰的函数
# '''执行函数之后'''
# return inner
代码说明:
-
有且只有一个参数,必须是函数类型,这样定义的函数才是装饰器。
-
写代码要遵循开放封闭原则,它规定已经实现的功能代码不允许被修改,但可以被扩展。
执行结果:
请先登录.... 发表评论
9.2. 装饰器的语法糖写法
如果有多个函数都需要添加登录验证的功能,每次都需要编写func = check(func)这样代码对已有函数进行装饰,这种做法还是比较麻烦。
Python给提供了一个装饰函数更加简单的写法,那就是语法糖,语法糖的书写格式是: @装饰器名字,通过语法糖的方式也可以完成对已有函数的装饰
# 添加一个登录验证的功能
def check(fn):
print("装饰器函数执行了")
def inner():
print("请先登录....")
fn()
return inner
# 使用语法糖方式来装饰函数
@check
def comment():
print("发表评论")
comment()
说明:
-
@check 等价于 comment = check(comment)
-
装饰器的执行时间是加载模块时立即执行。
执行结果:
请先登录.... 发表评论
9.3. 带有参数的装饰器介绍
带有参数的装饰器就是使用装饰器装饰函数的时候可以传入指定参数,语法格式: @装饰器(参数,...)
错误写法:
def decorator(fn, flag):
def inner(num1, num2):
if flag == "+":
print("--正在努力加法计算--")
elif flag == "-":
print("--正在努力减法计算--")
result = fn(num1, num2)
return result
return inner
@decorator('+')
def add(a, b):
result = a + b
return result
result = add(1, 3)
print(result)
执行结果:
Traceback (most recent call last):
File "/home/python/Desktop/test/hho.py", line 12, in <module>
@decorator('+')
TypeError: decorator() missing 1 required positional argument: 'flag'
代码说明:
-
装饰器只能接收一个参数,并且还是函数类型。
正确写法:
在装饰器外面再包裹上一个函数,让最外面的函数接收参数,返回的是装饰器,因为@符号后面必须是装饰器实例。
# 添加输出日志的功能
def logging(flag):
def decorator(fn):
def inner(num1, num2):
if flag == "+":
print("--正在努力加法计算--")
elif flag == "-":
print("--正在努力减法计算--")
result = fn(num1, num2)
return result
return inner
# 返回装饰器
return decorator
# 使用装饰器装饰函数
@logging("+")
def add(a, b):
result = a + b
return result
@logging("-")
def sub(a, b):
result = a - b
return result
result = add(1, 2)
print(result)
result = sub(1, 2)
print(result)
10. 扩展说明: python的编码规范:PEP8
PEP8 提供了 Python 代码的编写约定. 本节知识点旨在提高代码的可读性, 并使其在各种 Python 代码中编写风格保持一致.
-
缩进使用4个空格, 空格是首选的缩进方式. Python3 不允许混合使用制表符和空格来缩进.
-
每一行最大长度限制在79个字符以内.
-
顶层函数、类的定义, 前后使用两个空行隔开.
-
import 导入
4.1 导入建议在不同的行, 例如:
import os import sys # 不建议如下导包 import os, sys # 但是可以如下: from subprocess import Popen, PIPE
4.2 导包位于文件顶部, 在模块注释、文档字符串之后, 全局变量、常量之前. 导入按照以下顺序分组:
4.2.1 标准库导入
4.2.2 相关第三方导入
4.2.3 本地应用/库导入
4.2.4 在每一组导入之间加入空行
-
Python 中定义字符串使用双引号、单引号是相同的, 尽量保持使用同一方式定义字符串. 当一个字符串包含单引号或者双引号时, 在最外层使用不同的符号来避免使用反斜杠转义, 从而提高可读性.
-
表达式和语句中的空格:
6.1 避免在小括号、方括号、花括号前跟空格.
6.2 避免在逗号、分好、冒号之前添加空格.
6.3 冒号在切片中就像二元运算符, 两边要有相同数量的空格. 如果某个切片参数省略, 空格也省略.
6.4 避免为了和另外一个赋值语句对齐, 在赋值运算符附加多个空格.
6.5 避免在表达式尾部添加空格, 因为尾部空格通常看不见, 会产生混乱.
6.6 总是在二元运算符两边加一个空格, 赋值(=),增量赋值(+=,-=),比较(==,<,>,!=,<>,<=,>=,in,not in,is,is not),布尔(and, or, not)
-
避免将小的代码块和 if/for/while 放在同一行, 要避免代码行太长.
if foo == 'blah': do_blah_thing() for x in lst: total += x while t < 10: t = delay()
-
永远不要使用字母 'l'(小写的L), 'O'(大写的O), 或者 'I'(大写的I) 作为单字符变量名. 在有些字体里, 这些字符无法和数字0和1区分, 如果想用 'l', 用 'L' 代替.
-
类名一般使用首字母大写的约定.
-
函数名应该小写, 如果想提高可读性可以用下划线分隔.
-
如果函数的参数名和已有的关键词冲突, 在最后加单一下划线比缩写或随意拼写更好. 因此 class_ 比 clss 更好.(也许最好用同义词来避免这种冲突).
-
方法名和实例变量使用下划线分割的小写单词, 以提高可读性.
#
11. 面向对象
-
Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的。本章节我们将详细介绍Python的面向对象编程。
如果你以前没有接触过面向对象的编程语言,那你可能需要先了解一些面向对象语言的一些基本特征,在头脑里头形成一个基本的面向对象的概念,这样有助于你更容易的学习Python的面向对象编程。
接下来我们先来简单的了解下面向对象的一些基本特征。
面向对象技术简介
-
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
-
方法:类中定义的函数。
-
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
-
数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
-
方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
-
局部变量:定义在方法中的变量,只作用于当前实例的类。
-
实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
-
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类
-
实例化:创建一个类的实例,类的具体对象。
-
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
和其它编程语言相比,Python 在尽可能不增加新的语法和语义的情况下加入了类机制。
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
对象可以包含任意数量和类型的数据。
类定义
语法格式如下:
class ClassName: <statement-1> <statement-N>
类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性。
类对象
类对象支持两种操作:属性引用和实例化。
属性引用使用和 Python 中所有的属性引用一样的标准语法:obj.name。
类对象创建后,类命名空间中所有的命名都是有效属性名。所以如果类定义是这样:
class MyClass: """一个简单的类实例""" i = 12345 def f(self): return 'hello world' # 实例化类 x = MyClass() # 访问类的属性和方法 print("MyClass 类的属性 i 为:", x.i) print("MyClass 类的方法 f 输出为:", x.f())以上创建了一个新的类实例并将该对象赋给局部变量 x,x 为空的对象。
-
执行以上程序输出结果为:
MyClass 类的属性 i 为: 12345 MyClass 类的方法 f 输出为: hello world
类有一个名为 init() 的特殊方法(构造方法),该方法在类实例化时会自动调用,像下面这样:
def __init__(self): self.data = []
类定义了 init() 方法,类的实例化操作会自动调用 init() 方法。如下实例化类 MyClass,对应的 init() 方法就会被调用:
x = MyClass()
当然, init() 方法可以有参数,参数通过 init() 传递到类的实例化操作上。例如:
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i)
# 输出结果:3.0 -4.5
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x100771878> __main__.Test
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
self 不是 python 关键字,我们把他换成 zhongsichunagxin 也是可以正常执行的:
class Test: def prt(zhongsichunagxin): print(zhongsichunagxin) print(zhongsichunagxin.__class__) t = Test() t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x100771878> __main__.Test
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例。
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 实例化类
p = people('zhongsichunagxin ',10,30) p.speak()
执行以上程序输出结果为:
zhongsichunagxin 说: 我 10 岁。
继承
Python 同样支持类的继承,如果一种语言不支持继承,类就没有什么意义。派生类的定义如下所示:
class DerivedClassName(BaseClassName): <statement-1> . . . <statement-N>
子类(派生类 DerivedClassName)会继承父类(基类 BaseClassName)的属性和方法。
BaseClassName(实例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
class DerivedClassName(modname.BaseClassName):
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()
执行以上程序输出结果为:
ken 说: 我 10 岁了,我在读 3 年级
多继承
Python同样有限的支持多继承形式。多继承的类定义形如下例:
class DerivedClassName(Base1, Base2, Base3):
<statement-1> . . . <statement-N>
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
#另一个类,多继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))
#多继承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("Tim",25,80,4,"Python") test.speak()
#方法名同,默认调用的是在括号中参数位置排前父类的方法
执行以上程序输出结果为:
我叫 Tim,我是一个演说家,我演讲的主题是 Python
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法,实例如下:
#!/usr/bin/python3
class Parent:
# 定义父类
def myMethod(self):
print ('调用父类方法')
class Child(Parent):
# 定义子类
def myMethod(self):
print ('调用子类方法')
c = Child()
# 子类实例
c.myMethod()
# 子类调用重写方法
super(Child,c).myMethod()
#用子类对象调用父类已被覆盖的方法
super() 函数是用于调用父类(超类)的一个方法。
执行以上程序输出结果为:
调用子类方法 调用父类方法
更多文档:
类属性与方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。
self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定使用 self。
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
类的私有属性实例如下:
class JustCounter:
__secretCount = 0 # 私有变量
publicCount = 0 # 公开变量
def count(self):
self.__secretCount += 1
self.publicCount += 1
print (self.__secretCount)
counter = JustCounter()
counter.count()
counter.count()
print (counter.publicCount)
print (counter.__secretCount)
# 报错,实例不能访问私有变量
执行以上程序输出结果为:
1
2
2
Traceback (most recent call last):
File "test.py", line 16, in <module>
print (counter.__secretCount) # 报错,实例不能访问私有变量
AttributeError: 'JustCounter' object has no attribute '__secretCount'
类的私有方法实例如下:
class Site:
def __init__(self, name, url):
self.name = name # public
self.__url = url # private
def who(self):
print('name : ', self.name)
print('url : ', self.__url)
def __foo(self):
# 私有方法
print('这是私有方法')
def foo(self):
# 公共方法
print('这是公共方法')
self.__foo()
x = Site('xxxx', 'www.zhongsichuangxin.com')
x.who() # 正常输出
x.foo() # 正常输出
x.__foo() # 报错
以上实例执行结果:

类的专有方法:
-
init : 构造函数,在生成对象时调用
-
del : 析构函数,释放对象时使用
-
repr : 打印,转换
-
setitem : 按照索引赋值
-
getitem: 按照索引获取值
-
-
len: 获得长度
-
cmp: 比较运算
-
-
call: 函数调用
-
add: 加运算
-
-
sub: 减运算
-
mul: 乘运算
-
truediv: 除运算
-
mod: 求余运算
-
pow: 乘方
运算符重载
Python同样支持运算符重载,我们可以对类的专有方法进行重载,实例如下:
class Vector: def __init__(self, a, b): self.a = a self.b = b def __str__(self): return 'Vector (%d, %d)' % (self.a, self.b) def __add__(self,other): return Vector(self.a + other.a, self.b + other.b) v1 = Vector(2,10) v2 = Vector(5,-2) print (v1 + v2)以上代码执行结果如下所示:
Vector(7,8)
-
12. 反射机制
Python的反射机制允许程序在运行时检查、修改或删除对象的属性和方法。这种机制是通过四个内置函数来实现的:getattr(), setattr(), hasattr(), 和 delattr()。
15.1、常用函数介绍
-
getattr(object, name[, default])
-
功能:返回对象指定属性的值。如果属性不存在且提供了
default参数,则返回default。否则,抛出AttributeError异常。
-
-
setattr(object, name, value)
-
功能:设置对象指定属性的值。如果属性不存在,则创建该属性。
-
-
hasattr(object, name)
-
功能:检查对象是否具有指定的属性。如果存在则返回
True,否则返回False。
-
-
delattr(object, name)
-
功能:删除对象的指定属性。如果属性不存在,则抛出
AttributeError异常。
-
15.2、应用示例
1. getattr() 示例
class MyClass:
def __init__(self):
self.x = 10
obj = MyClass()
print(getattr(obj, 'x')) # 输出: 10
print(getattr(obj, 'y', 'default_value')) # 输出: 'default_value'
2. setattr() 示例
class MyClass:
pass
obj = MyClass()
setattr(obj, 'x', 10)
print(obj.x) # 输出: 10
3. hasattr() 示例
class MyClass:
def __init__(self):
self.x = 10
obj = MyClass()
print(hasattr(obj, 'x')) # 输出: True
print(hasattr(obj, 'y')) # 输出: False
4. delattr() 示例
class MyClass:
def __init__(self):
self.x = 10
obj = MyClass()
delattr(obj, 'x')
print(hasattr(obj, 'x')) # 输出: False
5. 反射机制在模拟Web框架中的应用
class Controller:
def handle_request(self, request_type):
method = getattr(self, f'handle_{request_type}', None)
if method is not None:
method()
else:
print(f"Unsupported request type: {request_type}")
def handle_get(self):
print("Handling GET request")
def handle_post(self):
print("Handling POST request")
controller = Controller()
controller.handle_request('get') # 输出: Handling GET request
controller.handle_request('post') # 输出: Handling POST request
controller.handle_request('delete') # 输出: Unsupported request type: delete
15.3、测试框架中的应用
下面示例中,将创建一个简单的自动化测试框架,该框架能够动态地发现并执行测试用例。每个测试用例都将是一个类的方法,并且这些方法将遵循一定的命名约定(例如,以test_开头)。测试框架将使用反射机制来查找这些测试用例,并自动执行它们
自动化测试框架代码
import inspect
class TestRunner:
def __init__(self, test_class):
self.test_class = test_class
def run_tests(self):
# 获取测试类中的所有方法
methods = inspect.getmembers(self.test_class, inspect.ismethod)
# 过滤出以'test_'开头的测试方法
test_methods = [method for name, method in methods if name.startswith('test_')]
# 执行每个测试方法
for name, method in test_methods:
print(f"Running test: {name}")
try:
# 创建测试类的实例(如果需要的话)
test_instance = self.test_class()
# 调用测试方法
method(test_instance)
print(f"Test {name} passed.")
except Exception as e:
print(f"Test {name} failed. Exception: {e}")
# 示例测试用例类
class MyTestCases:
def test_addition(self):
assert 1 + 1 == 2, "Addition test failed"
def test_subtraction(self):
assert 2 - 1 == 1, "Subtraction test failed"
# 使用测试框架运行测试用例
if __name__ == "__main__":
runner = TestRunner(MyTestCases)
runner.run_tests()
解释
-
TestRunner类封装了自动化测试框架的核心逻辑。它接受一个测试类作为参数,并使用反射机制来查找并执行该类中的测试方法。 -
run_tests方法首先使用inspect.getmembers函数获取测试类中的所有方法和属性。然后,它过滤出以test_开头的测试方法。 -
对于每个测试方法,
run_tests方法创建一个测试类的实例(如果需要的话),并使用method(test_instance)来调用测试方法。如果测试方法执行成功,则打印出通过信息;如果测试方法抛出异常,则打印出失败信息和异常详情。 -
MyTestCases类包含两个测试用例方法:test_addition和test_subtraction。这两个方法都是简单的断言语句,用于验证基本的数学运算。 -
在主程序中,我们创建一个
TestRunner对象,并将MyTestCases类作为参数传递给它。然后,我们调用run_tests方法来运行测试用例。
Python的反射机制为动态编程提供了强大的支持,使得程序能够在运行时灵活地操作对象的属性和方法。上述示例展示了反射机制的基本用法及其在模拟Web框架中的应用。
13. pymysql连接mysql数据库
pymysql连接mysql数据库,并进行读写操作
1. 安装pymysql库
首先,你需要确保已经安装了pymysql库。如果还没有安装,可以通过pip来安装:
pip install pymysql
2. 连接MySQL数据库
在Python脚本中,使用pymysql库连接到MySQL数据库。
import pymysql
# 数据库连接参数
host = 'localhost' # 数据库主机名,如果是本地数据库,通常为'localhost'
user = 'your_username' # 数据库用户名
password = 'your_password' # 数据库密码
database = 'your_database' # 要连接的数据库名
# 创建数据库连接
connection = pymysql.connect(
host=host,
user=user,
password=password,
database=database
)
try:
with connection.cursor() as cursor: # 创建一个游标对象,用于执行SQL语句
# 在这里可以执行SQL查询、插入、更新等操作
pass
finally:
connection.close() # 关闭数据库连接
3. 读取数据
接下来,我们将演示如何使用游标对象来执行SQL查询并读取数据
import pymysql
# ... 省略连接数据库的代码 ...
try:
with connection.cursor() as cursor:
# 执行SQL查询
sql = "SELECT * FROM your_table" # 替换为你的表名
cursor.execute(sql)
# 获取查询结果
results = cursor.fetchall()
# 输出查询结果
for row in results:
print(row) # 输出每一行的数据,row是一个元组,包含每列的值
finally:
connection.close()
4. 写入数据
现在,我们将演示如何使用游标对象来执行SQL插入操作。
import pymysql
# ... 省略连接数据库的代码 ...
try:
with connection.cursor() as cursor:
# 插入数据的SQL语句
sql = "INSERT INTO your_table (column1, column2) VALUES (%s, %s)" # 替换为你的表名和列名
values = ('value1', 'value2') # 要插入的数据,注意使用%s作为占位符
# 执行SQL插入操作
cursor.execute(sql, values)
# 提交事务(对于插入、更新、删除等操作,需要提交事务才能生效)
connection.commit()
finally:
connection.close()
注意:在执行插入、更新、删除等操作时,需要调用connection.commit()来提交事务,否则这些操作不会生效。
5. 完整示例
下面是一个完整的示例,包括连接数据库、读取数据和写入数据。
import pymysql
# 数据库连接参数
host = 'localhost'
user = 'your_username'
password = 'your_password'
database = 'your_database'
# 创建数据库连接
connection = pymysql.connect(
host=host,
user=user,
password=password,
database=database
)
try:
# 读取数据
with connection.cursor() as cursor:
sql = "SELECT * FROM your_table"
cursor.execute(sql)
results = cursor.fetchall()
for row in results:
print(row)
# 写入数据
with connection.cursor() as cursor:
sql = "INSERT INTO your_table (column1, column2) VALUES (%s, %s)"
values = ('value1', 'value2')
cursor.execute(sql, values)
connection.commit()
finally:
connection.close()
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/zhaoYuanJun_nb/article/details/161802618

