
【数据结构讲解】【树】——树的简单概念入门和二叉树
0.引入:什么是树?
读者见过大树吗?一般来说,树有一个粗壮的树干,在网上面熟感就会分成两岔或者多岔,接着树枝会一直继续分下去,一直分到末端的叶子位置。
事实上,C++中也有与树相类似的数据结构,只不过是倒过来的。这个“粗壮的树干”(也就是“根”)在上面,茂盛的树叶在下面。如果你想表示“数据之间的指向关系”或者“数据之间的层次关系”,可以考虑使用“树”这一数据结构。
本文将介绍一些关于树的基本概念,并且详细介绍一种特殊的树——二叉树。
1.树的相关基本概念
接下来以“族谱树”为例子介绍树中的相关概念。(图中的“曾祖父”应为“祖父”,这里不小心打错了)

观察上面这棵标准的“族谱树”,可以发现“祖父”处在这颗树的最顶端,我们把这样的结点叫做根结点。
当然,有的时候一棵树可以没有根(或者说,没有指定的根),我们就叫它
无根树。如果有根或者我们人为地指定了一个根节点(比如结点1),那么我们就叫这样的树有根树
然后再来观察一下结点之间的层次关系。“爷爷”是“爸爸的爸爸”,我们就将“爷爷”称做“爸爸”的父亲结点,称“爸爸”为“爷爷”的子节点。同样的,“姑姑”也是“爷爷”的父结点。“爷爷”同样也是“祖父”的子节点。
再来看看,“爸爸”是“叔叔”的兄弟,我们可以将“爸爸”和“叔叔”称为一对兄弟结点。比如,“叔父”也是“爷爷”的“兄弟结点”,也可以说“爷爷”和“叔父”互为“兄弟结点”。但是请注意,只有“同一父结点”的多个结点才能叫做“兄弟结点”。比如,“我”和“堂弟”就不是兄弟结点。
然后再看,“爸爸”,“爷爷”,“叔父”都是我的“直系亲属”(祖先),就将上述结点称为“我”的祖先结点。而对于“爷爷”,“爸爸”,“姑姑”,“叔叔”,“我”,“堂弟”都是爷爷的“直系后代”(子孙),就把这些结点称为“爷爷”的子孙结点。
像“我”和“堂弟”这样没有孩子(也就是没有子结点)的结点为叶子结点。相应的,把“父亲”、“祖父”这样有子结点的结点叫做分支节点,也可以叫作内部结点。
可以发现,若将“爷爷”及其子孙结点全部提取出来,那么这也还是一棵树。(类似于全集与子集),我们将这棵以“爷爷”为根节点的树称为原树的子树。
到这里可以发现,树具有很明显的“递归性质”,因此尝试用
dfs算法来递归解决树中的一些问题。对于“树形dp”中的状态,也常定义为“dp[i]表示以i为根节点的子树…”。巧妙利用树中的递归性质,有的时候可以发挥意想不到的效果。
对于上面这棵树,从“我”到“祖父”需要经过
3
3
3个结点,(“祖父”、“爷爷”和“爸爸”),就称“我”这个结点在树中的深度为3。而称这棵树中深度最大结点的深度为树的高度。图示族谱树的高度即为“我”(或者“堂弟”)的深度3。
需要注意,一棵有 n n n个结点的树一定有 n − 1 n-1 n−1条边。反之若一张联通图有 n − 1 n-1 n−1条边,那么它一定是一棵树。这是算法竞赛中常用的策略,读者需注意。
最后,若干棵互不相交的数的集合就是森林,只有一棵树也可以称为森林。
注意:这些定义并不是严谨的定义,但是这篇文章的目的是帮助大家了解树的基础概念,以及深入探讨二叉树这一特殊的树。至于树的相关概念的严格定义,会在后续的文章中提到(要先完成“图”相关概念的学习,读者可自行调整文章观看顺序)。请读者不用担心,现阶段理解即可。
2.二叉树的概念,表示和存储
接下来介绍一种特殊的树:二叉树。
对于一棵“每个结点最多只有两个子结点”的树,我们就将它称为二叉树。(所以说,一切树的相关概念和性质都适用于二叉树)二叉树的递归定义如下:
(1)二叉树要么是一棵不包含任何结点的空树,要么有且只有一个结点称为根结点;
(2)根结点至多有两个互不相交的子树,并且每个子树也是一棵二叉树。
定义二叉树根节点的层是1,其余结点的层等于该结点的父结点的层数
+
1
+1
+1。
二叉树的性质如下:(CSP-J/S初赛常考)
- 非空二叉树第 i i i层上至多有 2 i − 1 2^{i-1} 2i−1个结点;
- 高为 h h h的二叉树至多有 2 h + 1 − 1 2^{h+1}-1 2h+1−1个结点;
- 对于任何非空二叉树,若其叶结点个数为 n 0 n_0 n0,有两个孩子的结点数为 n 2 n_2 n2,则有 n 0 = n 2 + 1 n_0=n_2+1 n0=n2+1。
那么如何使用代码来表示这一数据结构呢?考虑用数组+结构体来模拟。
使用“孩子表示法”表示一棵二叉树,可定义二叉树的数据结构中包含如下信息。
(1)数据域:存放结点本身的信息(如:权值,上文的“爸爸”,“我”等名称也是数据域应当存储的信息)
(2)孩子域:分别存放左右子结点的下标或者内存地址。
代码示例如下:
struct node{
int val;
int lchild, rchild; // 储存左右两个子结点的下标
} t[MAXN]; // MAXN为树的最大结点数
其中,t[i]表示树上编号为i的结点的信息。信息学竞赛中默认给每个结点编号处理。
3.特殊二叉树——完全二叉树及其存储方法
接下来介绍一种特殊的二叉树——完全二叉树,定义如下:
一棵二叉树只有最下面两层结点拥有的子结点数可以小于 2 2 2,且最下面一层的结点都处于该层左边的连续位置上,这样的树就是完全二叉树。
具有n个结点的完全二叉树的深度为
⌊
log
2
n
⌋
\lfloor \log_2 n\rfloor
⌊log2n⌋。若按层次从上到下,从左到右对其每一个结点从
1
1
1 开始依次编号,则编号为
x
x
x 的结点具有以下性质。
- 若 x = 1 x=1 x=1,则结点 x x x 为二叉树的根结点,没有父结点;若 x > 1 x>1 x>1,则该结点的父节点编号为 ⌊ x / 2 ⌋ \lfloor x/2\rfloor ⌊x/2⌋。
- 如果 2 x > n 2x>n 2x>n,则结点 x x x 无左子结点,否则 x x x 的左子结点编号为 2 x 2x 2x。
- 如果 2 x + 1 > n 2x+1>n 2x+1>n,则结点 x x x 无右子结点,否则 x x x 的右子结点编号为 2 x + 1 2x+1 2x+1。
对于一棵完全二叉树,除最下面一层没有子结点外,其余每一层上的所有结点有且都有两个子结点,这样的完全二叉树就是满二叉树,又称为完美二叉树。

图片来自网络
为什么要学习完全二叉树呢?因为竞赛中常见的涉及到二叉树的题目大多要使用完全二叉树(比如线段树)。还因为其高效的存储方法:直接使用数组表示一棵完全二叉树。其具体方法是按层次从上到下,从左到右对其每一个结点从
1
1
1 开始依次编号,并以编号作为数组的下标,依次存放在一维数组中。
一棵完全二叉树及其数组表示法如下:

| 下标 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 储存信息 | A | C | F | Z | Y |
在数组表示法,根据节点存储在数组总的下标数值,可以获得结点在完全二叉树上的父子逻辑关系:
- 非根结点 x x x ( x > 1 x>1 x>1)的父结点的编号为 ⌊ x / 2 ⌋ \lfloor x/2\rfloor ⌊x/2⌋。
- 结点 x x x 的左子结点编号为 2 x ( 2 x ≤ n ) 2x(2x\le n) 2x(2x≤n),右子结点编号为 2 x + 1 ( 2 x + 1 ≤ n ) 2x+1(2x+1\le n) 2x+1(2x+1≤n)。
4.二叉树的遍历和代码实现
二叉树的遍历指的是将一颗二叉树从根节点开始,按照指定顺序,不重复、不遗漏地访问每一个结点。在完成一些任务中,必须要访问所有节点的信息,这个时候就需要遍历这棵二叉树了。
二叉树的遍历分为四种
(1)层次遍历:对二叉树进行
广度优先搜索,将根结点放入初始队列中,取出每次出队的结点,即可得到层次遍历。
(2)前序遍历:首先访问根结点,然后遍历左子树,最后遍历右子树。(根->左->右)
(3)中序遍历:首先遍历左子树,然后访问根结点,最后遍历右子树。(左->根->右)
(4)后序遍历:首先遍历左子树,然后遍历右子树,最后访问根结点。(左->右->根)
本质上来说,(1)是对二叉树进行广度优先遍历,(2)(3)(4)则是按照遍历顺序的不同进行深度优先遍历。也就对应了两种搜索方式:DFS和BFS。下面两图出自《深入浅出 基础篇》,分别展示层次遍历的顺序和深度优先遍历的顺序。
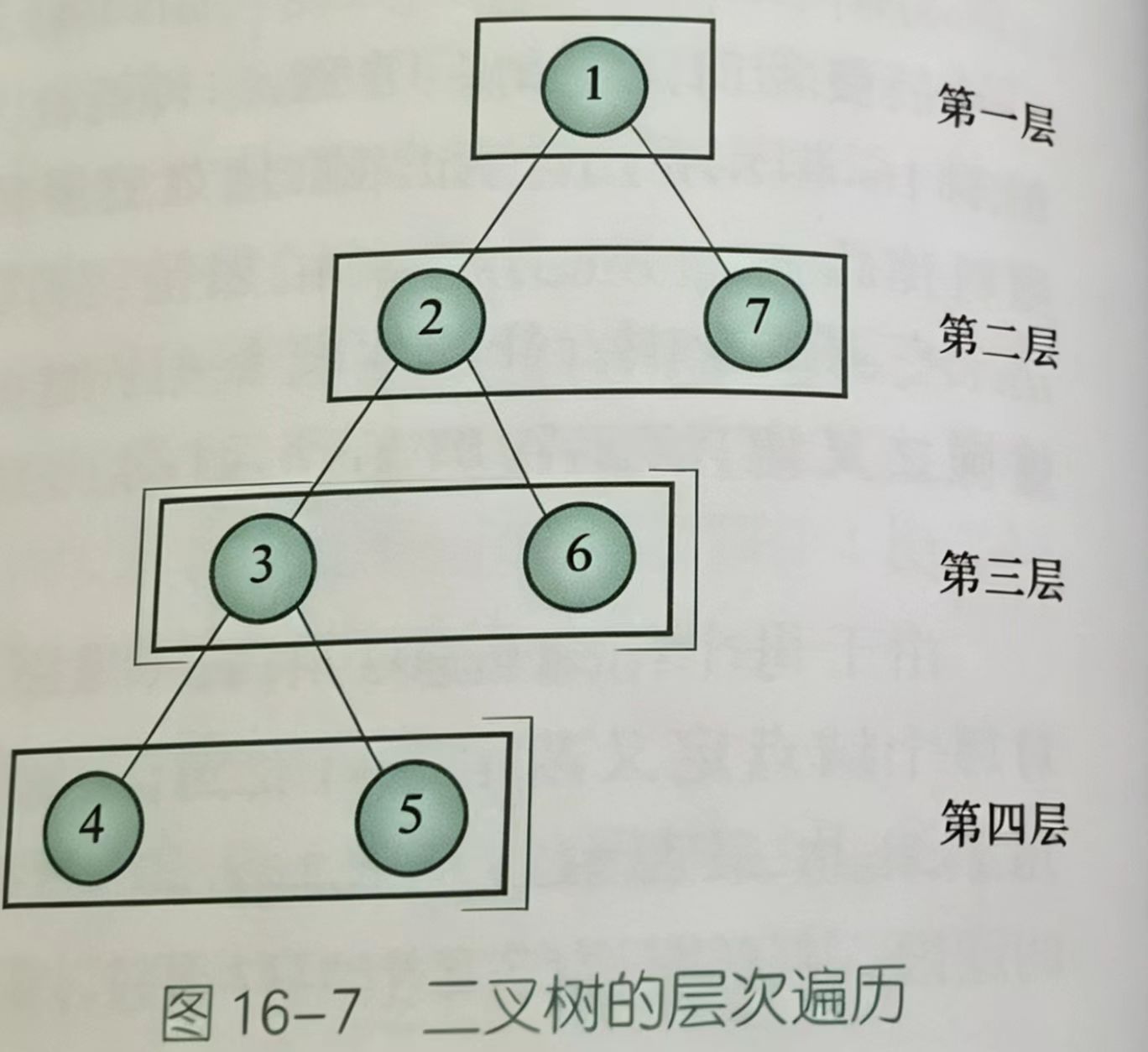
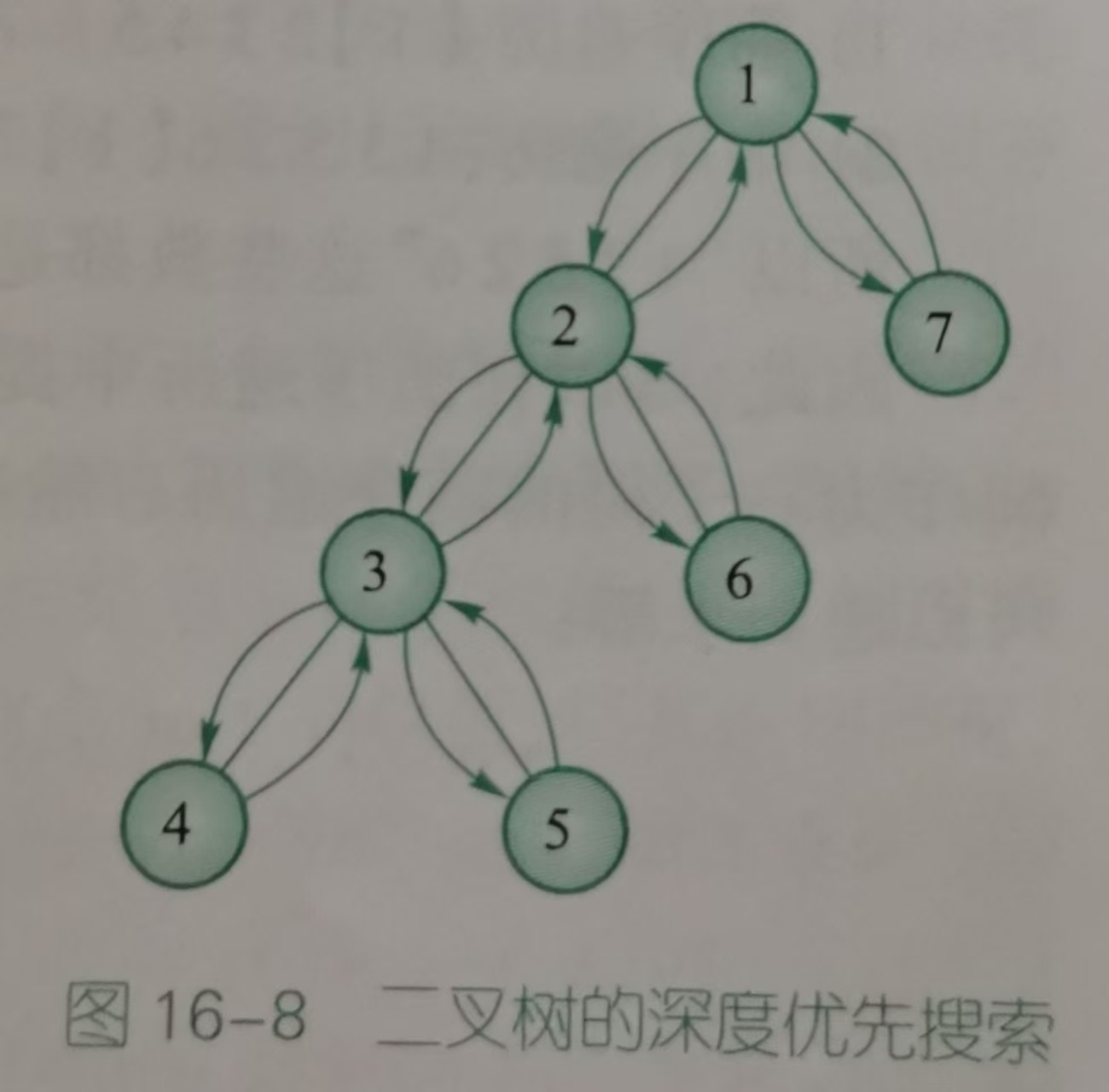
4.1.普通二叉树的遍历
接下来介绍二叉树遍历的代码实现。
首先介绍如何“建树”。
第一行是一个整数,表示无根二叉树的结点个数 n n n。
接下来 n − 1 n−1 n−1 行,每行两个整数 u u u, v v v,表示树上存在一条连接 u u u, v v v 的边。其中 u u u为父结点, v v v为子结点。
这是最常见的输入格式。对于每一组u,v,我们先检查u是否已经有左儿子了。若有,则将右儿子更新为v,反之就将左儿子更新为v。然后更新v的父亲为u即可。
struct node{
int val;
int lchild, rchild; // 储存左右两个子结点的下标
} t[MAXN]; // MAXN为树的最大结点数
cin >> n;
for (int i = 1; i < n; i++){
int u, v;
cin >> u >> v;
t[u].left ? t[u].right = v : t[u].left = v; // 有了左节点就存储右节点
t[v].father = u;
}
首先是层次遍历。使用一个函数进行代码编写。(注意vl==0或vr==0表示此结点没有左/右孩子)。
void bfs(int root){ // root表示这棵树的根节点
queue<int> q;
q.push(root);
while (!q.empty()){
int u = q.front(); q.pop();
int vl = t[u].lchild,vr = t[u].rchild;
if(vl){ // u有左孩子
// 对vl做一些操作,比如cout << vl << endl;
q.push(vl);
}
if(vr){ // u有右孩子
// 对vr做一些操作,比如cout << vr << endl;
q.push(vr);
}
}
}
然后是深度优先遍历。
void pre_order(int u){ // 表示以u为根节点的树进行前序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
if(t[u].lchild) pre_order(t[u].lchild); // 左子树前序遍历
if(t[u].rchild) pre_order(t[u].rchild); // 右子树前序遍历
}
void in_order(int u){ // 表示以u为根节点的树进行中序遍历
if(t[u].lchild) in_order(t[u].lchild); // 左子树中序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
if(t[u].rchild) in_order(t[u].rchild); // 右子树中序遍历
}
void post_order(int u){ // 表示以u为根节点的树进行后序遍历
if(t[u].lchild) post_order(t[u].lchild); // 左子树后序遍历
if(t[u].rchild) post_order(t[u].rchild); // 右子树后序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
}
完整代码如下:
#include<bits/stdc++.h>
using namespace std;
#define MAXN 100010
int n;
struct node{
int val; // 储存当前结点的信息
int lchild, rchild; // 储存左右两个子结点的下标
} t[MAXN]; // MAXN为树的最大结点数
void bfs(int root){ // root表示这棵树的根节点
queue<int> q;
q.push(root);
while (!q.empty()){
int u = q.front(); q.pop();
int vl = t[u].lchild,vr = t[u].rchild;
if(vl){ // u有左孩子
// 对vl做一些操作,比如cout << vl << endl;
q.push(vl);
}
if(vr){ // u有右孩子
// 对vr做一些操作,比如cout << vr << endl;
q.push(vr);
}
}
}
void pre_order(int u){ // 表示以u为根节点的树进行前序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
if(t[u].lchild) pre_order(t[u].lchild); // 左子树前序遍历
if(t[u].rchild) pre_order(t[u].rchild); // 右子树前序遍历
}
void in_order(int u){ // 表示以u为根节点的树进行中序遍历
if(t[u].lchild) in_order(t[u].lchild); // 左子树中序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
if(t[u].rchild) in_order(t[u].rchild); // 右子树中序遍历
}
void post_order(int u){ // 表示以u为根节点的树进行后序遍历
if(t[u].lchild) post_order(t[u].lchild); // 左子树后序遍历
if(t[u].rchild) post_order(t[u].rchild); // 右子树后序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
}
int main(){
cin >> n;
for (int i = 1; i < n; i++){
int u, v;
cin >> u >> v;
// 有了左节点就存储右节点
t[u].lchild ? t[u].rchild = v : t[u].lchild = v;
// t[v].father = u;若想储存父结点信息,使用此代码
}
int root = 1; // 因为是无根树,指定1为根节点方便处理
bfs(root);
pre_order(root);
in_order(root);
post_order(root);
return 0;
}
4.2.完全二叉树的遍历
因为完全二叉树的性质,我们可以使用u<<1(等价于u*2)表示结点u的左儿子编号,用(u<<1)|1(等价于u*2+1)表示结点u的右儿子编号。
不需要建树,我们只需要知道树的结点数 n n n即可。
首先是层次遍历。同样使用一个函数进行代码编写。(注意vl>n或vr>n表示此结点没有左/右孩子)。
void bfs(int root){ // root表示这棵树的根节点
queue<int> q;
q.push(root);
while (!q.empty()){
int u = q.front(); q.pop();
int vl = u << 1,vr = (u << 1) | 1;
if(vl <= n){ // u有左孩子
// 对vl做一些操作,比如cout << vl << endl;
q.push(vl);
}
if(vr <= n){ // u有右孩子
// 对vr做一些操作,比如cout << vr << endl;
q.push(vr);
}
}
}
然后是深度优先遍历。
void pre_order(int u){ // 表示以u为根节点的树进行前序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
if((u << 1) <= n) pre_order(u << 1); // 左子树前序遍历
if(((u << 1) | 1) <= n) pre_order((u << 1) | 1); // 右子树前序遍历
}
void in_order(int u){ // 表示以u为根节点的树进行中序遍历
if((u << 1) <= n) in_order(u << 1); // 左子树中序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
if(((u << 1) | 1) <= n) in_order((u << 1) | 1); // 右子树中序遍历
}
void post_order(int u){ // 表示以u为根节点的树进行后序遍历
if((u << 1) <= n) post_order(u << 1); // 左子树后序遍历
if(((u << 1) | 1) <= n) post_order((u << 1) | 1); // 右子树后序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
}
最后完整代码奉上:
#include<bits/stdc++.h>
using namespace std;
#define MAXN 100010
// t[i]相当于普通二叉树的t[i].val
int n, t[MAXN]; // MAXN为树的最大结点数
void bfs(int root){ // root表示这棵树的根节点
queue<int> q;
q.push(root);
while (!q.empty()){
int u = q.front(); q.pop();
int vl = u << 1,vr = (u << 1) | 1;
if(vl <= n){ // u有左孩子
// 对vl做一些操作,比如cout << vl << endl;
q.push(vl);
}
if(vr <= n){ // u有右孩子
// 对vr做一些操作,比如cout << vr << endl;
q.push(vr);
}
}
}
void pre_order(int u){ // 表示以u为根节点的树进行前序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
if((u << 1) <= n) pre_order(u << 1); // 左子树前序遍历
if(((u << 1) | 1) <= n) pre_order((u << 1) | 1); // 右子树前序遍历
}
void in_order(int u){ // 表示以u为根节点的树进行中序遍历
if((u << 1) <= n) in_order(u << 1); // 左子树中序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
if(((u << 1) | 1) <= n) in_order((u << 1) | 1); // 右子树中序遍历
}
void post_order(int u){ // 表示以u为根节点的树进行后序遍历
if((u << 1) <= n) post_order(u << 1); // 左子树后序遍历
if(((u << 1) | 1) <= n) post_order((u << 1) | 1); // 右子树后序遍历
// 对根节点u进行一些操作,比如cout << u << endl;
}
int main(){
cin >> n;
for (int i = 1; i <= n; i++)
cin >> t[i]; // 输入每个结点的信息
int root = 1; // 根节点为1
bfs(root);
pre_order(root);
in_order(root);
post_order(root);
return 0;
}
4.3.二叉树遍历的应用
选择遍历方式的经验法则:
| 问题类型 | 推荐遍历 | 原因 |
|---|---|---|
| 自顶向下处理(先处理父节点) | 前序遍历 | 先访问根,符合逻辑 |
| 有序序列相关问题 | 中序遍历 | BST 中序遍历得到有序序列 |
| 自底向上处理(先处理子树) | 后序遍历 | 先处理子树再处理根 |
| 层级相关问题 | 层次遍历 | 天然按层处理 |
在算法竞赛中,使用最多的是后序遍历(树论,dp中先把所有子树信息处理完毕,然后整合上传)。
此外,读者也应该掌握CSP-J/S初赛中“通过两个遍历序列得出一定信息”的问题,读者应当掌握。因为本专栏着重讲解复赛解题技巧,故此处不予讲解。读者可上网自行找题练习。
5.题目推荐
在CSP-J/S中,二叉树是第一轮的常客。在第二轮有时也会有所涉及,读者更多的还是应该学习处理有关二叉树问题的思想,一次准备后续对树更深入的学习。
此外,二叉树很有可能作为题目的“特殊性质”出现,读者需要学会识别,在必要时刻拿到相应部分分。
题目推荐分为两部分,二叉树基本运用和遍历是帮助读者了解和巩固二叉树基础的。二叉树综合运用则是选择比赛真题或模拟题,带你体验二叉树在比赛中的考法。
- 二叉树基本运用和遍历
·洛谷
P4715淘汰赛————通往洛谷的传送门
·洛谷P1305新二叉树————通往洛谷的传送门
·洛谷P1030求先序排列————通往洛谷的传送门
·洛谷P1229遍历问题————通往洛谷的传送门
·洛谷P1827美国血统————通往洛谷的传送门
- 二叉树综合运用
·洛谷P1364 医院设置————通往洛谷的传送门
·洛谷P4913二叉树深度————通往洛谷的传送门
·洛谷P3884二叉树问题————通往洛谷的传送门
·洛谷P1087FBI树————通往洛谷的传送门
·洛谷P1185绘制二叉树————通往洛谷的传送门
最后,制作不易,希望大家多多点赞收藏,关注下微信公众号,谢谢大家的关注,您的支持就是我更新的最大动力!
公众号上会及时提供信息学奥赛的相关资讯、各地科技特长生升学动态、还会提供相关比赛的备赛资料、信息学学习攻略等。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/Pantheraonca/article/details/162087288

