



在上一篇中,我们已经对 MySQL 事务的基本概念、ACID 特性以及事务的基本使用方式做了梳理.事务看起来只是简单的"开启、提交、回滚",但在真实业务中,它往往和并发访问、数据一致性、锁机制、隔离级别等问题紧密绑定.比如:两个事务同时修改同一条数据会发生什么?为什么会出现脏读、不可重复读、幻读?MySQL 是如何通过锁和 MVCC 来保证数据安全的?不同隔离级别之间到底有什么区别,又该如何在实际开发中选择?这篇文章将继续深入 MySQL 事务的核心内容,重点围绕 事务并发问题、隔离级别、锁机制以及 MVCC 多版本并发控制 展开,帮助我们从"会用事务"进一步理解到"知道事务为什么这样工作".掌握这些内容后,在处理订单、库存、支付、账户余额等对数据一致性要求较高的业务场景时,就能更加清楚地判断事务该怎么设计、问题该从哪里排查.

1.数据库并发的场景有三种
读–读 :不存在任何问题,也不需要并发控制.
读–写 :有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读,幻读,不可重复读.
写–写 :有线程安全问题,可能会存在更新丢失问题,比如第一类更新丢失,第二类更新丢失(后面补充)
2.读–写并发
读–写并发指的是:一个事务在读数据的同时,另一个事务在修改同一份数据.
核心问题是:读到的数据是不是可靠的?写入会不会影响正在读的结果?
典型场景
场景 1:读库存时,别人正在扣库存
用户 A 查询商品库存:
SELECT stock FROM product WHERE id = 1;
同时用户 B 下单扣库存:
UPDATE product
SET stock = stock - 1
WHERE id = 1;
可能出现的问题:
| 问题 | 说明 |
|---|---|
| 脏读 | A 读到了 B 还没提交的库存 |
| 不可重复读 | A 同一个事务里两次读库存,结果不一样 |
| 数据过期 | A 刚读到还有库存,但提交订单时库存已被扣完 |
常见并发问题
1.脏读
事务 B 修改了库存,但还没提交:
B:stock 从 10 改成 9,但未提交
A:读到 stock = 9
B:回滚
结果:A 读到的是不存在的脏数据.
一般通过隔离级别避免:
READ COMMITTED 及以上可以避免脏读
2.不可重复读
A:第一次读 stock = 10
B:提交更新 stock = 9
A:第二次读 stock = 9
同一个事务里,两次读取同一行数据结果不同.
一般通过:
REPEATABLE READ
避免.
3.幻读
A 查询库存大于 0 的商品:
SELECT * FROM product WHERE stock > 0;
同时 B 插入了一个新商品,库存也大于 0.
A 再查一次,发现多了一条数据.
这就是幻读.
常见解决方式
1.普通读:用 MVCC
大多数数据库会用 MVCC 处理读-写并发.
特点是:
读不阻塞写
写不阻塞读
也就是说,读操作通常读的是某个版本的数据,不会直接等写锁释放.
适合:
- 商品详情查询
- 订单列表查询
- 用户信息展示
- 大多数普通查询
2.强一致读:加锁读
如果读出来的数据马上要参与更新,就不能只做普通查询.
例如下单前先查库存:
SELECT stock FROM product WHERE id = 1;
然后再扣库存:
UPDATE product SET stock = stock - 1 WHERE id = 1;
这种写法有风险,因为查询和更新之间,库存可能已经被别人改了.
可以使用加锁读:
SELECT stock
FROM product
WHERE id = 1
FOR UPDATE;
它会对这行数据加锁,其他事务不能同时修改.
适合:
- 扣库存
- 扣余额
- 抢单
- 修改订单状态
- 需要“读完马上写”的业务
3.推荐写法:条件更新
很多读-写并发场景,不建议先读再写,而是直接条件更新.
比如扣库存:
UPDATE product
SET stock = stock - 1
WHERE id = 1 AND stock > 0;
然后判断影响行数:
影响行数 = 1:扣减成功
影响行数 = 0:库存不足
这是更推荐的方式,因为它把判断和修改合成了一个原子操作.
最佳实践
读-写并发可以按业务要求分两类:
| 业务要求 | 推荐方案 |
|---|---|
| 只展示数据 | 普通 SELECT,依赖 MVCC |
| 读完要修改 | SELECT ... FOR UPDATE 或条件更新 |
| 防止超卖/余额扣成负数 | 条件更新 + 事务 |
| 防止重复修改 | 乐观锁版本号 |
| 高并发热点数据 | Redis / MQ / 分片 |
结论
读-写并发最关键的判断是:读出来的数据会不会用于后续写操作.
如果只是展示:
SELECT * FROM product WHERE id = 1;
通常没问题.
如果读完马上要更新:
先查库存,再扣库存
先查余额,再扣余额
先查订单状态,再改状态
就要用:
条件更新、加锁读、事务、乐观锁
其中最推荐的是:
UPDATE product
SET stock = stock - 1
WHERE id = 1 AND stock > 0;
简单、原子、可靠.
多版本并发控制(MVCC)是一种用来解决读–写冲突的无锁并发控制
为事务分配单向增长的事务ID,为每个修改保存一个版本,版本与事务ID关联,读操作只读该事务开始前的数据库的快照。.所以 MVCC 可以为数据库解决以下问题
- 在并发读写数据库时,可以做到在读操作时不用阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能
- 同时还可以解决脏读,幻读,不可重复读等事务隔离问题,但不能解决更新丢失问题
理解 MVCC 需要知道三个前提知识:
- 3个记录隐藏字段
- undo 日志
- Read View
2.1三个记录隐藏列字段
In InnoDB 中,和 MVCC 相关的每条记录通常会涉及 3 个隐藏列字段:
| 隐藏字段 | 含义 | 作用 |
|---|---|---|
DB_TRX_ID | 最近一次修改该记录的事务 ID | 判断这条记录是由哪个事务ID修改的,记录创建这条记录/最后一次修改该记录的事务ID |
DB_ROLL_PTR | 回滚指针 | 指向 undo log,用来找到旧版本数据,指向这条记录的上一个版本简单理解成,指向历史版本就行,这些数据一般在 undo log 中 |
DB_ROW_ID | 隐藏行 ID | 当表没有主键或合适唯一索引时,InnoDB 自动生成行 ID,会自动以DB_ROW_ID 产生一个聚簇索引 |
1.DB_TRX_ID
表示最后一次插入或修改该行记录的事务 ID.
例如:
id = 1, name = 'Tom', DB_TRX_ID = 100
说明这条记录最后是由事务 100 修改的.
MVCC 判断记录是否可见时,会拿当前事务的 Read View 和 DB_TRX_ID 做比较.
2.DB_ROLL_PTR
表示回滚指针,指向 undo log 中的旧版本记录.
比如原来数据是:
name = 'Tom'
后来被事务修改成:
name = 'Jack'
当前记录里保存的是新值 Jack,而旧值 Tom 会在 undo log 里.
DB_ROLL_PTR 就是用来找到旧版本的.
可以理解为:
当前记录 -> undo log 旧版本 -> 更旧版本 -> ...
这条链就是 版本链.
3.DB_ROW_ID
这是 InnoDB 自动生成的隐藏行 ID.
但注意:不是所有表都会真正用到它.
InnoDB 聚簇索引选择规则是:
优先使用主键
没有主键,使用第一个非空唯一索引
都没有,才生成 DB_ROW_ID
所以如果你的表有主键:
CREATE TABLE user (
id BIGINT PRIMARY KEY,
name VARCHAR(20)
);
一般就不需要 DB_ROW_ID 作为聚簇索引键.
简单理解
这三个字段可以这样记:
DB_TRX_ID 记录是谁改的
DB_ROLL_PTR 记录改之前是什么
DB_ROW_ID 没有主键时用来唯一标识一行
和 MVCC 的关系
真正和 MVCC 强相关的是这两个:
DB_TRX_ID
DB_ROLL_PTR
它们配合 Read View 和 undo log,实现:
读不加锁
读写不阻塞
可以读到符合当前事务视图的历史版本
DB_ROW_ID 更多是 InnoDB 组织聚簇索引时使用的隐藏主键,不是 MVCC 判断可见性的核心字段.
假设测试表结构是
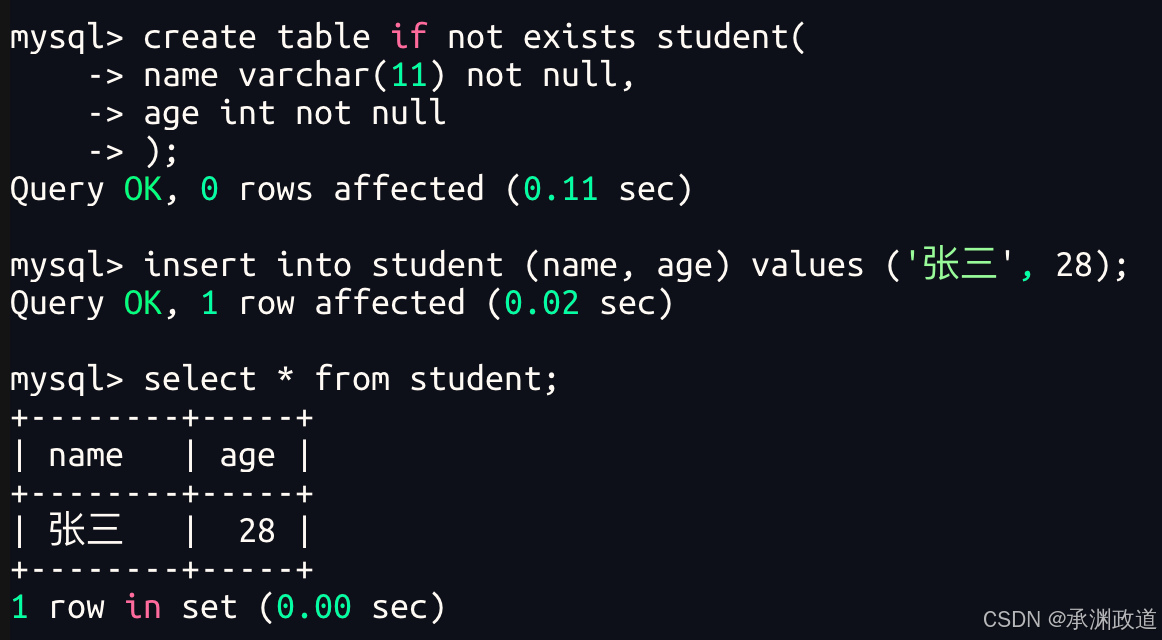
上面描述的意思是:
| name | age | DB_TRX_ID(创建该记录的事务ID) | DB_ROW_ID(隐藏主键) | DB_ROLL_PTR(回滚指针) |
|---|---|---|---|---|
| 张三 | 28 | null | 1 | null |
我们目前并不知道创建该记录的事务ID,隐式主键,我们就默认设置成null,1.第一条记录也没有其他版本,我们设置回滚指针为null.
2.2undo日志
undo log(回滚日志) 是 InnoDB 用来保存数据修改前旧版本的日志.MySQL 将来是以服务进程的方式,在内存中运行.我们之前所讲的所有机制:索引,事务,隔离性,日志等,都是在内存中完成的,即在 MySQL 内部的相关缓冲区中,保存相关数据,完成各种判断操作.然后在合适的时候,将相关数据刷新到磁盘当中的.所以,我们这里理解undo log,简单理解成,就是MySQL中的一段内存缓冲区,用来保存日志数据的就行.
它主要有两个作用:
- 事务回滚
- MVCC 多版本并发控制
1.undo log 用来回滚事务
假设原始数据是:
| name | age | DB_TRX_ID | DB_ROW_ID | DB_ROLL_PTR |
|---|---:|---|---:|---|
| 张三 | 28 | null | 1 | null |
事务 100 执行更新:
UPDATE user SET age = 30 WHERE name = '张三';
更新后,当前记录变成:
| name | age | DB_TRX_ID | DB_ROW_ID | DB_ROLL_PTR |
|---|---:|---|---:|---|
| 张三 | 30 | 100 | 1 | 指向 undo log |
同时,undo log 中会保存旧版本:
| name | age | DB_TRX_ID | DB_ROW_ID | DB_ROLL_PTR |
|---|---:|---|---:|---|
| 张三 | 28 | null | 1 | null |
如果事务 100 回滚,InnoDB 就可以根据 undo log 把数据恢复成:
| name | age |
|---|---:|
| 张三 | 28 |
2.undo log 用来实现 MVCC
当一条记录被多次修改时,InnoDB 会通过 DB_ROLL_PTR 把多个 undo log 串起来,形成版本链.
例如:
当前记录:age = 35,DB_TRX_ID = 300
↓ DB_ROLL_PTR
旧版本:age = 30,DB_TRX_ID = 200
↓ DB_ROLL_PTR
更旧版本:age = 28,DB_TRX_ID = 100
也可以写成:
| 版本 | age | DB_TRX_ID | DB_ROLL_PTR |
|---|---:|---:|---|
| 当前记录 | 35 | 300 | 指向 age=30 的 undo log |
| undo log 1 | 30 | 200 | 指向 age=28 的 undo log |
| undo log 2 | 28 | 100 | null |
当事务读取数据时,不一定读取最新版本,而是根据 Read View 判断哪个版本对当前事务可见.
3.undo log 和隐藏字段的关系
| 字段 | 作用 |
|---|---|
DB_TRX_ID | 记录最后一次修改该行的事务 ID |
DB_ROLL_PTR | 指向 undo log 中的上一个版本 |
DB_ROW_ID | 没有主键时生成的隐藏主键 |
其中,和 undo log 最直接相关的是:
DB_ROLL_PTR
它负责把当前记录和历史版本连接起来.
总结
undo log 保存的是数据被修改前的旧版本。
它的核心作用是:
事务回滚:修改错了,可以恢复旧值
MVCC:普通查询可以读取历史版本,实现读写不阻塞
一句话理解:
undo log = 旧版本数据 + 回滚依据 + MVCC 版本链基础
2.3模拟MVCC
现在有一个事务10(仅仅为了好区分),对student表中记录进行修改(update):将name(张三)改成name(李四).
(1)事务10,因为要修改,所以要先给该记录加行锁.
(2)修改前,现将改行记录拷贝到undo log中,所以,undo log中就有了一行副本数据.(原理就是写
时拷贝)
(3)所以现在 MySQL 中有两行同样的记录.现在修改原始记录中的name,改成’李四’.并且修改原始记录的隐藏字段DB_TRX_ID 为当前事务10 的ID,我们默认从10开始,之后递增.而原始记录的回滚指针DB_ROLL_PTR 列,里面写入undo log中副本数据的地址,从而指向副本记录,既表示我的上一个版本就是它.
(4)事务10提交,释放锁.

备注:此时,最新的记录是’李四‘那条记录.
现在又有一个事务11,对student表中记录进行修改(update):将age(28)改成age(38).
(1)事务11,因为也要修改,所以要先给该记录加行锁.(该记录是哪条?)
(2)修改前,现将改行记录拷贝到undo log中,所以,undo log中就又有了一行副本数据.此时,新的
副本,我们采用头插方式,插入undo log.
(3)现在修改原始记录中的age,改成38.并且修改原始记录的隐藏字段 DB_TRX_ID 为当前 事务11 的ID.而原始记录的回滚指针 DB_ROLL_PTR 列,里面写入undo log中副本数据的地址,从而指向副本记录,既表示我的上一个版本就是它.
(4)事务11提交,释放锁.
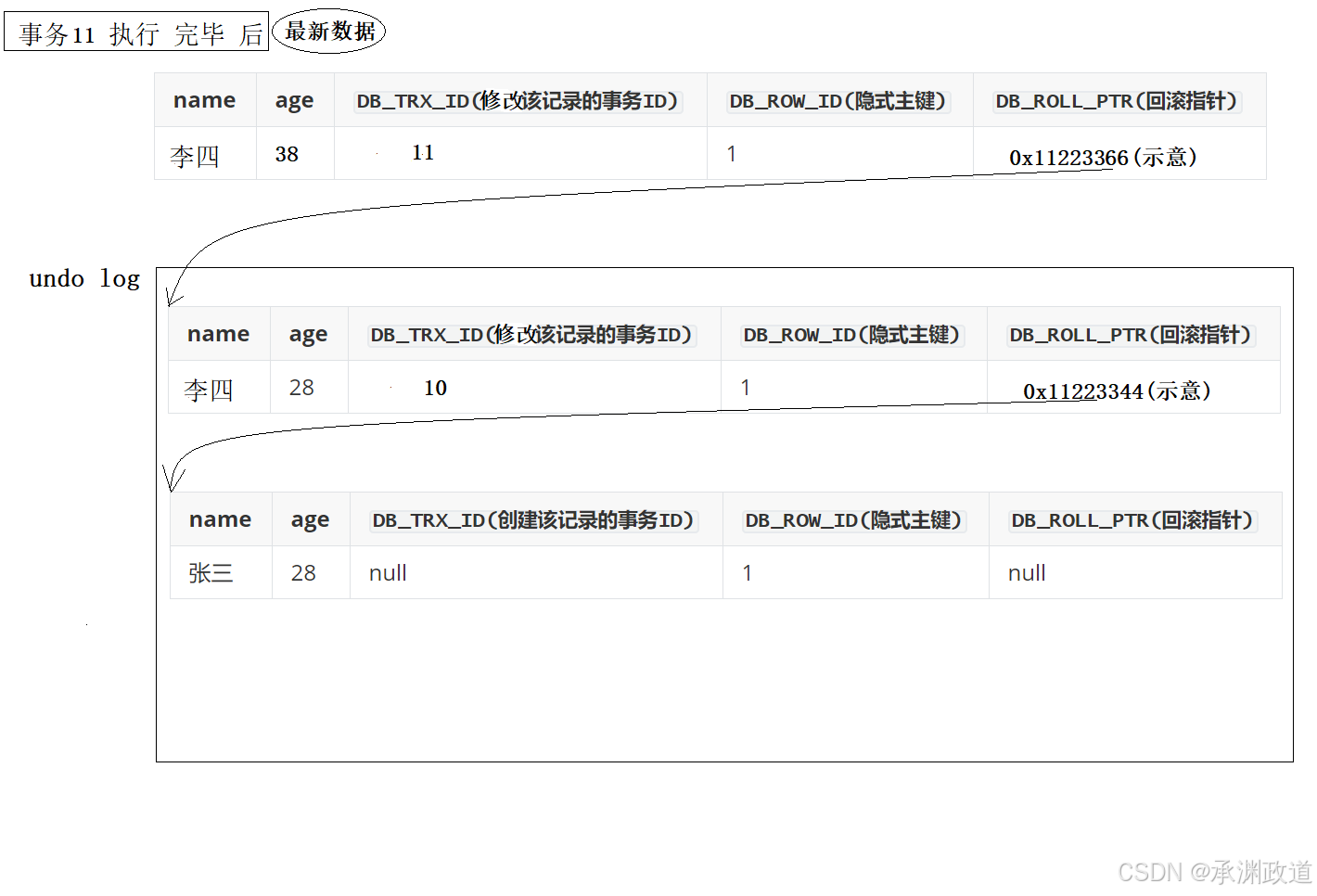
这样,我们就有了一个基于链表记录的历史版本链.所谓的回滚,无非就是用历史数据,覆盖当前数据.上面的一个一个版本,我们可以称之为一个一个的快照.
思考一些问题
上面是以更新(upadte)主讲的,如果是delete呢?一样的,别忘了,删数据不是清空,而是设置flag为删除即可.也可以形成版本.
如果是insert呢?因为insert是插入,也就是之前没有数据,那么insert也就没有历史版本.但是一般为了回滚操作,insert的数据也是要被放入undo log中,如果当前事务commit了,那么这个undo log 的历史insert记录就可以被清空了.
总结一下,也就是我们可以理解成,update和delete可以形成版本链,insert暂时不考虑.
那么select呢?
首先,select不会对数据做任何修改,所以,为select维护多版本,没有意义.不过,此时有个问题,就是:
select读取,是读取最新的版本呢?还是读取历史版本?
当前读:读取最新的记录,就是当前读.增删改,都叫做当前读,select也有可能当前读,比如:select lock in share mode(共享锁),select for update(这个好理解,我们后面不讨论).
快照读:读取历史版本(一般而言),就叫做快照读.(这个我们后面重点讨论)
我们可以看到,在多个事务同时删改查的时候,都是当前读,是要加锁的.那同时有select过来,如果也要读取最新版(当前读),那么也就需要加锁,这就是串行化.
但如果是快照读,读取历史版本的话,是不受加锁限制的.也就是可以并行执行!换言之,提高了效率,即MVCC的意义所在.
那么,是什么决定了,select是当前读,还是快照读呢?隔离级别!
那为什么要有隔离级别呢?
事务都是原子的.所以,无论如何,事务总有先有后.
但是经过上面的操作我们发现,事务从begin->CURD->commit,是有一个阶段的.也就是事务有执行前,执行中,执行后的阶段.但,不管怎么启动多个事务,总是有先有后的.
那么多个事务在执行中,CURD操作是会交织在一起的.那么,为了保证事务的"有先有后",是不是应该让不同的事务看到它该看到的内容,这就是所谓的隔离性与隔离级别要解决的问题.
先来的事务,应不应该看到后来的事务所做的修改呢?
那么,如何保证,不同的事务,看到不同的内容呢?也就是如何实现隔离级别?
快照读靠 MVCC 实现隔离级别,当前读靠锁实现隔离级别
2.4Read View
Read View 是 InnoDB 在快照读时生成的一份"事务可见性视图".
它的作用是判断:
当前事务能不能看到某个版本的数据?
也就是说,Read View 决定了:
哪些事务的修改对我可见
哪些事务的修改对我不可见
Read View就是事务进行快照读操作的时候生产的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID(当每个事务开启时,都会被分配一个ID,这个ID是递增的,所以最新的事务,ID值越大)
Read View 在 MySQL 源码中,就是一个类,本质是用来进行可见性判断的.即当我们某个事务执行快照读的时候,对该记录创建一个 Read View 读视图,把它比作条件,用来判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的 undo log 里面的某个版本的数据.
下面是 ReadView 结构,但为了减少大家负担,我们简化一下
class ReadView {
// 省略...
private:
/** 高水位,大于等于这个ID的事务均不可见*/
trx_id_t m_low_limit_id
/** 低水位:小于这个ID的事务均可见 */
trx_id_t m_up_limit_id;
/** 创建该 Read View 的事务ID*/
trx_id_t m_creator_trx_id;
/** 创建视图时的活跃事务id列表*/
ids_t m_ids;
/** 配合purge,标识该视图不需要小于m_low_limit_no的UNDO LOG,
* 如果其他视图也不需要,则可以删除小于m_low_limit_no的UNDO LOG*/
trx_id_t m_low_limit_no;
/** 标记视图是否被关闭*/
bool m_closed;
// 省略...
};
m_ids; //一张列表,用来维护Read View生成时刻,系统正活跃的事务ID
up_limit_id; //记录m_ids列表中事务ID最小的ID(没有写错)
low_limit_id; //ReadView生成时刻系统尚未分配的下一个事务ID,也就是目前已出现过的事务ID的
最大值+1(也没有写错)
creator_trx_id //创建该ReadView的事务ID
我们在实际读取数据版本链的时候,是能读取到每一个版本对应的事务ID的,即:当前记录的
DB_TRX_ID.那么,我们现在手里面有的东西就有,当前快照读的 ReadView 和 版本链中的某一个记录的DB_TRX_ID.所以现在的问题就是,当前快照读,应不应该读到当前版本记录.一张图,解决所有问题!
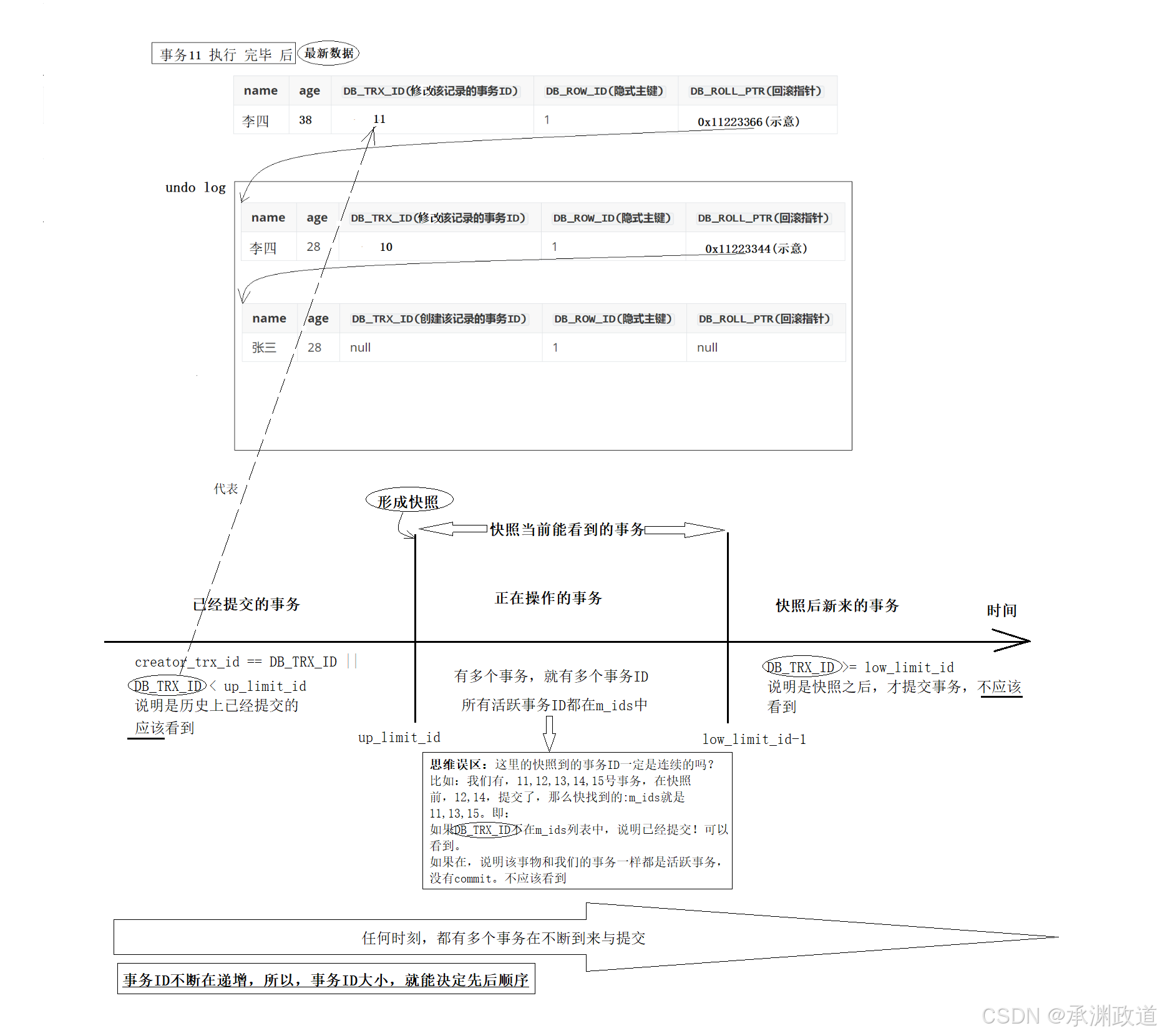
对应源码策略:

如果查到不应该看到当前版本,接下来就是遍历下一个版本,直到符合条件,即可以看到.上面的
readview 是当你进行select的时候,会自动形成.
2.5整体流程
假设当前有条记录:
| name | age | DB_TRX_ID(创建该记录的事务ID) | DB_ROW_ID(隐藏主键) | DB_ROLL_PTR(回滚指针) |
|---|---|---|---|---|
| 张三 | 28 | null | 1 | null |
事务操作:
| 事务1 [id=1] | 事务2 [id=2] | 事务3 [id=3] | 事务4 [id=4] |
|---|---|---|---|
| 事务开始 | 事务开始 | 事务开始 | 事务开始 |
| … | … | … | 修改且已提交 |
| 进行中 | 快照读 | 进行中 | |
| … | … | … |
事务4:修改name(张三) 变成name(李四)
当事务2对某行数据执行了快照读,数据库为该行数据生成一个 Read View 读视图
//事务2的 Read View
m_ids; // 1,3
up_limit_id; // 1
low_limit_id; // 4 + 1 = 5,原因:ReadView生成时刻,系统尚未分配的下一个事务ID
creator_trx_id // 2
此时版本链是:

只有事务4修改过该行记录,并在事务2执行快照读前,就提交了事务.

我们的事务2在快照读该行记录的时候,就会拿该行记录的 DB_TRX_ID 去跟up_limit_id,low_limit_id和活跃事务ID列表(trx_list) 进行比较,判断当前事务2能看到该记录的版本.
//事务2的 Read View
m_ids; // 1,3
up_limit_id; // 1
low_limit_id; // 4 + 1 = 5,原因:ReadView生成时刻,系统尚未分配的下一个事务ID
creator_trx_id // 2
//事务4提交的记录对应的事务ID
DB_TRX_ID=4
//比较步骤
DB_TRX_ID(4)< up_limit_id(1) ? 不小于,下一步
DB_TRX_ID(4)>= low_limit_id(5) ? 不大于,下一步
m_ids.contains(DB_TRX_ID) ? 不包含,说明,事务4不在当前的活跃事务中。
//结论
故,事务4的更改,应该看到。
所以事务2能读到的最新数据记录是事务4所提交的版本,而事务4提交的版本也是全局角度上最新的版本
3.RR与RC
3.1当前读和快照读在RR级别下的区别
测试表:
设置RR模式下测试

重启终端
依旧用之前的表
插入一条记录,用来测试

测试用例1-表1:
| 事务A操作 | 事务A描述 | 事务B描述 | 事务B操作 |
|---|---|---|---|
begin | 开启事务 | 开启事务 | begin |
select * from user | 快照读(无影响)查询 | 快照读查询 | select * from user |
update user set age=18 where id=1; | 更新 age=18 | - | - |
commit | 提交事务 | - | - |
select 快照读,没有读到 age=18 | select * from user | ||
select lock in share mode 当前读,读到 age=18 | select * from user lock in share mode |
测试用例2-表2:
| 事务A操作 | 事务A描述 | 事务B描述 | 事务B操作 |
|---|---|---|---|
begin | 开启事务 | 开启事务 | begin |
select * from user | 快照读,查到 age=18 | - | - |
update user set age=28 where id=1; | 更新 age=28 | - | - |
commit | 提交事务 | - | - |
select 快照读 age=28 | select * from user | ||
select lock in share mode 当前读 age=28 | select * from user lock in share mode |
用例1与用例2:唯一区别仅仅是表1的事务B在事务A修改age前快照读过一次age数据,而表2的事务B在事务A修改age前没有进行过快照读.
结论:
事务中快照读的结果是非常依赖该事务首次出现快照读的地方,即某个事务中首次出现快照读,决定该事务后续快照读结果的能力,delete同样如此.
3.2RR与RC的本质区别
一句话:
RC:每次 SELECT 都重新生成 Read View。
RR:事务内第一次 SELECT 生成 Read View,后续复用同一个 Read View。
所以它们的本质区别是:
Read View 的生成时机不同。
1.RC:Read Committed,读已提交
RC 的规则是:
每次快照读,都生成一个新的 Read View。
所以事务中多次查询,可能读到不同结果.
示例
假设初始数据:
| name | age |
|---|---:|
| 张三 | 28 |
事务执行过程:
| 时间 | 事务1 | 事务2 |
|---|---|---|
| 1 | begin | begin |
| 2 | select age,读到 28 | |
| 3 | | update age = 30 |
| 4 | | commit |
| 5 | select age,读到 30 | |
在RC下,事务1两次查询结果不同:
第一次读:28
第二次读:30
因为第二次 SELECT 会重新生成 Read View,此时事务2已经提交,所以事务1可以看到事务2的修改.
这就是:
不可重复读
2.RR:Repeatable Read,可重复读
RR 的规则是:
事务内第一次快照读生成 Read View,后续快照读复用同一个 Read View。
所以同一个事务中,多次查询看到的数据版本一致.
示例
还是同样的数据:
| name | age |
|---|---:|
| 张三 | 28 |
事务执行过程:
| 时间 | 事务1 | 事务2 |
|---|---|---|
| 1 | begin | begin |
| 2 | select age,读到 28,并生成 Read View | |
| 3 | | update age = 30 |
| 4 | | commit |
| 5 | select age,仍然读到 28 | |
在RR下,事务1 两次查询结果一致:
第一次读:28
第二次读:28
因为事务1复用第一次查询时的 Read View.哪怕事务2后来提交了,在事务1原来的视图里,事务2的修改仍然不可见.
这就是:
可重复读
3.对比总结
| 对比点 | RC | RR |
|---|---|---|
| 全称 | Read Committed | Repeatable Read |
| 中文 | 读已提交 | 可重复读 |
| Read View 生成时机 | 每次快照读都生成新的 Read View | 第一次快照读生成,事务内复用 |
| 同一事务多次 SELECT | 可能读到不同结果 | 结果保持一致 |
| 是否会不可重复读 | 可能会 | 不会 |
| 看到的数据 | 每次读时,最新已提交版本 | 第一次读时可见的版本 |
| 并发性 | 更高一些 | 隔离性更强 |
4.用一句话理解
RC 关注的是:我每次读,都只能读已经提交的数据。
RR 关注的是:我这个事务期间,多次读到的数据要一致。
所以:
RC 解决脏读,但不能解决不可重复读。
RR 解决脏读和不可重复读。
5.和 MVCC 的关系
RC 和 RR 都使用 MVCC,但使用方式不同:
RC:每次 SELECT 都创建新的 Read View。
RR:第一次 SELECT 创建 Read View,后续复用。
因此它们看到的数据不同。
核心可以压缩成:
RC = 每次读一个新快照
RR = 一个事务一个快照
不过更准确地说,RR 是:
事务内第一次快照读之后,共用同一个快照
因为如果事务 begin 之后一直没有执行普通 SELECT,Read View 通常不会立刻生成,而是在第一次快照读时生成.
4.读–读并发
读–读并发最简单:多个事务同时读取同一份数据,通常不会产生并发问题。
因为:
读操作不会修改数据
读操作之间不存在互相覆盖
所以读和读一般不需要互斥
4.1普通读–读:不会阻塞
例如事务 A 和事务 B 同时查询:
-- 事务A
SELECT * FROM user WHERE id = 1;
-- 事务B
SELECT * FROM user WHERE id = 1;
这种属于普通 SELECT,也就是快照读。
在 InnoDB 中,快照读依赖 MVCC:
事务A 读自己的 Read View
事务B 读自己的 Read View
两者互不影响
所以:
读不阻塞读
读不加锁
读之间可以并行
4.2读–读不会产生这些问题
| 问题 | 读–读是否会发生 | 原因 |
|---|---|---|
| 脏读 | 一般不会 | 没有写操作产生未提交数据 |
| 不可重复读 | 不会由读–读导致 | 必须有其他事务修改数据才会发生 |
| 幻读 | 不会由读–读导致 | 必须有插入、删除、更新才会发生 |
| 死锁 | 一般不会 | 普通读不加锁 |
| 丢失更新 | 不会 | 没有更新操作 |
4.3当前读–当前读呢?
如果是普通 SELECT,读–读没问题.
但如果是加锁读,例如:
SELECT * FROM user WHERE id = 1 LOCK IN SHARE MODE;
这是共享锁读.
多个事务都加共享锁时,也是兼容的:
共享锁 S 与共享锁 S 兼容
所以多个事务可以同时执行:
-- 事务A
SELECT * FROM user WHERE id = 1 LOCK IN SHARE MODE;
-- 事务B
SELECT * FROM user WHERE id = 1 LOCK IN SHARE MODE;
它们之间也不会阻塞.
4.4但是共享锁会阻塞写
注意:读–读没问题,但加锁读会影响写.
例如事务 A:
BEGIN;
SELECT * FROM user WHERE id = 1 LOCK IN SHARE MODE;
事务 B 此时执行:
UPDATE user SET age = 28 WHERE id = 1;
事务B可能会被阻塞.
因为:
共享锁 S 和排他锁 X 不兼容
也就是:
| 锁类型 | 共享锁 S | 排他锁 X |
|---|---|---|
| 共享锁 S | 兼容 | 不兼容 |
| 排他锁 X | 不兼容 | 不兼容 |
4.5总结
读–读场景可以这样记:
普通读--普通读:不加锁,不阻塞,靠 MVCC 并发读取。
共享锁读--共享锁读:可以并发,锁兼容。
读--读本身没有并发问题。
真正复杂的是读--写、写--写。
一句话:
读--读几乎不用特别处理,因为它不会修改数据,也不会互相影响。
5.写–写并发
写–写并发指的是:多个事务同时修改同一份数据.
结论先说:
MVCC 主要解决读--写并发;
写--写并发主要靠锁解决。
在 InnoDB 中,UPDATE、DELETE、INSERT 都属于当前读,需要操作最新版本的数据,并且会加锁.
5.1两个事务更新同一行
假设初始数据:
| id | name | age |
|---:|---|---:|
| 1 | 黄蓉 | 18 |
事务 A:
BEGIN;
UPDATE user
SET age = 28
WHERE id = 1;
事务 A 执行后,会对 id = 1 这行记录加 排他锁 X 锁.
此时事务 B 再执行:
BEGIN;
UPDATE user
SET age = 30
WHERE id = 1;
事务B会被阻塞.
因为:
事务 A 已经持有 id=1 这行的排他锁;
事务 B 也想修改 id=1;
两个写操作不能同时进行。
5.2执行过程
| 时间 | 事务A | 事务B | 结果 |
|---|---|---|---|
| 1 | BEGIN | | 事务A开始 |
| 2 | UPDATE user SET age=28 WHERE id=1; | | 事务A加 X 锁 |
| 3 | | BEGIN | 事务B开始 |
| 4 | | UPDATE user SET age=30 WHERE id=1; | 事务B阻塞等待 |
| 5 | COMMIT; | | 事务A释放锁 |
| 6 | | UPDATE 执行成功 | 事务B拿到锁,继续修改 |
| 7 | | COMMIT; | 最终 age=30 |
最终结果:
| id | name | age |
|---:|---|---:|
| 1 | 黄蓉 | 30 |
因为事务 B 是后执行成功的,它覆盖了事务 A 的结果.
5.3为什么写–写不能靠 MVCC?
因为写操作必须修改最新数据.
比如:
UPDATE user SET age = 30 WHERE id = 1;
它不能说:
我去修改一个历史版本。
这是不允许的.
写操作必须基于当前最新版本修改,所以需要加锁,保证同一时刻只有一个事务能修改这行数据.
所以:
快照读:可以读历史版本,靠 MVCC。
写操作:必须改最新版本,靠锁。
5.4写–写的锁兼容关系
| 锁类型 | 共享锁 S | 排他锁 X |
|---|---|---|
| 共享锁 S | 兼容 | 不兼容 |
| 排他锁 X | 不兼容 | 不兼容 |
写操作通常加的是 排他锁 X.
所以:
写--写:不兼容,会阻塞。
读锁--写锁:不兼容,会阻塞。
写锁--读锁:不兼容,会阻塞。
但是普通 SELECT 是快照读,一般不加锁,所以不受这个影响.
5.5不同写–写场景
5.5.1场景一:更新同一行
-- 事务A
UPDATE user SET age = 28 WHERE id = 1;
-- 事务B
UPDATE user SET age = 30 WHERE id = 1;
结果:
事务B等待事务A释放锁.
5.5.2场景二:更新不同行
-- 事务A
UPDATE user SET age = 28 WHERE id = 1;
-- 事务B
UPDATE user SET age = 30 WHERE id = 2;
如果 id 是主键或有索引,一般不会互相阻塞.
因为它们锁的是不同记录.
5.5.3场景三:范围更新
UPDATE user
SET age = age + 1
WHERE age BETWEEN 18 AND 30;
这种可能锁住一批记录,甚至在 RR 隔离级别下产生间隙锁、临键锁.
所以范围更新比单行主键更新更容易造成阻塞.
5.6写–写容易出现的问题
5.6.1阻塞
一个事务持有锁不提交,另一个事务只能等.
-- 事务A
BEGIN;
UPDATE user SET age = 28 WHERE id = 1;
-- 不提交
此时事务 B:
UPDATE user SET age = 30 WHERE id = 1;
会一直等待,直到事务 A:
COMMIT;
或者:
ROLLBACK;
5.6.2死锁
典型死锁场景:
| 时间 | 事务A | 事务B |
|---|---|---|
| 1 | UPDATE user SET age=28 WHERE id=1; | |
| 2 | | UPDATE user SET age=30 WHERE id=2; |
| 3 | UPDATE user SET age=28 WHERE id=2; | 等事务B释放 id=2 |
| 4 | | UPDATE user SET age=30 WHERE id=1; 等事务A释放 id=1 |
结果:
事务A等事务B;
事务B等事务A;
形成死锁。
InnoDB 会检测死锁,然后回滚其中一个事务.
5.6.3丢失更新
如果业务层先查再改,可能出现丢失更新.
错误示例:
事务A 查到 age=18
事务B 查到 age=18
事务A 改成 28 并提交
事务B 改成 30 并提交
事务A 的修改被事务B覆盖
这种业务上就叫丢失更新.
数据库层面虽然用锁保证了物理写入不会同时发生,但业务语义上,前一个修改可能被后一个覆盖.
5.7如何解决写–写并发问题?
5.7.1推荐1:直接原子更新
比如余额扣减、库存扣减,不要先查再改.
推荐:
UPDATE account
SET blance = blance - 10
WHERE id = 1 AND blance >= 10;
然后判断影响行数:
影响行数 = 1:扣减成功
影响行数 = 0:余额不足
5.7.2推荐2:乐观锁版本号
适合多人编辑同一条数据.
表里加一个版本号:
ALTER TABLE user ADD COLUMN version INT NOT NULL DEFAULT 0;
更新时:
UPDATE user
SET age = 28,
version = version + 1
WHERE id = 1
AND version = 0;
如果影响行数是 0,说明数据已经被别人改过.
5.7.3推荐3:固定加锁顺序,避免死锁
比如多个事务都要修改 id=1 和 id=2,统一按 id 从小到大修改:
UPDATE user SET age = 28 WHERE id = 1;
UPDATE user SET age = 30 WHERE id = 2;
不要一个事务先改 1 再改 2,另一个事务先改 2 再改 1.
5.7.4推荐4:事务尽量短
不要这样:
BEGIN;
UPDATE user SET age = 28 WHERE id = 1;
-- 中间:
```sql
BEGIN;
UPDATE user SET age = 28 WHERE id = 1;
-- 中间做复杂业务、调用接口、等待用户输入
COMMIT;
事务越长,锁持有时间越久,并发性能越差.
5.7.5总结
写–写并发的核心是:
写操作必须修改最新版本,所以不能靠快照读解决。
InnoDB 的处理方式是:
UPDATE / DELETE / INSERT 会加锁;
同一行的写--写操作互斥;
后来的事务必须等待前面的事务提交或回滚。
一句话记忆:
读--读:基本没问题
读--写:MVCC 解决
写--写:锁解决
最重要的实践是:
同一行并发修改,用行锁保证互斥;
业务防覆盖,用条件更新或乐观锁;
高并发扣减,用原子 UPDATE;
多行更新,统一加锁顺序避免死锁。
6.推荐阅读
1.详细分析MySQL事务日志(redo log和undo log):
https://www.cnblogs.com/f-ck-need-u/p/9010872.html
2.【MySQL】InnoDB 如何避免脏读和不可重复读:https://blog.csdn.net/chenghan_yang/article/details/97630626
3.【MySQL笔记】正确的理解MySQL的MVCC及实现原理:https://blog.csdn.net/SnailMann/article/details/94724197

敬请期待下一篇文章内容
每日心灵鸡汤: 真正拉开差距的,是逼近问题本质的能力!
真正拉开人生差距的,不是信息、学历或努力本身,而是独立且深度思考问题的能力.很多人面对问题只停留在"怎么办",少数人会追问"为什么会这样",更少的人会继续往下探,直到看见背后的结构、规则与机制.表面看差异只是思考深浅,但本质是信息处理方式的不同:信息早已过剩,真正稀缺的是对信息进行拆解与重组的能力.深度思考并不是想得更多,而是拒绝直接接受结论、持续追问原因,并最终穿透表层问题进入系统层理解.普通人在解决问题,高手在理解问题如何被制造;前者修补结果,后者改变规则.因此,差距的核心不在于做了多少事,而在于你是在重复同类问题,还是在不断逼近问题的本质.

转载自 CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2401_87629362/article/details/162442441

